Python¶
约 9065 个字 595 行代码 预计阅读时间 43 分钟
Preparation¶
python
python -i # interactive environment
python ok -q python-basics -u --local # unlocking check
Bug && Debug¶
Q: You get a TypeError: ... 'NoneType' object is not ... . What is most likely to have
happened?
Choose the number of the correct choice:
0) You typed a variable name incorrectly
1) Your indentation mixed tabs and spaces
2) You had an unmatched parenthesis
3) You forgot a return statement
#Answer 3
Abstraction¶
- wishful thinking
Expression¶
- 注释
- 乘法
*
- 幂次
** - `a//b≡⌊a/b⌋
-
两种特殊的赋值:
- 连续赋值:
a = b = 6
- 同步赋值:
a, b = 4, 5
-
a =6
b =7 a, b = b, a
- 连续赋值:
中缀、前缀、后缀 ¶
-
前缀
!a,-b
-
中缀
a+b,a*b
- 后缀
进制转换 ¶
转化为 10 进制的数可用 int( 待转数字 , 进制单位 ) bin(m)将整数m转化为二进制字符串 oct(m)将整数m转化为八进制字符串 hex(m)将整数m转化为十六进制字符串

- 变量记得赋初值
取整计算 ¶
round( x,n )
## n -- 表示小数位数
当参数n不存在时,round()函数的输出为整数。
当参数n存在时,即使为0,round()函数的输出也会是一个浮点数。
此外,n的值可以是负数,表示在整数位部分四舍五入,但结果仍是浮点数。
print(round(123.45)) # 123
print(round(123.45,0)) # 123.0
print(round(123.45,-1)) # 120.0
### 向下取整
int(a)
### 四舍五入
round(a)
###向上取整
math.ceil(a)
###分别取整数部分和小数部分
得到一个元组
math.modf(a)
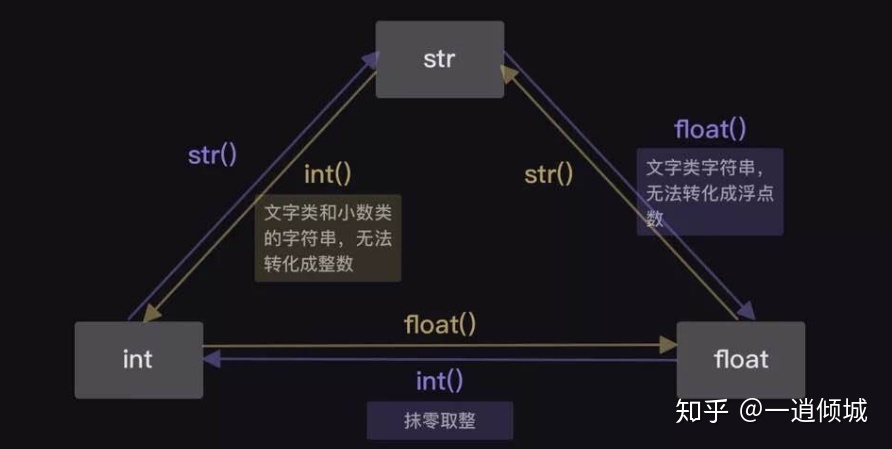
- int()
## int()函数
a = 5.6
print(int(a)) #可以
print(int('5.6')) #不行
不过对于 int() 函数的使用,大家要注意一点:
只有符合整数规范的字符串类数据,才能被 int() 强制转换。
其次,文字形式,比如中文、火星文或者标点符号,不可以被 int() 函数强制转换。
最后,小数形式的字符串,由于 Python 的语法规则,也不能使用 int() 函数强制转换。
浮点形式的字符串,不能使用 int() 函数。但浮点数是可以被 int() 函数强制转换的。
注意:1. 文字类和小数类字符串,不能转化为整数
2. 浮点数转化为整数:抹零取整
- float() 函数:
将其他数据类型转换为浮点数
首先float()函数的使用,也是将需要转换的数据放在括号里,像这样:float( 数据 )。
其次,float()函数也可以将整数和字符串转换为浮点类型。但同时,如果括号里面的数据是字符串类型,那这个数据一定得是数字形式。
conditional expressions¶
<consequent> if <predicate> else <alternative>
#EX
abs(1/x if x!= 0 else 0)
输入输出 ¶
print("面积是:", area)-
print(a, end=', ')print()里的end=用来指定这次输出之后自动输出什么- 默认是
\n,表示要换一行 - 如果要控制输出结果的小数点后的位数,就必须使用格式控制:
print(f"面积是:{area:.2f}")- 字符串前面的
f表示格式字符串,其中的{}中的名字会被同名的变量的值所替换,:后面的内容表示输出的格式(可以省略) .2f表示小数点后保留两位小数的浮点数
-
format 格式化输出 ¶
print({:[fill][align][width]}.format(data)) print("{:.3f}".format(s)) print(format(s, '.3f'))fill:任意一个字符 , 比如 # 、 * 等 , 默认空格填充width:字段宽度,如果未指定,那么字段宽度由内容确定,这种情况下的对齐选项没有意义data:填充的数据align:对齐方式
a,b=map(int, input().split())
a,b = input().split() ## a,b是字符串类型
a = [3,4,5]
print(*a,sep="->",end = '\n') #print的两个参数
end=""##不换行
print(f'{a:<4}')#左对齐
print('67.2F'[-1]) -> F #取出最后一个字符
print(f'{1.8*shuzhi+32:.2f}') # 格式字符串的{}里可以做表达式计算
### 一行输入
list(map(int, input().split())
#如果数据中有浮点数,直接用int会出错
a = tuple(int(item) for item in input().split())
###多行 每行不确定
lst = []
while True:
m = list(map(int, input().split()))
lst.extend(m)
if -1 in m:
lst.remove(-1)
break
###多行输入
while True:
try:
a = input().split()
print(int(a[0])+ int(a[1]))
except:
break
###多行输入2
for line in sys.stdin:
