Linux 应用技术基础 ¶
约 2933 个字 415 行代码 预计阅读时间 17 分钟
Linux 简介 ¶
linux 通常在指的是linux 内核
分为四个部分:内核、GNU 工具、图形化桌面环境、应用软件
类 UNIX 的操作系统
fedora core 9 、linux kernel
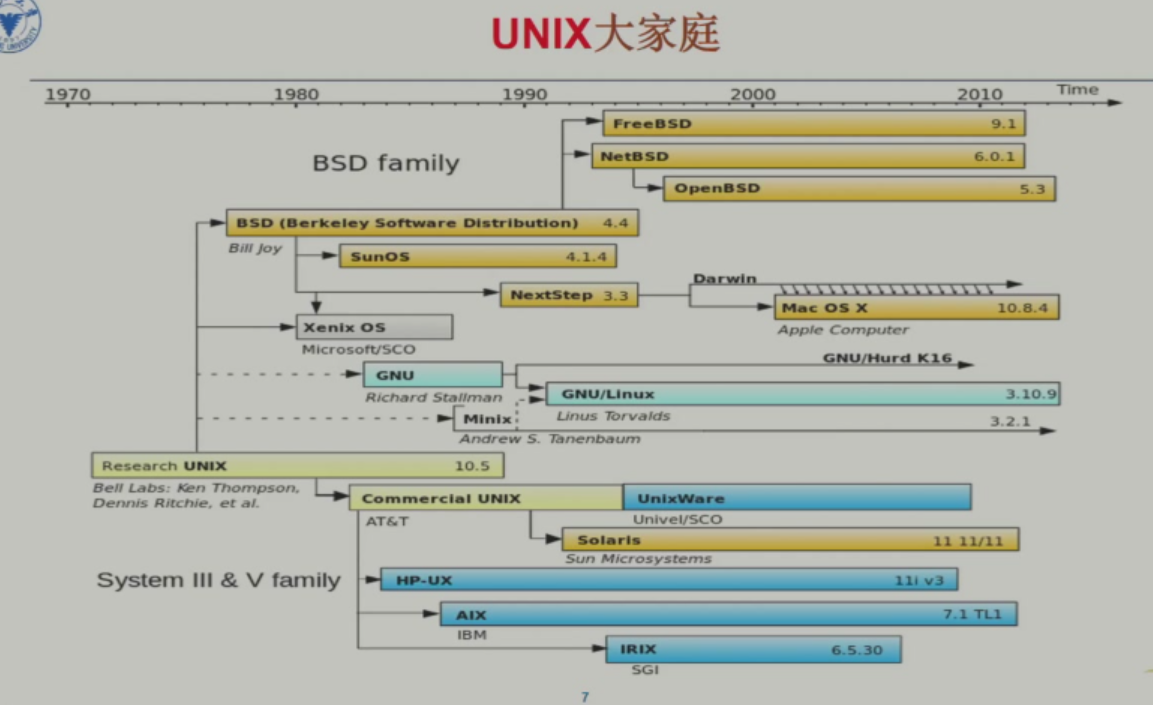
- 1984 年,Richard Stallman 提出 GNU Project 与 Unix 完全兼容
- 自由软件基金会 FSF 指定共用版权协议 GPL
自由软件 ¶
- 有自由按照自己的意愿运行该软件;
- 有自由复制软件并将其送给您的朋友和同事;
- 有自由通过对源代码的完全控制而改进程序;
- 有自由发布改进的版本从而帮助社区建设
。 (如果您再发布 GNU 软件,您可以为发布拷贝过程中的物理行为收取一定的费用,您也可以赠送拷贝。 )
Linux 版本 ¶
- 内核版本
-
发行版本

Linux 学习系列一:Linux 的简单介绍以及命令行的基本操作 _ 奋斗的西瓜瓜的博客 -CSDN 博客


- GUI 图形用户界面
-
常用 命令
多命令同时运行
| 命令
- 开关机
Linux 中 shutdown,halt,poweroff,init 0 区别 - 知乎 (zhihu.com)
文件与目录 ¶
用户权限 ¶
-
UID
- 500~65535 普通用户
- 0 超级用户
- PID process identification
- useradd
- 文件分类
p表示命名管道文件
d 表示目录文件
l 表示符号连接文件
- 表示普通文件
s 表示 socket 文件
c 表示字符设备文件
b 表示块设备文件
-
特殊访问位置
linux 一文带你彻底搞懂特殊权限位 suid,sgid,sticky_ 大雷编程的博客 -CSDN 博客 _suid 位
通过有效用户标识实现
SUID : set-user-ID
拥有用户的权限
chmod u+s XXX
SGID : set-group-ID
拥有组权限
chmod g+s XXX
chmod 2777 XXX
uname 可显示电脑以及操作系统的相关信息。
-a或--all 显示全部的信息。 -m或--machine 显示电脑类型。 -n或--nodename 显示在网络上的主机名称。 -r或--release 显示操作系统的发行编号。 -s或--sysname 显示操作系统名称。 -v 显示操作系统的版本。 --help 显示帮助。 --version 显示版本信息sticky BIt: 只有所有者可以删除或者重命名、在共享文档中使用
可以修改、不能删除
chmod 1755 XXX
chmod +t XXX
文件和目录操作权限不同:
对于目录来说,read 权限是读取 list,write 是更改文件名字、移动、删除等等
execute 权限是 search 权限,也就是是否可以 access
-
用户 用户组
user = u = 用户
group = g = 用户组
others = o = 其他人
r = read w = write x = execute 可执行
没有则用 ‘-’ 替代
顺序 u -> g -> o
- chgrp = change group
- chown = change owner
-
chmod =
r = 4 , w = 2 , x = 1
rwx = 7, rw = 6
-
chattr
chattr +i XXX防止删除
目录处理 ¶
~ home directory
-
ls -list\
ls - d #列出目录本身 ls -a(all) -l (long) -i(inode号) -d(属性) ls -h -d 列出目录本身 -R 目录树 -F 所有文件(包括隐藏文件) :-a 文件打印以人类可以理解的格式输出 : -h 文件以最近访问顺序排序:-t 以彩色文本显示输出结果:--color=auto
-
mkdir = make directories
mkdir -p 递归创建 没有这个目录就创建一个目录
- rmdir = remove directory
-
cd = change directory
cd - cd to the directory you previously in
- fasd: 快速跳转
alias a='fasd -a' # any
alias s='fasd -si' # show / search / select
alias d='fasd -d' # directory
alias f='fasd -f' # file
alias sd='fasd -sid' # interactive directory selection
alias sf='fasd -sif' # interactive file selection
