Crawler¶
约 777 个字 预计阅读时间 3 分钟
request¶
telnet¶
(27 条消息 ) telnet 使用教程(新手篇)及问题集锦 _ 冰夏之夜影的博客 -CSDN 博客
(27 条消息 ) Windows 10 操作系统上使用 telnet 命令(图文)_windows telnet 命令 _ 沉默的墨小鱼的博客 -CSDN 博客
教你用 telnet 命令检测端口状态,所有端口映射问题,一招解决 _ 哔哩哔哩 _bilibili
一些常见的术语 ¶
- URI: A system for identifying pieces of information on the network.
- HTTP Methods: The protocol currently contains 8 methods for requesting a URI: , , , , , , , . In this article we focused on the most commonly used one:
OPTIONS``GET``HEAD``POST``PUT``DELETE``TRACE``CONNECT``GET - HTTP Headers: The headers are additional data sent by the user agent to give more context about the transaction going on between the client and the server. Some of them will help the server reply in the most appropriate way.
!!!!python 中 requests 库使用方法详解 - 知乎 (zhihu.com)
- headers
最全常用 User-Agent - 腾讯云开发者社区 - 腾讯云 (tencent.com)
(27 条消息 ) 怎么查看自己浏览器的 User-Agent_ 查看 user-agent_S1901 的博客 -CSDN 博客
(27 条消息 ) python 爬虫之 爬取网页并保存(简单基础知识)_ 爬取网页 head 部分并保存到 _ 黎明之道的博客 -CSDN 博客
- 状态码
遇到的问题 ¶
- 如何使用 F12 开发者工具查看想要的数据:包括网络,元素使用方法:查了好多博客,大概学会了使用方法
- 字符串生成字典:利用 json 函数 Python 如何将字符串转为字典 - VincentZhu - 博客园 (cnblogs.com)
- request 抛异常: 学习 try-except 异常处理方法
- 如何检测输入的是否为正确网址
- 想法:是否包含 com cn www ; 提前验证是否可以登录; 用正则表达式匹配 ( 但不知道有的网址或许没有 com 或者 www 怎么处理 )
- request 中 text() 输出的格式不一:有的很整齐有换行,有的是一整行
- 编码格式不对:
encodeing = 'UTF-8'
beautiful soup 库 ¶
BeautifulSoup 这个库
http://beautifulsoup.readthedocs.org/zh_CN/latest

(1 封私信 ) bearer token 到底是什么? - 知乎 (zhihu.com)
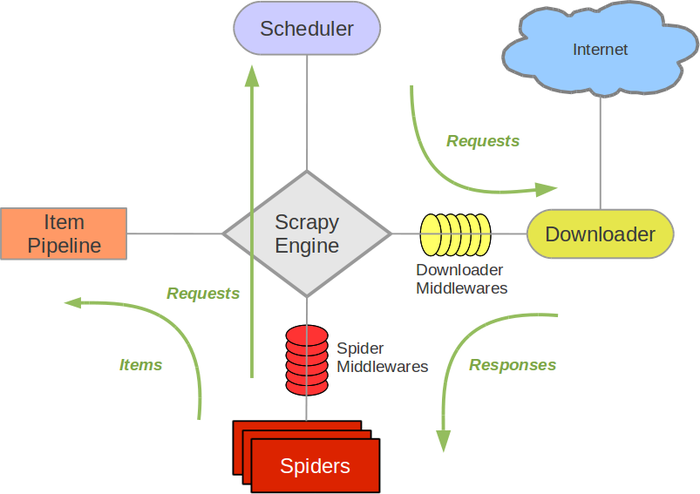
Scrapy 框架 ¶
学习路径 ¶
Scrapy 入门教程 | 菜鸟教程 (runoob.com)
01.Scrapy 框架简介 _ 哔哩哔哩 _bilibili
反爬 ¶
反爬虫手段 ¶
- ip
- 登录
- 验证码
反反爬手段 ¶
- 伪装 IP 地址的方法:
- 使用代理服务器:代理服务器可以将你的请求转发到目标网站,从而隐藏你的真实 IP 地址。你可以通过购买代理服务器或者使用免费的代理服务器来实现伪装 IP 地址。
- 使用 TOR 网络:TOR 网络是一种匿名网络,可以隐藏你的 IP 地址,让你在互联网上匿名浏览。你可以通过下载 TOR 浏览器来使用 TOR 网络,从而实现伪装 IP 地址。
- 修改 Hosts 文件:你可以手动修改 Hosts 文件,将目标网站的域名解析到一个不存在的 IP 地址上,从而达到伪装 IP 地址的效果。
- 获取免费的代理
国内高匿 HTTP 免费代理 IP - 快代理 (kuaidaili.com)
(27 条消息 ) 【爬虫进阶】常见的反爬手段和解决方法(建议收藏)_ 总结反爬虫的目的和常用手段 _ZSYL 的博客 -CSDN 博客