规划论 | 非线性规划 凸优化
随想
这部分的几节课数学推导比较多,但是基本思想不是特别难。
使用到的主要是多元函数求导、偏导、极值、二次型等内容
老师讲的非常快,很多内容都是其他课程才能讲到的,奢求一个短学期的课讲清楚确实有点难了.自己的时间精力也不是特别充足,所以这部分有很多没有搞明白
无约束优化问题 :直接求导、最速下降法、共轭梯度法、牛顿法等;
等式约束优化问题:拉格朗日 (Lagrange) 乘数法;
不等式约束优化问题 :KKT 条件。
概念
凸集
半平面的交点一定是凸集,
\[
h_{i}(x)=0 \quad g_{j}(x) \leq 0 \quad 凸集的交集为凸集
\]
\[
\begin{align}
f\left[\lambda x_{1}^{*}+(1-\lambda) x_{2}\right] \leq f\left(x_{1}^{*}\right)+(1-\lambda)\\ f\left(x_{2}\right)=f\left(x_{1}^{*}\right)=f\left(x_{2}^{*}\right) ,0<\lambda<1 \\
f\left[\lambda x_{1}^{*}+(1-\lambda) x_{2}^{*}\right]=f\left(x_{1}^{*}\right)=f\left(x_{2}^{*}\right)
\end{align}
\]
最优解的连线段均为最优解
- 推论:线性规划问题的最优解集为所有最优顶点构成的多边形。(归纳法证)
\[
\begin{align}
x^{*}=\sum_{i=1}^{r} \alpha_{i} x^{*}_{i} \\ \sum_{i=1}^{r} \alpha_{i}=1 \\0 \le \alpha_{i} \le 1 \quad i=1, \cdots ,r
\end{align}
\]

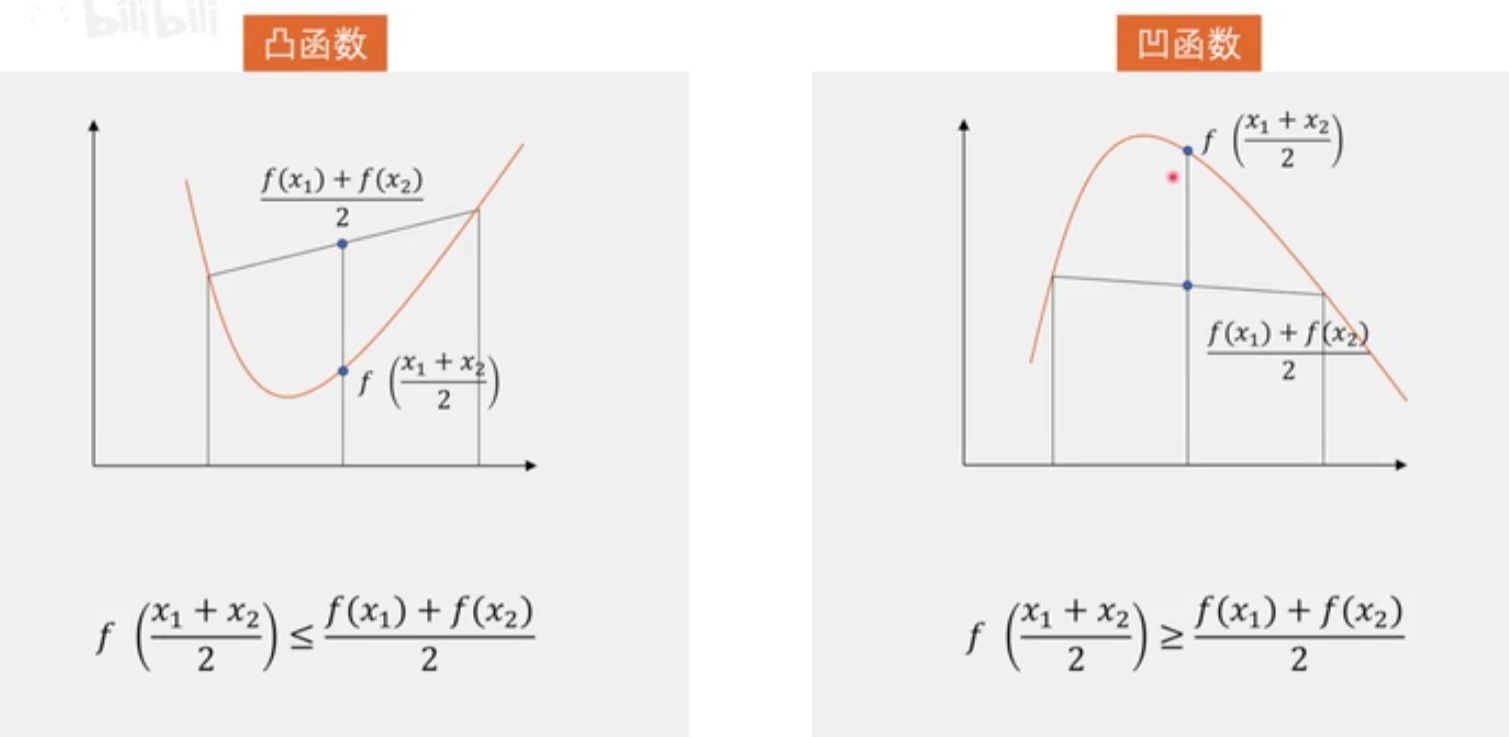
凸函数
设函数 \(f(x)\) 在向量空间 \(\mathbb{R}^n\) 的某个凸子集 \(C\) 上有定义,如果对于任意 \(x_1, x_2 \in C\) 和任意 \(\lambda \in [0, 1]\),都有:\(f(\lambda x_1 + (1-\lambda) x_2) \le \lambda f(x_1) + (1-\lambda) f(x_2)\)
那么函数 \(f(x)\) 就被称为定义在 \(C\) 上的凸函数。
这个定义意味着,对于定义域内的任意两点,函数曲线上的这两点之间的部分都在这两点的连线下方。换句话说,凸函数的局部最小值就是全局最小值。
判定
一阶条件:
对于任意的 \(x_1, x_2 \in \mathbb{R}^n\),都有
\[
f(x_2) \geq f(x_1) + \nabla f(x_1)^T (x_2 - x_1)
\]
几何意义:任何一点的切线在凸函数曲线的下方。
二阶条件:
对于任意的 \(x \in \mathbb{R}^n\),都有
\[
\nabla^2 f(x) \geq 0
\]
几何意义:函数曲线向上弯曲。
性质
\[
\nabla f(x^*)^T (x - x^*) \geq 0 \quad \forall x \in \mathbb{R}^n
\]
则 \(x^*\) 为 \(f(x)\) 的全局最小点。
站在山谷底看,哪里都是向上走
凸优化
函数是凸函数,可行域是凸集;凹函数求最大值其实是一样的,加一个负号就可以了
局部极小点和全局最小点连线的目标函数值相同
- 若目标函数为严格凸函数 , 则如果全局最优解存在 , 必为唯一全局最优解。(反证法)
\[
f\left[\lambda x_{1}^{*}+(1-\lambda) x_{2}^{*}\right]<\lambda f\left(x_{1}^{*}\right)+(1-\lambda) f\left(x_{2}^{*}\right)=f\left(x_{1}^{*}\right)=f\left(x_{2}^{*}\right)
\]
最优解的唯一性为数值解法提供了方便。
\[
\text { LPS } \subseteq \text { QPS } \subseteq \text { QCQPS } \subseteq \text { SOCPs } \subseteq \text { SDPs } \subseteq \text { 锥规划 } \mid \text { CPs }
\]
线性矩阵不等式 LMI
方法
- 松弛到更大的区域
- 分支定解法,拆解成多个凸集进行分布求解
数学模型
\[
\min \quad f(x)
\]
\[
\text{s.t.} \quad h_i(x) = 0 \quad i = 1, 2, ..., m
\]
\[
\quad g_j(x) \ge 0 \quad j = 1, 2, ..., l
\]
\[
x \in R^n
\]
将等式约束变为不等式约束,可以得到
\[
\begin{align}
\min \quad f(x)\\
\text{s.t.} \quad h_i(x) \ge 0 \quad i = 1, 2, ..., m\\
\quad -h_i(x) \ge 0 \quad i = 1, 2, ..., m\\
\quad g_j(x) \ge 0 \quad j = 1, 2, ..., l\\
x \in R^n
\end{align}
\]
以求最小值为标准问题

原问题
\[
\begin{aligned}
\min_x \ f_0(x), x \in \mathbb{R}^n \\
\text{s.t.} \quad f_i(x) \le 0, \text{其中} i=1,2,3...m \\
h_i(x) = 0, \text{其中} i=1,2,3...q
\end{aligned}
\]
等价问题
\[
\begin{align}
\min_x \ \max_{\lambda, \nu} \ L(x, \lambda, \nu)
= f_0(x) + \sum_{i=1}^m \lambda_i f_i(x) + \sum_{i=1}^q \nu_i h_i(x) \\
\text{s.t.} \quad \lambda_i \ge 0 \\
\end{align}
\]
等价性的证明
\[
x 在可行域内
\left\{
\begin{array}{lr}
\lambda_i f_i(x) = 0 \quad 或 \lambda_i = 0 \quad n 或 f_i(x) = 0 \\
\nu_i h_i(x) = 0 \quad 或 \nu_i = 0 \quad 或 h_i(x) = 0
\end{array}
\right.