alias z='fasd_cd -d' # cd, same functionality as j in autojump
alias zz='fasd_cd -d -i' # cd with interactive selection
a foo 列出最近操作的路径匹配'foo'的文件与目录
f foo 列出最近操作的路径匹配'foo'的文件
d foo 列出最近操作的路径匹配'foo'的目录
s foo 列出最近操作的路径匹配'foo'的文件与目录,并可以通过序号选择
sf foo 列出最近操作的路径匹配'foo'的文件,并可以通过序号选择
sd foo 列出最近操作的路径匹配'foo'的目录,并可以通过序号选择
z foo cd到最近操作的匹配'foo'并且得分最高的目录
zz foo 列出最近操作的路径匹配'foo'的目录,通过序号选择,然后cd进目录
- pwd = print working directory
- cp = copy cp -rp -r -p 保留属性
- mv = move
-
rm = remove
rm -i 先询问再删除 // 询问是否删除
rm - rf 文件或目录
-r 目录(非常危险)
- echo 打印
文件夹导航 ¶
- fasd
基于 frecency 对文件和文件排序,也就是说它会同时针对频率(frequency)和时效(recency)进行排序。默认情况下,fasd使用命令 z 帮助我们快速切换到最常访问的目录。
例如, 如果您经常访问/home/user/files/cool_project 目录,那么可以直接使用 z cool 跳转到该目录
- autojump
- tree
- nnn
文件处理 ¶
编码形式存储 - 文本文件
二进制存储 - 二进制文件
- xdg-open : 自动寻找合适方式打开文件,相当于鼠标双击
- convert 转换文件格式
convert a.{jpg,png}
convert a.jpg a.png
- touch 建立空文件
- cat 显示文件内容 -n 显示行号
- tac 倒着输出(cat 反着来
- more 分页显示 [ 空格 翻页; enter 换行 q 退出
- less 分页显示 q 退出
- head 显示前面几行 -n 指定行数
- tail 后面几行 -n z 指定行数
- file 查看文件类型
ln 链接 ¶
硬链接和符号链接的区别 - LubinLew - 博客园 (cnblogs.com)
- 硬链接
不可跨越文件系统
只有超级用户才可以建立目录硬链接
占用空间极少
- 符号链接
文件内容作为路径名去访问真正的共享文件
可跨越文件系统
占有少量空间
[root@localhost ~]# touch cangls
[root@localhost ~]# ln /root/cangls /tmp
\#建立硬链接文件,目标文件没有写文件名,会和原名一致
\#也就是/tmp/cangls 是硬链接文件
-
-s:建立软链接文件。如果不加 "-s" 选项,则建立硬链接文件;
符号链接:inode 号不同
- -f:强制。如果目标文件已经存在,则删除目标文件后再建立链接文件
查找文件 ¶
- which 查询脚本文件 -a 全列出来
-
find
- atime = access time
- ctime = status time
- mtime = modification time
【-mtime n 几天之前的“一天之内
】 【-mtime +n n 天之前】 【-mtime -n n 天之内】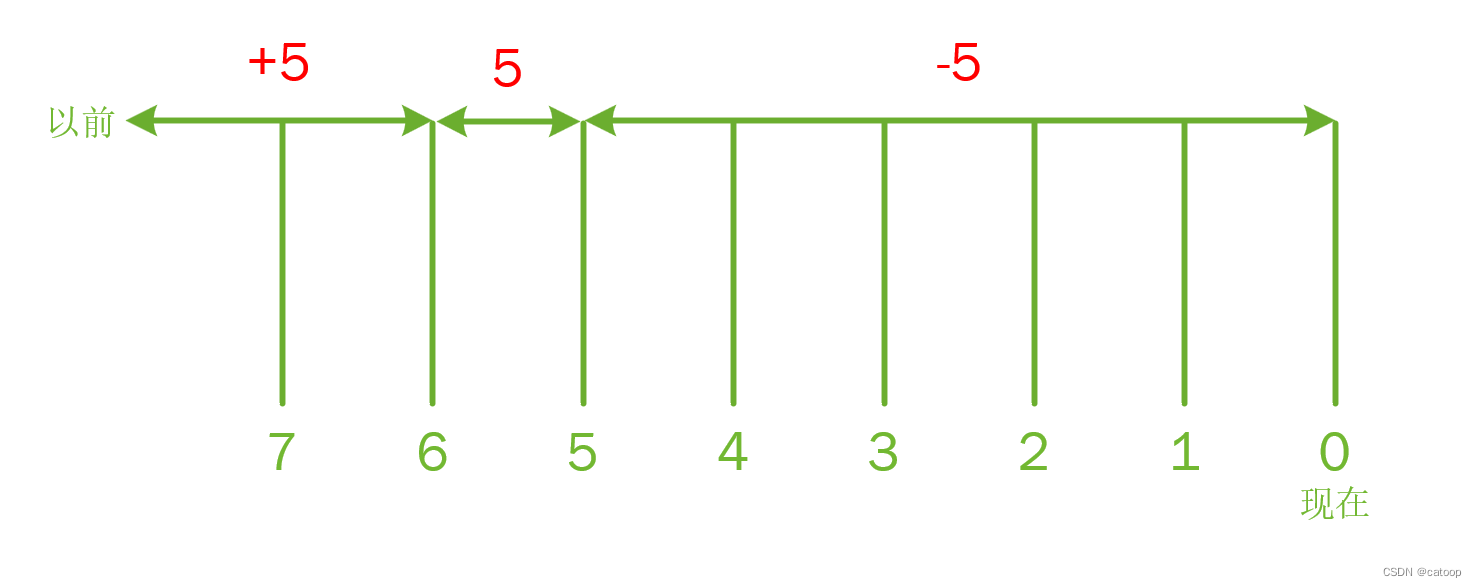
# 查找所有名称为src的文件夹 find . -name src -type d # 查找所有文件夹路径中包含test的python文件 find . -path '**/test/*.py' -type f # ** 表示所有 # 查找前一天修改的所有文件 find . -mtime -1 # 查找所有大小在500k至10M的tar.gz文件 find . -size +500k -size -10M -name '*.tar.gz' # 删除全部扩展名为.tmp 的文件 find . -name '*.tmp' -exec rm {} \; # 查找全部的 PNG 文件并将其转换为 JPG find . -name '*.png' -exec convert {} {}.jpg \; # 文件名中有空格 -print 打印 find命令 结果集,默认用换行符分割。而且 -print 是默认省略的。 -print0 打印 find命令 结果集,用 NULL 字符 ('\0')分割,而不是换行符。 # 编写一个命令或脚本递归的查找文件夹中最近使用的文件。