\]
- 当 \(x\) 在可行域内时,\(\max_{\lambda, \nu} L(x, \lambda, \nu) = f_0(x) + 0 + 0 = f_0(x)\)
- 当 \(x\) 不在可行域内时,\(\max_{\lambda, \nu} L(x, \lambda, \nu) = f_0(x) + \infty + \infty = \infty\)
因此,\(\min \limits_x \max \limits_{\lambda, \nu} L(x, \lambda, \nu) = \min \limits_x f_0(x)\)
对偶问题
\[
\begin{align}
\max \limits_{\lambda,v} \ \min \limits_x \ L(x,\mathbf{\lambda},\mathbf{v})=\\
s.t.= \left\{
\begin{array}{lr}
\nabla_x \ L(x,\mathbf{\lambda},\mathbf{v}) = 0\\
\lambda \ge 0
\end{array}
\right.
\end{align}
\]

解析解法
无约束:
严格局部极小点:
- 必要条件:
- 充分条件:\(\nabla f(X^*)=0\) 且 \(\mathbf{H(f)}\) 正定
驻点:
\(\nabla f\left(x^{*}\right)=\left[\frac{\partial f(x)}{\partial x}\right]_{x=x^{*}}^{T}=0\)
方向导数
方向导数是函数在某一特定方向上的变化率。它表示函数在定义域内某一点沿着给定方向的变化趋势。具体来说,对于一个具有定义域的函数 \(f(x, y)\),在点 \((x_0, y_0)\) 处沿着方向向量
\[
D_{\vec{u}}f(x_0, y_0) = \lim_{h \to 0} \frac{f(x_0 + hu_1, y_0 + hu_2) - f(x_0, y_0)}{h}
\]
其中,\(h\) 是一个很小的正数,\(u_1\) 和 \(u_2\) 是方向向量 \(\vec{u}\) 的分量。
梯度:
具有连续偏导→可微→有切平面→切线都在切平面上→有一个斜率最大的
\[
\nabla f(x)=\left[\begin{array}{c}
\frac{\partial f(x)}{\partial x_{1}} \\
\frac{\partial f(x)}{\partial x_{2}} \\
\vdots \\
\frac{\partial f(x)}{\partial x_{n}}
\end{array}\right]
\]
梯度的几何性质
- \(\nabla f(x)\) 为目标函数 \(f(x)\) 等值面在 \(x\) 的法向量。
- \(\nabla f(x)\) 是目标函数值 \(f(x)\) 在 \(x\) 点增长最快的方向。
雅可比矩阵(Jacobian matrix)
它的重要性在于它体现了一个可微方程与给出点的最优线性逼近,因此,雅可比矩阵类似于多元函数的导数
\[
J(\mathbf{f}) = \begin{bmatrix}
\frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \cdots & \frac{\partial f_1}{\partial x_n} \\
\frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \cdots & \frac{\partial f_2}{\partial x_n} \\
\vdots & \vdots & \ddots & \vdots \\
\frac{\partial f_m}{\partial x_1} & \frac{\partial f_m}{\partial x_2} & \cdots & \frac{\partial f_m}{\partial x_n}
\end{bmatrix}
\]
黑塞矩阵 Hessian Matrix 二阶导数矩阵
\[
\mathbf{H(f)} = \nabla^{2} f(x)=\left[\begin{array}{cccc}
\frac{\partial^{2} f(x)}{\partial x_{1}^{2}} & \frac{\partial^{2} f(x)}{\partial x_{1} \partial x_{2}} & \ldots & \frac{\partial^{2} f(x)}{\partial x_{1} \partial x_{n}} \\
\frac{\partial^{2} f(x)}{\partial x_{2} \partial x_{1}} & \frac{\partial^{2} f(x)}{\partial x_{2}^{2}} & \ldots & \frac{\partial^{2} f(x)}{\partial x_{2} \partial x_{n}} \\
\vdots & \vdots & \ddots & \vdots \\
\frac{\partial^{2} f(x)}{\partial x_{n} \partial x_{1}} & \frac{\partial^{2} f(x)}{\partial x_{n} \partial x_{2}} & \ldots & \frac{\partial^{2} f(x)}{\partial x_{n}^{2}}
\end{array}\right]
\]
二次型理论
- \(\mathbf{H(f)}\) 负定,有极大值: 奇数阶主子式为负数,偶数阶为正数
- \(\mathbf{H(f)}\) 正定,有极小值:顺序主子式都为正数
- \(\mathbf{H(f)}\) 不定,鞍点:特征值有正有负
- \(\mathbf{H(f)}\) 不可逆,无法判断:特征值有 0