更通用的做法,你可以按照最近的使用时间列出文件吗? find . -type f -print0 | xargs -0 ls -lt | head -1 当文件数量较多时,上面的解答会得出错误结果,解决办法是增加 -mmin 条件,先将最近修改的文件进行初步筛选再交给ls进行排序显示 find . -type f -mmin -60 -print0 | xargs -0 ls -lt | head -10find+exec
# ls -l命令放在find命令的-exec选项中 find . -type f -exec ls -l {} \; # 在目录中查找更改时间在n日以前的文件并删除它们 find . -type f -mtime +14 -exec rm {} \; 在shell中用任何方式删除文件之前,应当先查看相应的文件,一定要小心!当使用诸如mv或rm命令时,可以使用-exec选项的安全模式。它将在对每个匹配到的文件进行操作之前提示你。 #3 在目录中查找更改时间在n日以前的文件并删除它们,删除之前先给出提示 find . -name "*.log" -mtime +5 -ok rm {} \; 在上面的例子中, find命令在当前目录中查找所有文件名以.log结尾、更改时间在5日以上的文件,并删除它们,只不过在删除之前先给出提示。 按y键删除文件,按n键不删除。 #4 -exec中使用grep命令 find /etc -name "passwd*" -exec grep "root" {} \; 任何形式的命令都可以在-exec选项中使用。 在上面的例子中我们使用grep命令。find命令首先匹配所有文件名为“ passwd*”的文件,例如passwd、passwd.old、passwd.bak,然后执行grep命令看看在这些文件中是否存在一个root用户。 #5 查找文件移动到指定目录 find . -name "*.log" -exec mv {} .. \; #6 用exec选项执行cp命令 find . -name "*.log" -exec cp {} test3 \;
-
locate
-i 大小写
查找 shell 命令 ¶
- history
history N #数字 : 最近___条命令
history -c #删除历史
history -a #保存
history -r #读取
history !n #执行历史中的第n条命令
history !+ #命令 执行历史中这条命令开头的命令
!! #重新执行上一条命令
!N #重新执行第N条命令。比如 !3
!-N #重新执行倒数第N条命令。!-3
!string #重新执行以字符串打头的命令。 比如 !vim
!?string? #重新执行包含字符串的命令。 比如 !?test.cpp?
!?string?% #替换为: 最近包含这个字符串的命令的参数。比如: vim !?test.cpp?%
!$ #替换为:上一条命令的最后一个参数。比如 vim !$
!!string #在上一条命令的后面追加 string ,并执行。
!Nstring #在第N条指令后面追加string,并执行。
^old^new^ #对上一条指令进行替换
history N | grep find
CTRL + R 输入字串进行匹配
修改历史
你可以修改 shell history 的行为,例如,如果在命令的开头加上一个空格,它就不会被加进 shell 记录中。当你输入包含密码或是其他敏感信息的命令时会用到这一特性。 为此你需要在.bashrc中添加HISTCONTROL=ignorespace或者向.zshrc 添加 setopt HIST_IGNORE_SPACE。 如果你不小心忘了在前面加空格,可以通过编辑。bash_history或 .zhistory 来手动地从历史记录中移除那一项。
- fzf 通用对模糊查找工具
- zsh 基于历史的自动补全
压缩 ¶
- tar
# 压缩文件 非打包
$ touch a.c
$ tar -czvf test.tar.gz a.c //压缩 a.c文件为test.tar.gz
a.c
# 列出压缩文件内容
$ tar -tzvf test.tar.gz
-rw-r--r-- root/root 0 2010-05-24 16:51:59 a.c
#解压文件
$ tar -xzvf test.tar.gz
a.c
# 备份文件(tar默认只是打包不压缩,参数-z打包后进行gzip压缩,参数-j打包后进行bzip2压缩)
tar -cvf test.tar ./test # 得到test.tar备份文件
tar -zcvf test.tar.gz ./test # 得到test.tar.gz备份文件
tar -jcvf test.tar.bz2 ./test # 得到test.tar.bz2备份文件
# 查看备份文件中的文件
tar -tf test.tar # 只是列出文件
tar -tvf test.tar # 列出文件,包括文件信息
# 删除备份文件中的指定文件
tar -vf test.tar --delete ./a.txt
数据处理三剑客 ¶
过滤文本 grep ¶
-C :获取查找结果的上下文(Context
-v 将对结果进行反选(Invert
-R 会递归地进入子目录并搜索所有的文本文件。
通过 14 个实例彻底掌握 grep 命令 - 知乎 (zhihu.com)
## 在文件中搜索单词或字符串
$ sudo grep nobody /etc/passwd
## 多文件中的搜索模式
$ sudo grep linuxtechi /etc/passwd /etc/shadow /etc/gshadow
## 打印与模式匹配的文件名
假设我们想列出包含单词“root”的文件名,可以在 grep 命令中使用“-l”选项,后跟单词(模式)和文件。
$ grep -l 'root' /etc/fstab /etc/passwd /etc/mtab
## 显示带有行号的输出行
$ grep -n 'nobody' /etc/passwd
## 反转模式匹配
$ grep -v 'nobody' /etc/passwd
## 打印以特定字符开头的所有行
Bash Shell 将插入符号 “^” 视为特殊字符,用于标记行或单词的开头。
$ grep ^backup /etc/passwd
## 打印文件中的所有空行
$ grep '^$' /etc/sysctl.conf
$ grep -n '^$' /etc/sysctl.conf #打印空行行号
## 计算与模式匹配的行数
“-c” 选项用于计算与搜索模式匹配的行数。
假设我们要计算 /etc/password 文件中以 “false” 结尾的行数
$ grep -c false$ /etc/passwd
- ack,rg
# 查找所有使用了 requests 库的文件
rg -t py 'import requests'
# 查找所有没有写 shebang 的文件(包含隐藏文件)
rg -u --files-without-match "^#!"
# 查找所有的foo字符串,并打印其之后的5行
rg foo -A 5
# 打印匹配的统计信息(匹配的行和文件的数量)
rg --stats PATTERN
修改文本 sed ¶
处理文本 awk ¶
awk 主要是用来格式化
linux awk 命令详解 - ggjucheng - 博客园 (cnblogs.com)
awk 工作流程是这样的:先执行 BEGING,然后读取文件,读入有 /n 换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0 则表示所有域 ,$1 表示第一个域 ,$n 表示第 n 个域 , 随后开始执行模式所对应的动作 action。接着开始读入第二条记录 ······ 直到所有的记录都读完,最后执行 END 操作。
awk [参数] [处理内容] [操作对象]
$cat /etc/passwd | awk -F ':' '{print $1}'
root
daemon
bin
sys
$cat /etc/passwd | awk -F ':' '{print $1"\t"$7}'
root /bin/bash
daemon /bin/sh
bin /bin/sh
sys /bin/sh
#支持正则
$ awk -F: '/^root/' /etc/passwd
#内置变量
ARGC 命令行参数个数
ARGV 命令行参数排列
ENVIRON 支持队列中系统环境变量的使用
FILENAME awk浏览的文件名
FNR 浏览文件的记录数
FS 设置输入域分隔符,等价于命令行 -F选项
NF 浏览记录的域的个数
NR 已读的记录数
OFS 输出域分隔符
ORS 输出记录分隔符
RS 控制记录分隔符
排序 ¶
-
sort 文件排序
-d 字典序
-n 数值大小
-k + number 第几列排序
sort 可针对文本文件的内容,以行为单位来排序。
- uniq 删去重复行
-c或--count 在每列旁边显示该行重复出现的次数。
-d或--repeated 仅显示重复出现的行列。
-s<字符位置>或--skip-chars=<字符位置> 忽略比较指定的字符。
-u或--unique 仅显示出一次的行列。
uniq -c testfile
#统计各行在文件中出现的次数
$ sort testfile1 | uniq -c
3 Hello 95
3 Linux 85
3 test 30
#在文件中找出重复的行:
sort testfile1 | uniq -d
Hello 95
Linux 85
test 30
正则表达式 ¶
交互式正则表达式教程