对于一个二元函数 \(f(x, y)\),它的黑塞矩阵是一个 2x2 的矩阵,由函数的二阶偏导数组成。黑塞矩阵的一般形式为:
\[
H = \begin{bmatrix}
\frac{\partial^2 f}{\partial x^2} & \frac{\partial^2 f}{\partial x \partial y} \\
\frac{\partial^2 f}{\partial y \partial x} & \frac{\partial^2 f}{\partial y^2}
\end{bmatrix}
\]
由于二阶偏导数具有对称性,即 \(\frac{\partial^2 f}{\partial x \partial y} = \frac{\partial^2 f}{\partial y \partial x}\),所以黑塞矩阵是一个对称矩阵。因此,我们可以将黑塞矩阵简化为:
\[
H = \begin{bmatrix}
\frac{\partial^2 f}{\partial x^2} & \frac{\partial^2 f}{\partial x \partial y} \\
\frac{\partial^2 f}{\partial x \partial y} & \frac{\partial^2 f}{\partial y^2}
\end{bmatrix}
\]
无约束极小值问题的最优性条件
一阶必要条件:(局部极小值 / 局部极大值):\(\nabla f(x^*)=0\)
二阶必要条件:(局部极小值)\(\nabla f(x^*)=0 \text{且} \nabla^2 f(x^*)\geq 0\)
二阶充分条件:(严格局部极小值)\(\nabla f(x^*)=0 \text{且} \nabla^2 f(x^*)>0\)
有约束
\[
\begin{array}{ll}
\min & f(x) \\
\text{s.t.} & h_i(x) = 0, \quad i = 1, 2, ..., m \\
& x \in \mathbb{R}^n
\end{array}
\]
拉格朗日函数
\[
L(x, \lambda) = f(x) + \lambda^T h(x) = f(x) + \sum_{i=1}^m \lambda_i h_i(x)
\]
其中,\(\lambda = [\lambda_1, \lambda_2, ..., \lambda_m]^T\)。
对 \(L(x, \lambda)\) 求偏导数,令偏导数为 0:
\[
\frac{\partial L(x, \lambda)}{\partial x} \Big|_{x^*} = 0 \quad \Rightarrow \quad \nabla f(x^*) + \sum_{i=1}^m \lambda_i \nabla h_i(x^*) = 0
\]
\[
\frac{\partial L(x, \lambda)}{\partial \lambda} \Big|_{x^*} = 0 \quad \Rightarrow \quad h_i(x^*) = 0, \quad i = 1, 2, ..., m
\]
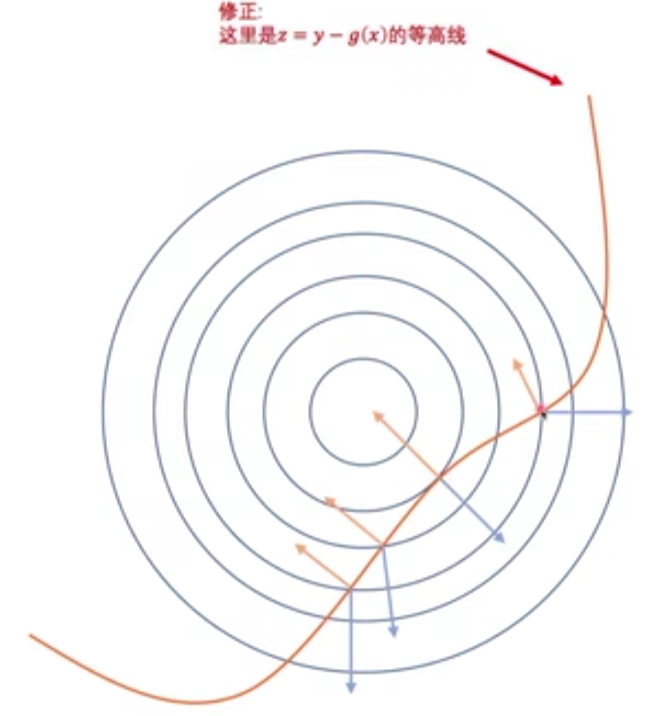
只有在相切的时候,可行域的切线和梯度才能在同一方向,相加才可能为 0
不等式约束
\[
\begin{array}{ll}
\min & f(x) \\
\text{s.t.} & g_i(x) \geq 0, \quad i = 1, 2, ..., m \\
& x \in \mathbb{R}^n
\end{array}
\]
可行方向判别条件(充分条件)
对于点 \(x^{(0)}\),若满足以下条件,则 \(p\) 是 \(x^{(0)}\) 的可行方向:
\[
\nabla g_j(x^{(0)})^T p \geq 0, \quad \forall j \in J(x^{(0)})
\]
其中,\(J(x^{(0)}) = \{j \mid g_j(x^{(0)}) = 0, j = 1, 2, ..., l\}\) 为起作用约束集合。
证明:根据 Taylor 公式,有
\[
g_j(x^{(0)} + \lambda p) = g_j(x^{(0)}) + \lambda \nabla g_j(x^{(0)})^T p + O(\lambda)
\]
当 \(\lambda\) 足够小时,如果 \(j \in J(x^{(0)})\),假设 \(g_j(x)\) 连续,有
\[
g_j(x^{(0)} + \lambda p) \geq 0
\]
如果 \(j \in J(x^{(0)})\),当 \(\nabla g_j(x^{(0)})^T p > 0\) 时,也有
\[
g_j(x^{(0)} + \lambda p) \geq 0
\]
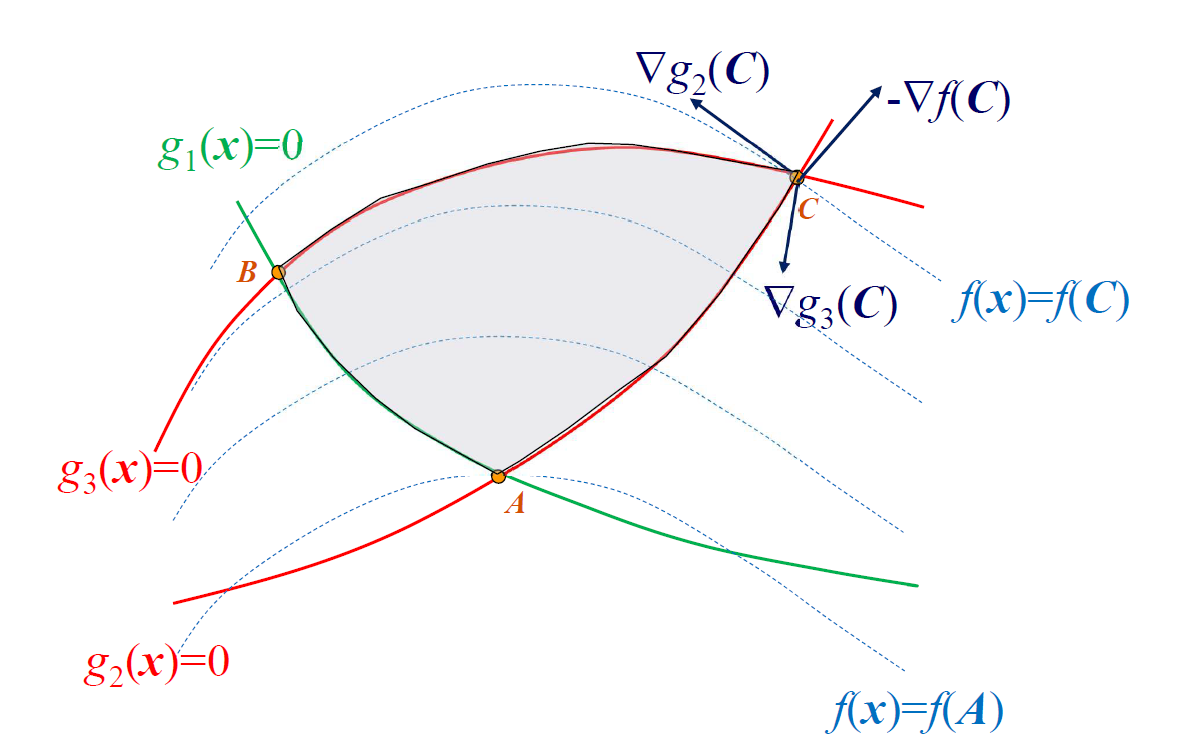
几何含义:与所有起作用约束梯度的夹角小于 \(90^\circ\) 的方向。
局部极小值存在的直观条件
在点 \(x^*\) 处,不存在同时满足下面两类不等式的方向:
\[
\nabla f(x^*)^T p < 0
\]
\[
\nabla g_j(x^*)^T p > 0, \quad j \in J(x^*)
\]
其中,\(J(x^*)\) 为起作用约束集合。
几何含义:不存在与 \(\nabla f(x^*)\) 和所有的 \(\nabla g_{j \in J(x^*)}\) 均成锐角的方向。

Gordan 引理
设 \(B \in R^{m\times n}\),则下列两个系统有且仅有一个有解:
(I) \(Bx < 0\)
(II) \(B^T y = 0, y \ge 0, y \ne 0\)
参考网址:运筹说 第 99 期 | 非线性规划—最优性条件
凸集分离定理中的 Gordan 定理有什么几何意义,或者怎么用数形结合方法解释?
“拉格朗日对偶问题”如何直观理解?“KKT 条件” “Slater 条件” “凸优化”打包理解 _ 哔哩哔哩 _bilibili
翻译一下:
\(B^T\)是\(R^n\)中一组基,由\(m\)个\(n\)维列向量组成,只存在两种情况:
- 存在一个方向,与 \(B^T\) 中所有向量都呈钝角
- \(B^T\) 这组基的非负、非零线性组合可以得到原点
换句话说,如果一组基的非负组合是一个凸锥,则等价为这组基的正组合表示不了原点,除非系数都是 0。即 \(b_j\) 不可能分布在任何超平面的同一侧

正线性相关(positive linear dependence)
几何含义:\(a_j\) 不可能分布在任何超平面的同一侧
正线性相关 \(\Rightarrow\) 线性相关
Fritz John 定理——局部极小点必要条件
\[
\mu_0^* \nabla f(x^*) - \sum_{i=1}^m \mu_i^* \nabla h_i(x^*) + \sum_{i=1}^m \mu_i^{**} \nabla h_i(x^*) - \sum_{j=1}^l \mu_j^* \nabla g_j(x^*) = 0
\]
\[
\Longrightarrow \mu_0^* \nabla f(x^*) - \sum_{i=1}^m (\mu_i^* - \mu_i^{**}) \nabla h_i(x^*) - \sum_{j=1}^l \mu_j^* \nabla g_j(x^*) = 0
\]
\[
\Longrightarrow \mu_0^* \nabla f(x^*) - \sum_{i=1}^m \gamma_i \nabla h_i(x^*) - \sum_{j=1}^l \mu_j^* \nabla g_j(x^*) = 0
\]
其中,\(\gamma_i = \mu_i^* - \mu_i^{**}\),并且有:
\[
\mu_i^* \ge 0 \quad \mu_i^{**} \ge 0 \quad \Longrightarrow \gamma_i = \mu_i^* - \mu_i^{**} \text{ 无符号约束 } \quad i = 1, 2, ..., p
\]
注意,\(\mu_0\)、\(\mu_j\)、\(\gamma_i\) 不可同时为 0。
\(\gamma_i\) 无符号约束,所以前边是加号或是减号都不影响
假设 \(x^*\) 是局部极小点,存在不全为零的 \(\mu_j^* (j=0, 1, 2, ..., m)\) 和 \(\gamma_i (i=0, 1, 2, ..., p)\),满足:
\[
\mu_0^* \nabla f(x^*) - \sum_{i=1}^m \gamma_i \nabla h_i(x^*) - \sum_{j=1}^l \mu_j^* \nabla g_j(x^*) = 0 \quad 拉格朗日条件
\]
\[
\mu_j^* g_j(x^*) = 0 \quad j = 1, 2, ..., m \quad 互补松弛条件\\
\gamma_i h_i(x^*) = 0 \quad i = 1, 2, ..., p \quad 等式互补松弛
\]
\[
\mu_j^* \ge 0 \quad j = 0, 1, ..., m\\
\sum_{j=0}^l \mu_j^* + \sum_{i=1}^m |\gamma_i^* |\neq 0 \quad 强非负条件
\]

-
对于紧致的约束条件,\(g(x^*) = 0\),但是 \(\sum_{j=1}^l \mu_j \nabla g_j(X^*)\) 应该等于负梯度,\(\lambda_i \neq 0\)
-
对于松弛的约束条件,将 \(x^*\)带入方程,一定是小于(大于)0 的,最重要的是要让梯度在 \(\lambda_i\) 的作用下不对结果起作用;
在红线上的,在 \(\lambda_i>0\) 的情况下,是不能实现与负梯度相同的,所以 \(\lambda_i=0\)
Slater 条件——强对偶的充分条件
Slater 条件是指:存在一个点 \(x \in relint D\),\(relint D\) 表示可行域 \(D\) 的相对内部。
使得 \(f_i(x) < 0\),其中 \(i = 1, 2, 3, ..., m\),\(Ax = b\)。
换句话说,Slater 条件是指在可行域的内部存在一个点,使得所有约束函数的值都小于零。这个条件在线性规划和非线性规划中都有应用,是判断对偶问题是否具有强对偶性的充分条件之一。
内部存在点


KKT 条件——强对偶的必要条件
正则条件(regular condition)是指起作用约束 \(\nabla g_{i^*}(x^*)\) 线性无关。
性质:若极小值 \(x^*\) 满足正则条件,则 KKT 条件成立。证明:\(x^*\) 满足正则条件,Fritz John 条件中的 \(\mu_i>0\)。
Kuhn-Tucker 定理:若 \(x^*\) 是局部极小点,且满足正则条件(约束规格),则 Kuhn-Tucker 条件成立。
对于问题来说
\(min f(x) \\s.t. \quad g(X) \le 0\)
求得 \(X^*\) 有三种情况
- \(g(X^*) <0\) 符合条件,就是最优解 ,\(\lambda =0\)
- \(g(X^*) = 0\) 应用拉格朗日求解,引入 \(\lambda \ge 0\)
- \(g(X^*) > 0\) 抛弃
那如果想要不分类讨论 \(\lambda g(X^*) = 0\)
!!! note "能解出最优解的一定是等式,故式 (1)(2)(3) 帮我们求最优解;
式 (4) 和式 (5) 是不等式,帮我们排除一些解,或者得到最优解的适用范围。"

(1)如果目标为最小化(Min)问题,那么不等式约束需要整理成“\(\le0\)”的形式;
(2)如果目标为最大化(Max)问题,那么不等式约束需要整理成“\(\ge0\)”的形式;
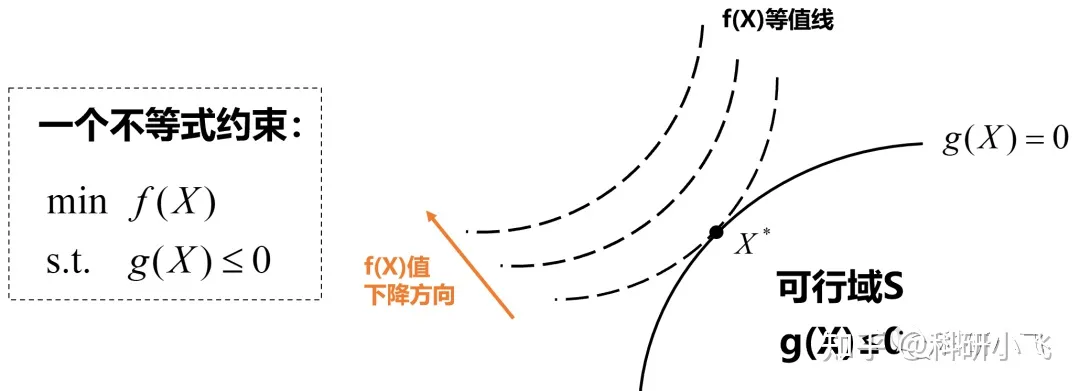
梯度方向垂直于函数等值线,指向函数值增长的方向。
(2)画出 f(X) 的梯度方向(下图红色方向):
梯度方向是函数值增长的方向,因此指向右下方;负梯度方向是函数值下降的方向,指向左上方;
(3)画出g(X)的梯度方向(下图蓝色方向):
由于曲线是g(X)=0,右下方是g(X)<0,是在下降,因此,g(X)函数值增长的方向就是左上方了。
在最优解 X处,f(X*) 和 g(X*) 的梯度方向共线且方向相反。向量共线且方向相反* 在数学上的写法就是:
负梯度向量是另一个梯度向量的 \(lambda\) 倍。移项后发现,这不就是KKT 条件的第一个等式嘛!
$$
begin{align}
nabla f(X^) +lambda nabla g(X^) = 0, lambda ge 0
end{align}
$$
KKT 条件的矩阵形式
\[
\begin{align}
y^* =
\begin{bmatrix}
y_1^* \\
y_2^* \\
\vdots \\
y_m^*
\end{bmatrix}\\
\end{align}
\]
\[
\nabla h(x) =
\begin{bmatrix}
\nabla h_1(x) & \nabla h_2(x) & \cdots & \nabla h_m(x)
\end{bmatrix}
\]
\[
\nabla g(x) =
\begin{bmatrix}
\nabla g_1(x) & \nabla g_2(x) & \cdots & \nabla g_l(x)
\end{bmatrix}=
\begin{bmatrix}
\frac{\partial g_1}{\partial x_1} & \frac{\partial g_2}{\partial x_1} & \cdots & \frac{\partial g_l}{\partial x_1} \\
\frac{\partial g_1}{\partial x_2} & \frac{\partial g_2}{\partial x_2} & \cdots & \frac{\partial g_l}{\partial x_2} \\
\vdots & \vdots & \ddots & \vdots \\
\frac{\partial g_1}{\partial x_n} & \frac{\partial g_2}{\partial x_n} & \cdots & \frac{\partial g_l}{\partial x_n}
\end{bmatrix}^T
\]
Lagrange 驻点条件
\[
\nabla f(x^*) - \nabla h(x^*)y^* - \nabla g(x^*)\mu^* = 0
\]
互补松弛条件
\[
\mu^* \odot g(x^*) = 0 \\\Leftrightarrow \mu_j^* g_j(x^*) = 0 \quad j=1,2,...,l
\]
非负条件
\[
\mu^* \geq 0
\]
可行性条件
\[
\begin{aligned}
h(x^*) &= 0 \\
g(x^*) &\geq 0
\end{aligned}
\]
例题
\[
\min f(x_1, x_2) = (x_1 - 2)^2 + x_2^2 \\
s.t.