.除换行符之外的”任意单个字符”*匹配前面字符零次或多次+匹配前面字符一次或多次[abc]匹配a,b和c中的任意一个(RX1|RX2)任何能够匹配RX1或RX2的结果^行首$行尾
*& +是贪婪模式,增加一个?变成非贪婪模式
\d 数字
[:alnum:] 0-9 , a-z , A-Z
[:alpha:] a-z , A-Z
[:upper:] A-Z
[:lower:] a-z
[:digit:] 0-9
字符转换命令 ¶
-
tr 文字删除 / 文字替换
-d 删除该字符串
last | tr '[a-z]' '[A-Z]'last | tr -d ':'删除冒号
- col
- join
- paste 两行贴贴,tab 分隔
- expand 把 tab 转换为空格 -t 转换为多少个空格
-
wc = word count 统计指定文件中的字节数、字数、行数
-c 统计字节数。 -l 统计行数。 -m 统计字符数。这个标志不能与 -c 标志一起使用。 -w 统计字数。一个字被定义为由空白、跳格或换行字符分隔的字符串。 -L 打印最长行的长度。 -help 显示帮助信息 --version 显示版本信息
文件系统 ¶
-
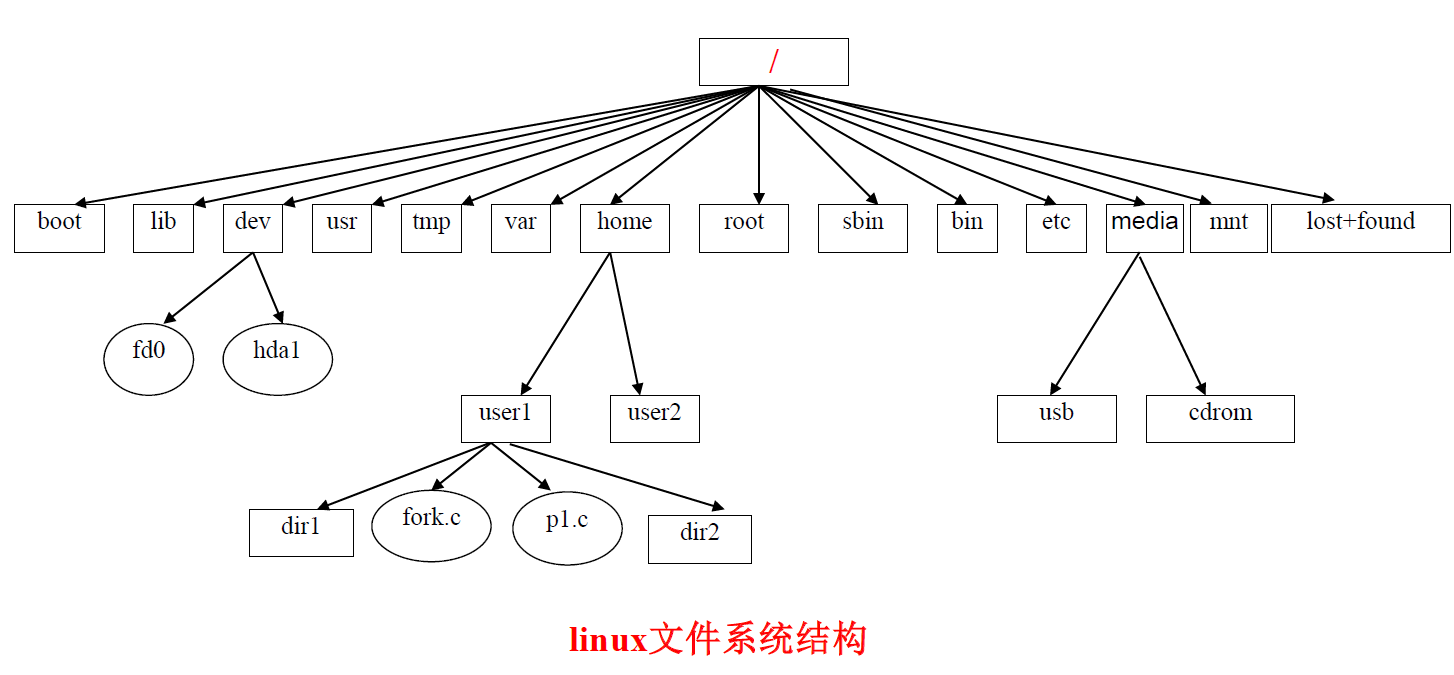
目录结构
-
主要目录


bin 可执行文件
sys 系统相关
root
usr 软件安装 在Linux系统中使用mount命令挂载后缀为.img的Ubuntu系统 - 3yude - 博客园
/etc/shadow用户口令的加密信息

相对路径 绝对路径
不支持
ext4 默认文件系统

shell 与 shell script ¶
bash 基础与配置 ¶
awesome-cheatsheets/languages/bash.sh at master · skywind3000/awesome-cheatsheets · GitHub
-
bash = Bourne Again Shell
bash 是命令解释程序,也是程序设计语言
- 功能:history 、 命令与文件补全 、 程序脚本 shell script 、 通配符 wildcard
- 程序头:脚本文件名、Author、Date、Description、

- 注释
多行注释
:<<num
num
- shebang
在 Shebang 之后,可以有一个或数个空白字符,后接解释器的绝对路径,用于指明执行这个脚本文件的解释器。在直接调用脚本时,系统的程序载入器会分析 Shebang 后的内容,将这些内容作为解释器指令,并调用该指令,将载有 Shebang 的文件路径作为该解释器的参数,执行脚本,从而使得脚本文件的调用方式与普通的可执行文件类似。
在 shebang 行中使用 env 命令是一种好的实践,它会利用环境变量中的程序来解析该脚本,这样就提高来您的脚本的可移植性。env 会利用我们第一节讲座中介绍过的PATH 环境变量来进行定位。
例如,使用了env的 shebang 看上去时这样的#!/usr/bin/env python。
- PS1 的自定义
linux 修改 PS1,自定义命令提示符样式 - 自我更新 - 博客园 (cnblogs.com)
SHELL¶
常用命令 ¶
通配 ¶
- 通配符 - 当你想要利用通配符进行匹配时,你可以分别使用
?和*来匹配一个或任意个字符。例如,对于文件foo,foo1,foo2,foo10和bar,rm foo?这条命令会删除foo1和foo2,而rm foo*则会删除除了bar之外的所有文件。
* 任意字符
?特定字符
[abcd]有括号内的任一字符
[0-9]连续
[^abc]只要非 abc 就可以
- 花括号
{}- 当你有一系列的指令,其中包含一段公共子串时,可以用花括号来自动展开这些命令。这在批量移动或转换文件时非常方便。
convert image.{png,jpg}
# 会展开为
convert image.png image.jpg
cp /project/{a,b,c}.sh /newpath
# 会展开为
cp /path/to/project/foo.sh /path/to/project/bar.sh /path/to/project/baz.sh /newpath
# 也可以结合通配使用
mv *{.py,.sh} folder
# 会移动所有 *.py 和 *.sh 文件
mkdir foo bar
# 下面命令会创建foo/a, foo/b, ... foo/h, bar/a, bar/b, ... bar/h这些文件
touch {foo,bar}/{a..h}
touch foo/x bar/y
# 比较文件夹 foo 和 bar 中包含文件的不同
diff <(ls foo) <(ls bar)
# 输出
# < x
# ---
# > y
- source 执行脚本
怎么执行?