\left\{
\begin{array}{lr}
x_2 \le x_1 + 2 \\
x_2 \ge x_1^2 + 1 \\
x_1 \ge 0 \quad x_2 \ge 0
\end{array}
\right.
\]
列出向量
\[
\begin{align}
f(\mathbf{x}) = (x_1 - 2)^2 + x_2^2
\end{align}
\]
\[
\nabla f(\mathbf{x}) = \left[ \begin{array}{c} 2(x_1 - 2) \\ 2x_2 \end{array} \right]
\]
\[
\mathbf{g}(\mathbf{x}) = \left[ \begin{array}{c} x_1 - x_2 + 2 \\ -x_1^2 + x_2 - 1 \\ x_1 \\ x_2 \end{array} \right]
\]
\[
\nabla \mathbf{g}(\mathbf{x}) = \left[ \begin{array}{cccc} 1 & -2x_1 & 1 & 0 \\ -1 & 1 & 0 & 1 \end{array} \right]
\]
列出题目条件
\[
\begin{align}
\nabla f(x^*) - \nabla h(x^*) y^* - \nabla g(x^*) \mu^* = 0
\end{align}
\]
\[
\Longrightarrow \left[ \begin{array}{c} 2(x_1 - 2) \\ 2x_2 \end{array} \right] - \left[ \begin{array}{cccc} 1 & -2x_1 & 1 & 0 \\ -1 & 1 & 0 & 1 \end{array} \right] \left[ \begin{array}{c} \mu_1 \\ \mu_2 \\ \mu_3 \\ \mu_4 \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]
\]
\[
\mu^* \otimes g(x^*) = 0 \quad \Longrightarrow \left[ \begin{array}{c} \mu_1 (x_1 - x_2 + 2) \\ \mu_2 (-x_1^2 + x_2 - 1) \\ \mu_3 x_1 \\ \mu_4 x_2 \end{array} \right] = 0
\]
\[
g(x^*) \ge 0 \quad \mu^* \ge 0
\]
得出方程
\[
\begin{align}
2(x_1 - 2) - \mu_1 + 2 \mu_2 x_1 - \mu_3 = 0 \\
2x_2 + \mu_1 - \mu_2 - \mu_4 = 0 \\
\mu_1 (x_1 - x_2 + 2) = 0 \\
\mu_2 (-x_1^2 + x_2 - 1) = 0 \\
\mu_3 x_1 = 0 \\
\mu_4 x_2 = 0 \\
\mu_j \ge 0 \quad j = 1, 2, 3, 4 \\
x_2 \le x_1 + 2 \\
x_2 \ge x_1^2 + 1 \\
x_1, x_2 \ge 0
\end{align}
\]
求解方程
观察可得:\(\mu_1 = \mu_3 = \mu_4 = 0\)(松弛性)
所以有:
\[
(1 + \mu_2) x_1 - 2 = 0
\]
\[
2x_2 - \mu_2 = 0
\]
\[
-x_1^2 + x_2 - 1 = 0
\]
求解得:
\[
\mu_2^* = 2.6219 \quad x_1^* = 0.5536 \quad x_2^* = 1.3064
\]
\[
f(x^*) = 3.7989
\]
条件与分析
KKT 条件是判断某点是极值点的必要条件,不是充分条件。换句话说,最优解一定满足 KKT 条件,但KKT 条件的解不一定是最优解。
对于凸规划,KKT 条件就是充要条件了,只要满足 KKT 条件,则一定是极值点,且得到的一定还是全局最优解。
在机器学习中的应用
最大熵
交叉熵
数值解法(无约束)
梯度下降法、牛顿法和拟牛顿法 - 知乎 (zhihu.com)
包括基于梯度的数值解法,如最速下降法、牛顿法、拟牛顿法等,以及有约束极值问题的数值解法,如可行方向法、制约函数法等。
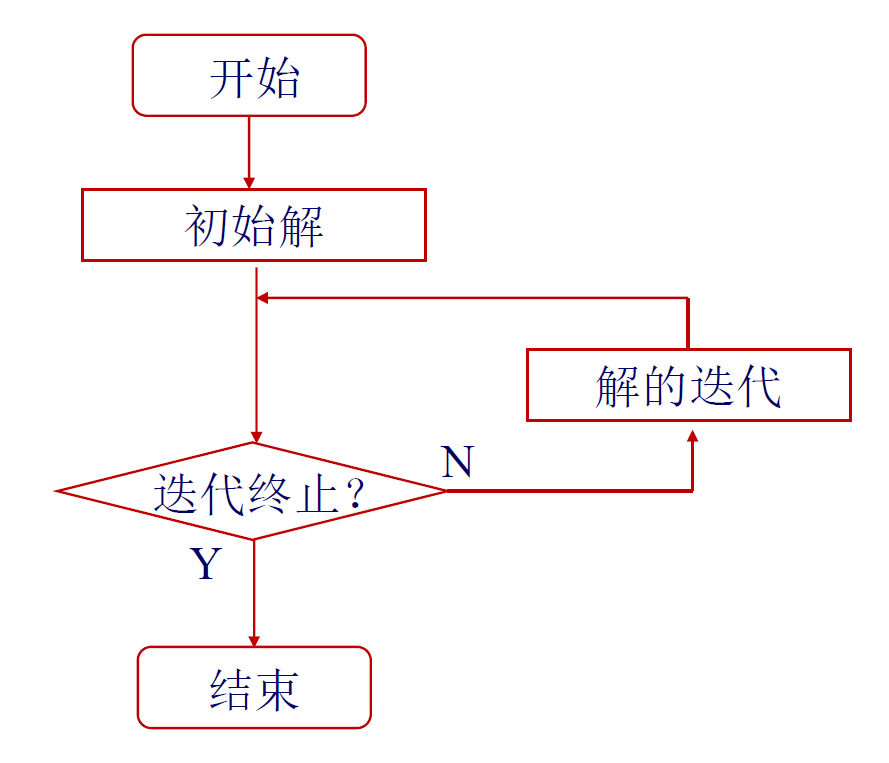
迭代方向
最速下降法——迭代初期
下降最快的方向是负梯度方向
性质:最优步长的时候 \(\nabla f(x^{k+1}) \perp \nabla f(x^{(k)})\)
优点:计算量小,适用于迭代初期
缺点:之字形的迭代路径,接近极值点的时候更严重
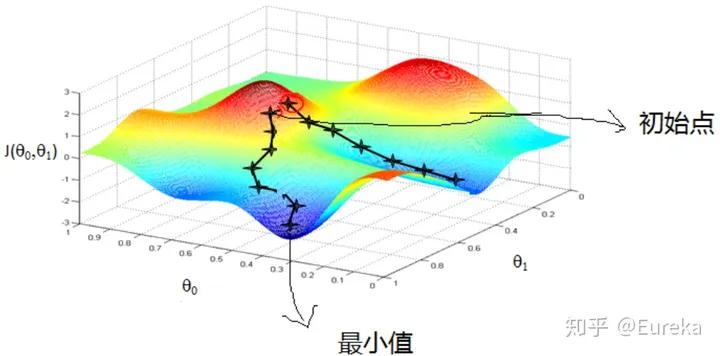
注意
梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。
梯度下降算法:
输入:目标函数 \(f(x)\) ,梯度函数 \(g(x)=\nabla f(x)\) ,计算精度 \(\varepsilon\)
输出: \(f(x)\) 的极小点 \(x^*\)
- 取初值 \(x^{(0)} \in R^n\) ,置 \(k=0\)
- 计算 \(f\left(x^{(k)}\right)\)
- 计算梯度 \(g_{k}=g\left(x^{(k)}\right)\) ,当 \(\left\|g_{k}\right\|<\varepsilon\) 时,停止迭代,令 \(x^{*}=x^{(k)}\) ;否则,令
\[
\boldsymbol{p}_{k}=-\boldsymbol{g}\left(\boldsymbol{x}^{(k)}\right), \text { 求 } \lambda_{k} \text { ,使 }
\]
\[
f\left(\boldsymbol{x}^{(k)}+\lambda_{k} \boldsymbol{p}_{k}\right)=\min _{\lambda \geq 0} f\left(\boldsymbol{x}^{(k)}+\lambda \boldsymbol{p}_{k}\right)
\]
- 置 \(x^{(k+1)}=x^{(k)}+\lambda_{k} p_{k}\) ,计算 \(f\left(x^{(k+1)}\right)\)
- 若 \(\left|f\left(x^{(k+1)}\right)-f\left(x^{(k)}\right)\right|<\varepsilon\) 或 \(\left\|x^{(k+1)}-x^{(k)}\right\|<\varepsilon\) 时,停止迭代,令 \(x^{*}=x^{k+1}\)
- 否则,置 \(k=k+1\) ,转 3。
\(X^T \cdot \mathbf{H} \cdot X = c\)
- 如果 \(\mathbf{H}\) 是对角矩阵,则显然是椭圆
- 如果不是的话,相似对角化以后 \(X^TM^T \ \Lambda\mathbf{}\ M X = c\)
牛顿法——极值点附近
\[
\begin{align}
f(x) \approx f\left(x^{(k)}\right)+\nabla f\left(x^{(k)}\right)^{T}\left(x-x^{(k)}\right)+\frac{1}{2}\left(x-x^{(k)}\right)^{T} \nabla^{2} f\left(x^{(k)}\right)\left(x-x^{(k)}\right)
\end{align}
\]
函数 \(f(x)\) 有极值的必要条件是在极值点处一阶导数为 0,即梯度向量为 0。特别的当 \(H(x^{(k)})\) 是正定矩阵时,函数 \(f(x(k))\) 的极值为极小值。
我们为了得到一阶导数为 0 的点,可以用到牛顿法求解方程方法。根据二阶泰勒展开,对 ∇𝑓(𝑥) 在 𝑥(𝑘) 进行展开得(也可以对上述泰勒公式再进行求导)
\(\nabla f(x) \approx g_k+H_k\left(x-x^{(k)}\right) \approx 0\)
\[
\begin{align}
迭代公式 \Longrightarrow x^{(k+1)} \approx x^{(k)}-H_k^{-1} g_k\\
迭代方向 \Longrightarrow p^{(k)}=-H_k^{-1} g_k \quad 牛顿方向 \\
其中,g_k = g(x{(k)} = \nabla f\left(x^{(k)}\right)\\
\end{align}
\]
优点:极值点附近收敛速率快。
A 缺点:计算量大,需要求二阶导数和 Hessian 矩阵逆。
远离极值点时,不一定是下降方向,需采用进一步修正。
为什么收敛快
至于为什么牛顿法收敛更快,通俗来说梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。
- 设 \(A\) 为对称矩阵,二次函数 \(f(x)=\frac{1}{2} x^T A x+b^T x+c\)
- 驻点方程 : \(\nabla f(x)=Ax+b=0\)
- 有解 : \(\text{rank} A=\text{rank}[A \quad b]\)
- 无解 : \(\text{rank} A \neq \text{rank}[A \quad b]\)
- Hessian 矩阵 : \(\nabla^2 f(x)=A\)
例 : 抛物面
- (1) \(A>0\) 椭球面 : \(x^*=A^{-1} b\) 唯一极小点
- (2) \(A \geq 0 \quad \& \quad \text{rank} A<n\) 椭球柱面 / 平行超平面 : 无穷多个极小点
- (3) \(A \leq 0\) ( 降维 ) 椭球面 : 无界解(极大点)
- (4) \(A\) 不定 ( 高维 ) 马鞍面 : \(f(x)=x_1^2-x_2^2\) 无界解(鞍点解)
Levenberg-Marquardt 修正
- 设计思想 : 将 \(\nabla^2 f\left(x^{(k)}\right)\) 变为正定矩阵 , 保证 \(p\) 是下降方向
- L-M 修正方向 : \(p^{(k)}=-\left[\nabla^2 f\left(x^{(k)}\right)+\mu_{k} I\right]^{-1} \nabla f\left(x^{(k)}\right)\)
- \(x^{(k+1)}=x^{(k)}-\left[\nabla^2 f\left(x^{(k)}\right)+\mu_{k} I\right]^{-1} \nabla f\left(x^{(k)}\right)\)
- \(\mu_{k}>\left|\lambda_{\text {min }}\right| \quad \lambda_{\text {min }} \text { 为 } \nabla^2 f\left(x^{(k)}\right) \text { 最小负特征值 }\)
- \(\mu \rightarrow 0\) : 牛顿法
- \(\mu \rightarrow \infty\) : 最速下降法
- 如果不求特征值,可以从较小的 \(\mu\) 值试探
拟牛顿法
在牛顿法的迭代中,需要计算海森矩阵的逆矩阵 \(\boldsymbol{H}^{-1}\) ,这一计算比较复杂,考虑用一个 \(n\) 阶矩阵 \(\boldsymbol{G}_{k}=\boldsymbol{G}\left(x^{(k)}\right)\) 来近似代替 \(\boldsymbol{H}_{k}^{-1}=\boldsymbol{H}^{-1}\left(x^{(k)}\right)\) 。这就是拟牛顿法的基本想法。
要找到近似的替代矩阵,必定要和 \(\boldsymbol{H}_{k}\) 有类似的性质。先看下牛顿法迭代中海森矩阵 \(\boldsymbol{H}_{k}\) 满足的条件。首先 \(\boldsymbol{H}_{k}\) 满足以下关系:
在 \(x^{k+1}\) 处进行展开
\[
\nabla f(x)=g_{k+1}+\boldsymbol{H}_{k+1}\left(x-x^{(k+1)}\right)
\]
将 \(\boldsymbol{x}=\boldsymbol{x}^{k}\) 代入
\[
g_{k}-g_{k+1}=\boldsymbol{H}_{k+1}\left(x^{(k)}-x^{(k+1)}\right)
\]
记 \(y_{k}=g_{k+1}-g_{k}, \delta_{k}=x^{(k+1)}-x^{k}\) ,则
\[
\begin{aligned}
y_{k} & =\boldsymbol{H}_{k+1} \delta_{k} \\
\delta_{k}& = \boldsymbol{H}_{k+1}^{-1} y_{k} \quad 拟牛顿条件(Secant\ equation)
\end{aligned}
\]
其次,如果 \(H_k\) 是正定的(\(H_k^{-1}\) 也是正定的),那么保证牛顿法的搜索方向 \(p_k\) 是下降方向。这是因为搜索方向是 \(p_k = -H_k^{-1}g_k\)。
由
\[
x^{(k+1)} = x^{(k)} - H_k^{-1}g_k
\]
有
\[
x = x^{(k)} - \lambda H_k^{-1}g_k = x^{(k)} + \lambda p_k
\]