字符串 ¶
#获取字符串长度
在${}中使用“#”获取长度
name="test";
echo ${#name}; # 输出为4
#拼接字符串
中间无任何+,之类的字符
name="this is"" my name"; name="this is my name"; name="this" is "my name" 等效
name='this is'' my nam'; name='this is my name'; name='this' is 'my name' 等效
#提取子字符串
1:4 从第2个开始 往后截取4个字符
::4 从第一个字符开始 往后截取4个字符
name="this is my name";
echo ${name:1:4} #输出 is i
echo ${name::4} #输出 this
### 进程
信号(Signal):信号是在软件层次上对中断机制的一种模拟,通过给一个进程发送信号,执行相应的处理函数。
| 2 | SIGINT | 终止 | 键盘输入中断命令,一般是 CTRL+C |
| 9 | SIGKILL | 终止 | 立即停止进程,不能捕获,不能忽略 |
| 20 | SIGSTP | 停止 | 停止进程,一般是 CTRL+Z |
-
type 类似于 which 找到执行文件
显示类型
内部命令、外部命令:内部命令不创建进程、外部命令创建进程
-
ps 查看进程属性
ps -a
-
前台后台
加&变成后台:大量计算、查找
fg = foreground 后台转到前台
bg = background + "% 作业号 "
-
作业、作业号
查看作业 jobs
定时执行 at
分号:顺序进行 与号:并发执行
-
终止进程
kill -9(强制)
-15 + 进程号
- 睡眠 sleep n
-
&& 成功则运行
|| 失败才运行
管道 ¶
管道是进程之间的通讯机制
经过几道手续之后再输出
tee¶
中间结果保存
cut¶
-d 后面接分割字符 -f 取出第几段的意思
-c 以字符的单位去除
【Linux 篇】cut 命令详解 _linux cut_ 傻啦猫 @_@ 的博客 -CSDN 博客
xargs¶
命令行可以从参数或标准输入接受输入。在用管道连接命令时,我们将标准输出和标准输入连接起来,但是有些命令,例如tar 则需要从参数接受输入。
xargs 默认的命令是 echo,这意味着通过管道传递给 xargs 的输入将会包含换行和空白,不过通过 xargs 的处理,换行和空白将被空格取代。
# 实例1
find /sbin -perm +700 |ls -l #这个命令是错误的
find /sbin -perm +700 |xargs ls -l #这样才是正确的
# -d 选项可以自定义一个定界符:
$ echo "nameXnameXnameXname" | xargs -dX
name name name name
# 结合 -n 选项使用:
$ echo "nameXnameXnameXname" | xargs -dX -n2
name name
name name
# xargs 结合 find 使用
用 rm 删除太多的文件时候,可能得到一个错误信息:/bin/rm Argument list too long. 用 xargs 去避免这个问题:
$ find . -type f -name "*.log" -print0 | xargs -0 rm -f
# 查找所有的 jpg 文件,并且压缩它们
find . -type f -name "*.jpg" -print | xargs tar -czvf images.tar.gz
# 很多你希望下载的 URL
$ cat url-list.txt | xargs wget -c
# find -print0 | xargs -0
分析:第一个 -print0 指定结果集分隔为 null,第二个 -0 指定 xargs 分隔为 null。
find -print0表示在find的每一个结果之后加一个NULL字符,而不是默认加一个换行符。find的默认在每一个结果后加一个'\n',所以输出结果是一行一行的。当使用了-print0之后,就变成一行了。
然后xargs -0表示xargs用NULL来作为分隔符。这样前后搭配就不会出现空格和换行符的错误了。选择NULL做分隔符,是因为一般编程语言把NULL作为字符串结束的标志,所以文件名不可能以NULL结尾,这样确保万无一失。
重定向 ¶
-
输出
stdout >> 累加 > 覆盖
stderr 2>> 累加 2> 覆盖
输出到同一个文件 2>&1
-
输入
stdin <
stdin << 结束输入 ex: <<"eof"

变量 ¶
-
单引号:所见即所得;双引号或者没有引号:会先解析变量;
- 命令串太长 反斜杠 + enter
-
echo 显示变量
echo $+变量名等号左右不能有空格、开头不能是数字、用转义特殊字符
unset 删除变量
-
env = environment 列出环境变量
- HOME
- SHELL
- PATH
- LANG 语系数据
-
RANDOM 随机数
-
declare Set variable values and attributes.
生成 0-9 的随机数
declare -i number=$RANMDOM*10/32768 ; echo $number
-
-
$ 本 SHELL 的线程代号 即 PID
ex echo $$ 即输出 proceesID
- ?上一个执行命令回传值
- PWD 当前工作目录
-
export 自定义变量变成环境变量
子进程继承父进程的环境变量
括号问题 ¶
- 双引号
不想让空格把变量分割开,有空格的变量视为一个变量
"$arg"
- 大括号
大括号 {} 的作用是限定大括号里面的字符串是一个整体,不会跟相邻的字符组合成其他含义。
$ var="Say"
$ echo $var Hello
Say Hello
$ echo $varHello
$ echo ${var}Hello
SayHello
$ echo "$var"Hello
SayHello
环境变量 ¶

0 表示正常执行,非零值表示有错误发生
$0- 脚本名
$1到$9- 脚本的参数。$1是第一个参数,依此类推。
$@- 所有参数
$#- 参数个数
$?- 前一个命令的返回值
$$- 当前脚本的进程识别码
!!- 完整的上一条命令,包括参数。常见应用:当你因为权限不足执行命令失败时,可以使用sudo !!再尝试一次。
$_- 上一条命令的最后一个参数。如果你正在使用的是交互式 shell,你可以通过按下Esc之后键入 . 来获取这个值。 (下划线) 表示的是打印上一个输入参数行, 当这个命令在开头时, 打印输出文档的绝对路径名.