则 \(f(x)\) 在 \(x^{(k)}\) 的泰勒展开可近似为
\[
\begin{align}
f(x) = f\left(x^{(k)}\right) - \lambda g_k^T H_k^{-1} g_k
\end{align}
\]
由于 \(H_k^{-1}\) 正定,故 \(g_k^T H_k^{-1} g_k > 0\)。当 \(\lambda\) 为一个充分小的正数时,有 \(f(x) < f\left(x^{(k)}\right)\),即搜索方向 \(p_k\) 是下降方向。
因此拟牛顿法将 \(G_k\) 作为 \(H_k^{-1}\) 近似。要求 \(G_k\) 满足同样的条件下,首先,每次迭代矩阵 \(G_k\) 是正定时,\(G_k\) 满足下面的拟牛顿条件:
\[
\begin{align}
G_{k+1} y_k = \delta_k
\end{align}
\]
按照拟牛顿条件,在每次迭代中可以选择更新矩阵 \(G_{k+1}\):
\[
\begin{align}
G_{k+1} = G_k + \Delta G_k
\end{align}
\]
DFP 算法
在 DFP(Davidon-Fletcher-Powell)算法中,我们选择 \(G_k\) 作为 \(H_k^{-1}\) 的近似。假设在每次迭代中,矩阵 \(G_{k+1}\) 由 \(G_k\) 加上两个附加项构成:
\[
G_{k+1} = G_k + P_k + Q_k
\]
其中,\(P_k\) 和 \(Q_k\) 是待定矩阵。那么,
\[
G_{k+1}y_k = G_k y_k + P_k y_k + Q_k y_k
\]
为了使 \(G_{k+1}\) 满足拟牛顿条件,我们希望 \(P_k\) 和 \(Q_k\) 满足以下条件:
\[
\begin{aligned}
&P_k y_k = \delta_k \\
&Q_k y_k = -G_k y_k
\end{aligned}
\]
因此,我们可以这样选择:
\[
\begin{aligned}
&P_k = \frac{\delta_k \delta_k^T}{\delta_k^T y_k} \\
&Q_k = -\frac{\delta_k y_k^T G_k}{y_k^T G_k y_k}
\end{aligned}
\]
这将导致矩阵 \(G_{k+1}\) 的迭代公式为:
\[
G_{k+1} = G_k + \frac{\delta_k \delta_k^T}{\delta_k^T y_k} - \frac{\delta_k y_k^T G_k}{y_k^T G_k y_k}
\]
如果初始矩阵 \(G_0\) 是正定的,那么可以证明在迭代过程中每个矩阵 \(G_k\) 也都是正定的。
可以证明 :
- 当目标函数为严格凸二次函数时 , 可经有限步迭代收敛于极值(二次终止性)。为什么不是 1 步 ?
共轭梯度法
参考文献:共轭梯度法的简单直观理解 -CSDN 博客

为什么会走出这一 Z 形线呢?因为梯度下降的方向恰好与 f 垂直,也就是说和等高线垂直。沿着垂直于等高线的方向,一定能让函数减小,也就是最快地下了一个台阶。但是最快下台阶并不意味着最快到达目标位置(即最优解),因为你最终的目标并不是直对着台阶的。
为了修正这一路线,采用另一个方向:即共轭向量的方向。
对照梯度下降法,每次向下走的方向不是梯度了,而是专门的一个方向 \(\vec{d}\) 除此之外和梯度下降法几乎一样。
共轭向量 \(p_i^T A p_j = 0\), 其中 A 是一个对称正定矩阵。\(p_i,p_j\) 是一对共轭的向量。
可见,共轭是正交的推广化,因为向量正交的定义为:\(p_i^T\cdot p_j = 0\)
共轭比正交中间只多了个矩阵 A,而矩阵的几何意义正是对一个向量进行线性变换(可见 Gilber Strang 的线代公开课)。因此共轭向量的意思就是一个向量经过线性变换(缩放剪切和旋转)之后与另一个向量正交。
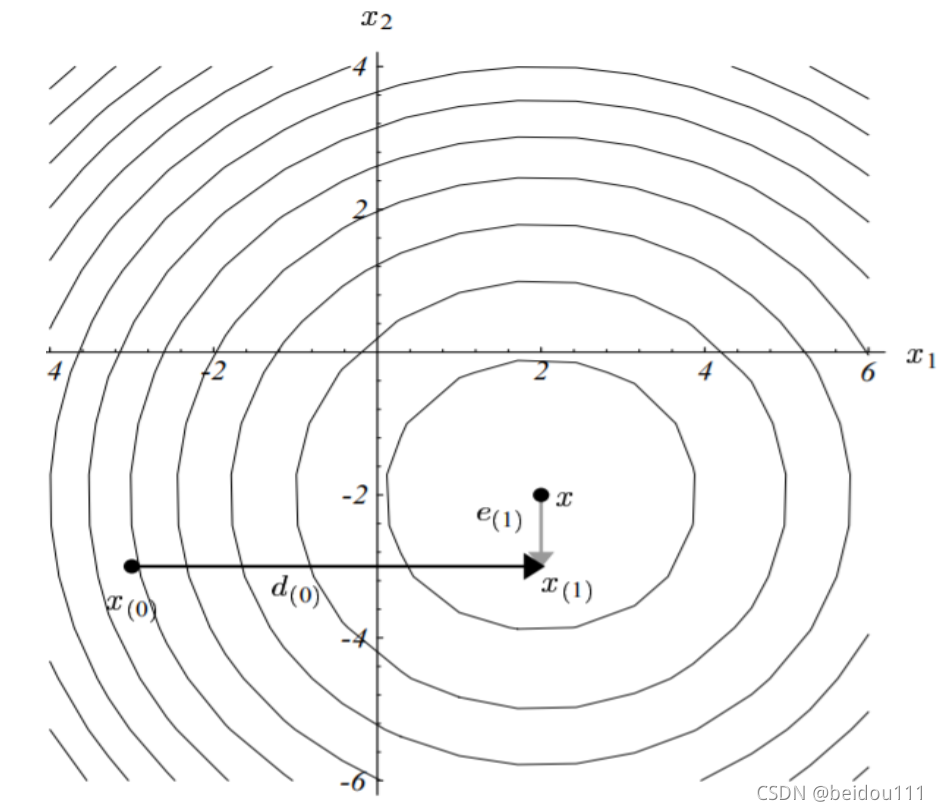

步长选择
设计思想:沿搜索方向的目标函数值最小
\(\lambda_{k}=\arg \min \limits_{\lambda} f\left(\boldsymbol{x}^{(k)}+\lambda \boldsymbol{p}^{(k)}\right)\)
分数法
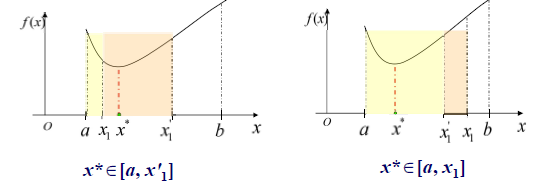
斐波那契法
0.618 法

迭代终止准则
\[
\left\|\boldsymbol{x}^{(k+1)}-\boldsymbol{x}^{(k)}\right\| \leq \varepsilon_{1} \quad\left|f\left(\boldsymbol{x}^{(k+1)}\right)-f\left(\boldsymbol{x}^{(k)}\right)\right| \leq \varepsilon_{2}
\]
\[
\frac{\left\|\boldsymbol{x}^{(k+1)}-\boldsymbol{x}^{(k)}\right\|}{\left\|\boldsymbol{x}^{(k)}\right\|} \leq \varepsilon_{3} \quad \frac{\left|f\left(\boldsymbol{x}^{(k+1)}\right)-f\left(\boldsymbol{x}^{(k)}\right)\right|}{\left|f\left(\boldsymbol{x}^{(k)}\right)\right|} \leq \varepsilon_{4}
\]
梯度模准则(first-order optimality measure)
\[
\begin{align}
\left\|\nabla f\left(\boldsymbol{x}^{(k)}\right)\right\| \leq \varepsilon_{5} \quad\left\|\nabla f\left(\boldsymbol{x}^{(0)}\right)\right\|
\end{align}
\]
数值解法(有约束)
可行方向 —— Zoutendijk 可行方向法
\[
\begin{array}{l}
\nabla f\left(\boldsymbol{x}^{(k)}\right)^{T} \boldsymbol{p}<0 \\
-\nabla g_{j}\left(\boldsymbol{x}^{(k)}\right)^{T} \boldsymbol{p}<0, \quad j \in J\left(\boldsymbol{x}^{(k)}\right)
\end{array}
\]
\[
\begin{align}
\min \eta \\
s.t.
\left\{
\begin{array}{lr}
\nabla f\left(\boldsymbol{x}^{(k)}\right)^{T} \boldsymbol{p} \leq \eta \\
-\nabla g_{j}\left(\boldsymbol{x}^{(k)}\right)^{T} \boldsymbol{p} \leq \eta, \quad j \in J\left(\boldsymbol{x}^{(k)}\right)\\
-1 \le p \le 1
\end{array}
\right.
\end{align}
\]
- \(\eta<0\):可行下降方向
- \(\eta=0\):迭代结束!
- \(\eta>0\):不会出现
制约函数
外点法——罚函数,罚外点
思想:构造罚函数,惩罚可行域外的迭代点
\[
\begin{align}
\min P(x,M)=f(x)+M\sum_{i=1}^{m}h_{i}^{2}(x)+M\sum_{j=1}^{l}[\min (0,g_{j}(x))]^{2}
\end{align}
\]
Courant 罚函数
\(M>0\) 为罚因子,当 \(M\) 趋向无穷时,\(x^{*}\) 为原问题约束极值解。
\([\min (0,g_{j}(x))]^{2}\) 是罚函数,因为在可行域内 \(g(x)\ge 0\),可行域外 \(g(x)\le 0\) ,所以相当于用一个二次函数来拟合。
例子
最小化函数 \(f(x) = -\frac{1}{3}(x_1+1)^3 + x_2\),满足以下条件:
\[
\begin{aligned}
x_1 - 1 &\geq 0 \\
x_2 &\geq 0
\end{aligned}
\]
其中,\(\nabla f(x) = \left[-\frac{(x_1+1)^2}{3}, 1\right]\)。
构造罚函数 :
\[
P(x, M)=\frac{1}{3}(x_{1}+1)^{3}+x_{2}+M[\min (0, x_{1}-1)]^{2}+M[\min (0, x_{2})]^{2}
\]
根据一阶驻点条件 , 有
\[
\begin{aligned}
\frac{\partial P}{\partial x_{1}} & =(x_{1}+1)^{2}+2 M[\min (0, x_{1}-1)]=0 \\
\frac{\partial P}{\partial x_{2}} & =1+2 M[\min (0, x_{2})]=0
\end{aligned}
\]
如果 \(x_{1} \geq 1 \Rightarrow x_{1}=1\) ,矛盾
如果 \(x_{2} \geq 0 \Rightarrow 1=0\) ,不成立
所以考虑 \(x_{1}<1, x_{2}<0\) 区域的驻点。( 可行域外的点 )
\[
\begin{align}
\frac{\partial P}{\partial x_{1}} =(x_{1}+1)^{2}+2 M(x_{1}-1)=0 \\
\frac{\partial P}{\partial x_{2}} =1+2 M x_{2}=0
\end{align}
\]
可得 :
\[
\begin{align}
& x_{1}^{*}=-1-M \pm \sqrt{M^{2}+4 M}\\
& x_{2}^{*}=-\frac{1}{2 M} \\
&\quad M \rightarrow+\infty \\
& \nabla^{2} P(x)=\left[\begin{array}{cc}
2\left(x_{1}+1\right)+2 M & 0 \\
0 & 2 M
\end{array}\right]>0 \\
& 故为极小值
\end{align}
\]

内点法——障碍函数,阻止内点
构造障碍函数,阻止迭代点离开可行域。
\[
\begin{array}{l}
\min \limits_{x \in R_{0}} \bar{P}(x, r)=f(x)+r \sum_{j=1}^{l} \frac{1}{g_{j}(x)} \\
或 \\
\min \limits_{x \in R_{0}} \bar{P}(x, r)=f(x)-\sum_{j=1}^{l} \log g_{j}(x)
\end{array}
\]
其中 \(R_{0}=\left\{x \mid g_{j}(x) > 0, j=1,2, \cdots, l\right\}\) 严格内点
\(r>0\) 为障碍因子,其在迭代中的取值会不断减小,趋向于 0 ,使 \(x\)可趋向于边界。
例子
最小化函数 \(f(x) = x_1 + x_2\),满足以下条件:
\[
\begin{aligned}
-x_1^2 + x_2 &\geq 0 \\
x_1 &\geq 0
\end{aligned}
\]
构造障碍函数 :
\[
\begin{align}
\bar{P}(x, r)=x_{1}+x_{2}-r \cdot\left[\log \left(-x_{1}^{2}+x_{2}\right)+\log \left(x_{1}\right)\right]
\end{align}
\]
根据驻点一阶条件 , 有
\[
\begin{array}{l}
\frac{\partial \bar{P}}{\partial x_{1}}=1-r \cdot \frac{-2 x_{1}}{-x_{1}^{2}+x_{2}} \cdot r \cdot \frac{1}{x_{1}}=0 \\
\frac{\partial \bar{P}}{\partial x_{2}}=1-r \cdot \frac{1}{-x_{1}^{2}+x_{2}}=0
\end{array}
\text { 求解得到: }
\]
\[
\begin{array}{l}
x_{1}=\frac{\sqrt{1+8 r}-1}{4} \\
x_{2}=\frac{3}{2} r-\frac{\sqrt{1+8 r}-1}{8}
\end{array}
\]
\(r \rightarrow 0\) 时 , 有
\[
\left\{\begin{array}{l}
x_{1}^{*}=0 \\
x_{2}^{*}=0
\end{array}\right.
\]
内点法收敛性分析
障碍函数
\[
\bar{P}(x, r)=f(x)-r_k \sum_{j=1}^{l} \log g_{j}(x)
\]
第 k 步障碍函数局部极小值满足
\[
\begin{align}
\nabla \bar{P}\left(x^{(k)}, r_k\right) =\nabla f\left(x^{(k)}\right)-r_k \sum_{j=1}^{l} \frac{1}{g_{j}\left(x^{(k)}\right)} \nabla g_{j}\left(x^{(k)}\right)=0 \\
\nabla P\left(x^{(k)}, r_k\right) =\nabla f\left(x^{(k)}\right)-\sum_{j=1}^{l} \mu_{j}\left(k\right) \nabla g_{j}\left(x^{(k)}\right)=0 \\
\mu_{j}(k)=\frac{r}{g_{j}\left(x^{(k)}\right)} \geq 0
\end{align}
\]
\(x_{k}^{*}\) 迭代收敛时
\[
\begin{align}
\nabla P\left(x^{*}, r\right)=\nabla f\left(x^{*}\right)-\sum_{j=1}^{l} \mu_{j}^{*} \nabla g_{j}\left(x^{*}\right)=0 \\
\mu_{j}^{*}=\frac{r}{g_{j}\left(x^{*}\right)} \geq 0 \\
\mu_{j}^{*} g_{j}\left(x^{*}\right)=r \rightarrow 0
\end{align}
\]
KKT 条件 !
如果 \(x(k)\) 是 \(\min \bar{P}(x ; r)\) 的全局极小值,则内点法收敛到全局最优解!
混合法
- 内点法不能处理等式约束问题
- 外点法不能处理目标函数在可行域外不存在的问题
- 对等式约束和当前不被满足的不等式约束,使用罚函数法,对满足的不等式约束,使用障碍函数法。
智能计算
BP | back propagation
- 维度高,需研究提高训练效率。
- 目标函数曲面复杂,存在多种类型的驻点。
- 不是纯粹优化问题,可能过拟合,影响泛化。
在机器学习部分
蚁群算法
种群迭代
理论上可收敛到全局最优解。
实际当适应度函数值的变化很小或达到最大种群迭代次数时终止
模拟退火
遗传算法