- $- 是 set 命令的 –h 和 –B 的参数 , 表示使用内置的 set 命令扩展解释之后的参数行 , 具体分别表示为, 记住工作路径, 和允许使用 ! 历史扩展, 详细请参阅 set 命令.
变量读取、数组、声明 ¶
- read + 变量 -p 接提示符 -t 接时间
-
declare / typeset 声明变量类型
-a 定义为数组 -i 定义为 integer -x 与 export 一样
bash中数值运算仅支持整数
read -p "输入网站名:" website echo "你输入的网站名是 $website" exit 0
-
数组定义 没有逗号
a1=(0 1 1) echo=${a1[1]} //*和@获取所有元素 echo "数组的元素为: ${my_array[*]}" echo "数组的元素为: ${my_array[@]}" echo ${#array[1]} // 显示长度
关联数组
declare -A array_name
-
变量删除、替代、替换
-
删除
从前到后删除符合选项的最短字符
从前到后删除符合选项的最长字符
echo ${path#/*/kerberos/bin:}% 从后向前删除
%% 从后向前删除最长项数 z
-
替换
/ 旧 / 新 第一个
// 旧 / 新 全部
-
-
变量别名 alias
alias lm='ls -l | morealias rm='rm -i'Shell 运算符 ¶
- bc 数学运算
短路运算 ¶
|| or: 第一个没成功,执行第二个
&&
;: 不管是否成功都会执行
false || echo "Oops, fail"
# Oops, fail
true || echo "Will not be printed"
#
true && echo "Things went well"
# Things went well
false && echo "Will not be printed"
#
false ; echo "This will always run"
# This will always run
- eval
二次扫描
可以实现指针效果
``` bash
x=50
a=x
eval echo $$a
```
- set 命令
```bash
set $(date)
echo $1 $3
set -- $(ls -l $demo)
#--用来让后面的-不被识别成为set的参数
```
把set后的命令转换为$变量

expr
用反引号
- 计算运算符
a=10
b=20
val=`expr $a + $b`
echo "a + b : $val"
val=`expr $a - $b`
echo "a - b : $val"
val=`expr $a \* $b`
echo "a * b : $val"
val=`expr $b / $a`
echo "b / a : $val"
val=`expr $b % $a`
echo "b % a : $val"
if [ $a == $b ]
then
echo "a 等于 b"
fi
if [ $a != $b ]
then
echo "a 不等于 b"
fi
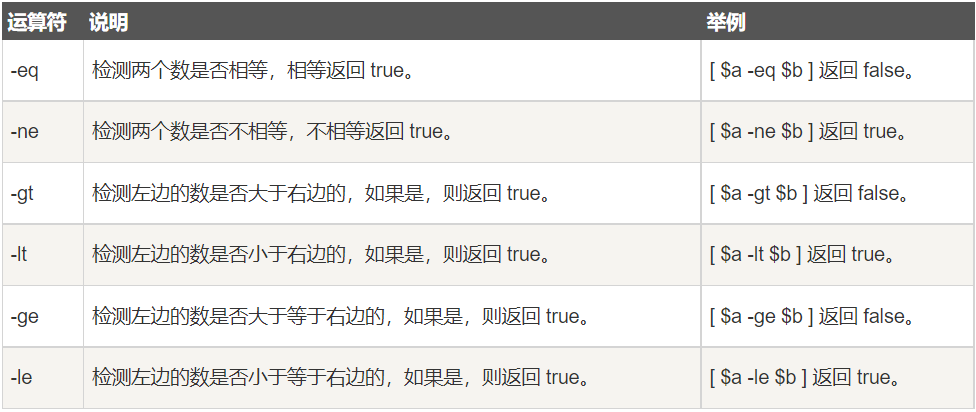
关系运算符 ¶
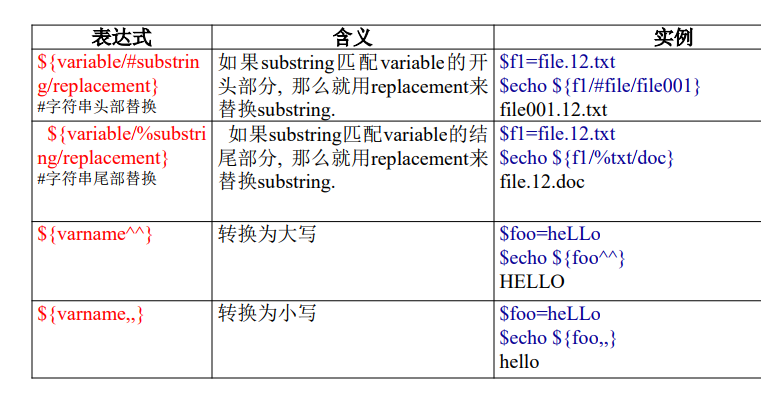
字符串运算符 ¶


test 命令 ¶
linux 应用之 test 命令详细解析 - madtank - 博客园 (cnblogs.com)
注意引号问题、注意加上$
1)判断表达式
if test ( 表达式为真 )
if test ! 表达式为假
test 表达式 1 –a 表达式 2 两个表达式都为真
test 表达式 1 –o 表达式 2 两个表达式有一个为真
2)判断字符串
test –n 字符串 |
字符串长度不 |
test –z 字符串 |
字符串的长度为零 |
test 字符串1=字符串2 |
字符串相等 |
test 字符串1!=字符串2 |
字符串不等 |
3)判断整数
test 整数 1 –eq 整数 2 整数相等
test 整数 1 –ge 整数 2 整数 1 大于等于整数 2
test 整数 1 –gt 整数 2 整数 1 大于整数 2
test 整数 1 –le 整数 2 整数 1 小于等于整数 2
test 整数 1 –lt 整数 2 整数 1 小于整数 2
test 整数 1 –ne 整数 2 整数 1 不等于整数 2
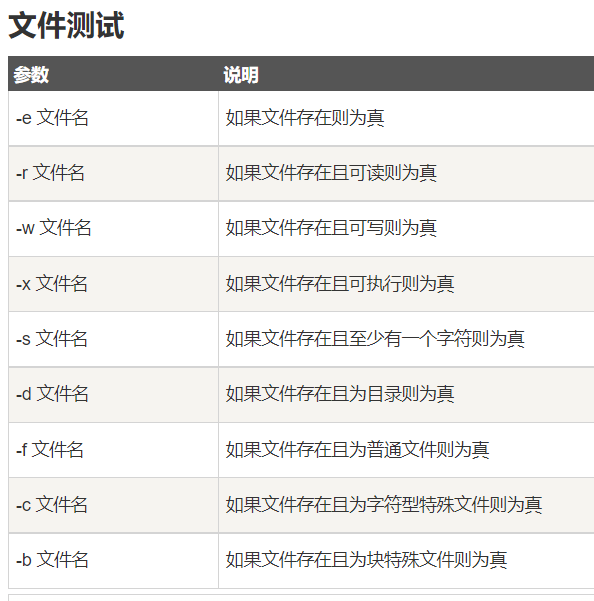
4)判断文件
test File1 –ef File2 两个文件具有同样的设备号和 i 结点号
test File1 –nt File2 文件 1 比文件 2 新
test File1 –ot File2 文件 1 比文件 2 旧
test –b File 文件存在并且是块设备文件
test –c File 文件存在并且是字符设备文件
test –d File 文件存在并且是目录
test –e File 文件存在
test –f File 文件存在并且是正规文件
test –g File 文件存在并且是设置了组 ID
test –G File 文件存在并且属于有效组 ID
test –h File 文件存在并且是一个符号链接(同 -L)
test –k File 文件存在并且设置了 sticky 位
test –b File 文件存在并且是块设备文件
test –L File 文件存在并且是一个符号链接(同 -h)
test –o File 文件存在并且属于有效用户 ID
test –p File 文件存在并且是一个命名管道
test –r File 文件存在并且可读
test –s File 文件存在并且是一个套接字
test –t FD 文件描述符是在一个终端打开的
test –u File 文件存在并且设置了它的 set-user-id 位
test –w File 文件存在并且可写
test –x File 文件存在并且可执行

shell 流程控制 ¶
-
if-else
if condition1 then command1 elif condition2 then command2 else commandN fi
-
for
for var in item1 item2 ... itemN do command1 command2 ... commandN done #!/bin/bash for str in This is a string do echo $str done
-
while
while condition do command done(()) 两个圆括号
() 一个圆括号
$()
$(())
${}
shell script 常见脚本 ¶
一篇教会你写 90% 的 shell 脚本 - 知乎 (zhihu.com)
网络相关 ¶
curl
–head
–silent
内核 ¶
电源管理 ¶
/sys/power
Linux 电源管理 - 休眠与唤醒 - 诺谦 - 博客园 (cnblogs.com)
#Vim
定制化 ¶
dotfiles/vim/.vimrc at master · JJGO/dotfiles · GitHub
anishathalye/dotfiles: ~anish • powered by https://github.com/anishathalye/dotbot 💾
junegunn/vim-plug:  Minimalist Vim Plugin Manager (github.com)
Minimalist Vim Plugin Manager (github.com)
ctrlp.vim/readme.md at master · ctrlpvim/ctrlp.vim · GitHub
多窗口 ¶
- 用
:sp/:vsp来分割窗口 - 同一个缓存可以在多个窗口中显示。
高级功能 ¶
搜索 ¶
$:s/foo/bar/g
Find each occurrence of 'foo' (in the current line only), and replace it with 'bar'.
$:%s/foo/bar/g
Find each occurrence of 'foo' (in all lines), and replace it with 'bar'.
$:%s/foo/bar/gc
Change each 'foo' to 'bar', but ask for confirmation first.
$:%s/\<foo\>/bar/gc
Change only whole words exactly matching 'foo' to 'bar'; ask for confirmation.
$:%s/foo/bar/gci
Change each 'foo' (case insensitive due to the i flag) to 'bar'; ask for confirmation.
$:%s/foo\c/bar/gc is the same because \c makes the search case insensitive.
This may be wanted after using :set noignorecase to make searches case sensitive (the default).
$:%s/foo/bar/gcI
Change each 'foo' (case sensitive due to the I flag) to 'bar'; ask for confirmation.
$:%s/foo\C/bar/gc is the same because \C makes the search case sensitive.
This may be wante
宏 ¶
q{字符}来开始在寄存器{字符}中录制宏
q停止录制
@{字符}重放宏
- 宏的执行遇错误会停止
{计数}@{字符}执行一个宏 { 计数 } 次
-
宏可以递归
- 首先用
q{字符}q清除宏 - 录制该宏,用
@{字符}来递归调用该宏 (在录制完成之前不会有任何操作)
- 首先用
-
例子:将 xml 转成 json (file)
- 一个有 “name” / “email” 键对象的数组
- 用一个 Python 程序?
-
用 sed / 正则表达式
g/people/d%s/<person>/{/g%s/<name>\(.*\)<\/name>/"name": "\1",/g- …
-
Vim 命令 / 宏
Gdd,ggdd删除第一行和最后一行
-
格式化最后一个元素的宏 (寄存器
e)
- 跳转到有
<name>的行 qe^r"f>s": "<ESC>f<C"<ESC>q
- 跳转到有
-
格式化一个
的宏
- 跳转到有
<person>的行 qpS{<ESC>j@eA,<ESC>j@ejS},<ESC>q
- 跳转到有
-
格式化一个
标签然后转到另外一个的宏
- 跳转到有
<person>的行 qq@pjq
- 跳转到有
-
执行宏到文件尾
999@q
- 手动移除最后的
,然后加上[和]分隔符