a = line.split()
print(int(a[0]) + int(a[1]))
Environment & Frame¶
Frame
each name is bound to a value
within a frame, a name can't be repeated
An environment is a sequence of frames and also includes its parent
- 可变对象 (mutable) 和不可变对象 (immutable) 是 Python 语⾔的核⼼概念
- 不可变对象,该对象所指向的内存中的值不能被改变。当改变某个变量时候,由于其所指的值不能被改变,相当于把原来的值复制⼀份后再改变,这会开辟⼀个新的地址,变量再指向这个新的地址
- 可变对象,该对象所指向的内存中的值可以被改变。变量(准确的说是引⽤)改变后,实际上是其所指的值直接发⽣改变,并没有发⽣复制⾏为,也没有开辟新的出地址
- 不可变数据类型创建不可变对象,可变数据类型创建可变对象
| 数据类型 | 可变性 | 举例 |
|---|---|---|
| 整数 | 不可变 | 5 |
| 浮点数 | 不可变 | 6.2 |
| 复数 | 不可变 | 2+3.2j |
| 字符串 | 不可变 | 'Hello' |
| 逻辑量 | 不可变 | True |
| 列表 | 可变 | [1,2,'a'] |
| 元组 | 不可变 | (1, 2, 'a') |
| 集合 | 可变 | {1,2,3} |
| 字典 | 可变 | {1:”jan”,2:”feb”,3:”mar”} |
- 不同数据类型对象和逻辑值的变换
| 数据类型 | True | False |
|---|---|---|
| 整数 | ⾮ 0,如 1 | 0 |
| 浮点数 | ⾮ 0,如 1.0 | 0.0 |
| 复数 | ⾮ 0,如 1j | 0+0j |
| 字符串 | ⾮空字符串,"hello" | "" |
| 逻辑量 | True | False |
| 列表 | ⾮空列表 | [] |
| 元组 | ⾮空元组 | () |
| 集合 | ⾮空集合 | set() |
| 字典 | ⾮空字典 | {} |
局部变量 vs 全局变量 ¶
- Python 无需定义变量,第一次对一个变量的赋值就产生了这个变量
- 在函数内
- 对一个变量的赋值,如果之前没有 global 声明,就产生了一个局部变量
- 取一个变量的值,如果之前没有产生过,就去使用全局变量(默认)
- 这之后再赋值就出错
- 规则:如果要在函数中使用全局变量,就在函数一开始使用 global 声明
作用域 ¶
namespace命名空间
scope作用域
life cycle 生存周期
- 命名空间里保存了从标识符到对象的映射
-
当在 Python 中执⾏⼀个代码块时,它拥有三个命名空间:局部、全局和内置
global 关键字
- 如希望在函数中使⽤全局变量,需要⽤ global 关键字声明
- 在函数内,一个变量一经赋值就创建了一个局部变量
- 这之后再试图用
global来访问同名的全局变量是错误的
nonlocal
Statement¶
assignment 赋值语句 ¶
- 过程
1.evaluate all expressions to the right of = from left to right
2.bind all names to the left of = to the resulting values in the current frame
#attention the unique syntax of Python
a,b = b+a,a
if¶
if x<=2760:
y = 0.538 * x
elif x<=4800:
y = 0.588 * x
else:
y = 0.838 * x
- 在
if之后的行,如果保持相同的缩进,就是这个if的一部分,是当表达式的结果是True,即关系成立的时候,要执行的内容
boolean operators¶
优先级规则 not>and>or

while¶
冒号,True 大写
while True:
x = int(input())
if x == -1:
break
cnt += 1
s += x
for¶
python 中有for - else 结构,不要使用
所谓 else 指的是循环正常结束后要执行的代码,
即如果是 bresk 终止循环的情况。else 下方缩进的代码将不执行。
x = int(input())
for k in range(2,x):
if x%k==0:
print(f'{x} is compsite')
break
else:
print(f'{x} is prime')
异常 ¶
try:
语句块1
except 异常类型1:
语句块2
except 异常类型2:
语句块3
…
except 异常类型N:
语句块N+1
except:
语句块N+2
else:
语句块N+3
finally:
语句块N+4
except Exception as n: ##万能捕捉器
- 在
except 异常类型子句中找对应的异常类型,如果找到的话,执行后面的语句块 - 如果找不到,则执行
except后面的语句块 N+2 - 如果程序正常执行没有发生异常,则继续执行
else后的语句块 N+3 - 无论异常是否发生,最后都执行
finally后面语句块 N+4
- raise 抛出异常
raise Exception
raise Exception('load overload')
标准异常 ¶
| 异常名称 | 描述 |
|---|---|
| SystemExit | 解释器请求退出 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除 ( 或取模 ) 零 ( 所有数据类型 ) |
| KeyboardInterrupt | 用户中断执行 ( 通常是输入 ^C) |
| ImportError | 导入模块 / 对象失败 |
| IndexError | 序列中没有此索引 (index) |
| RuntimeError | 一般的运行时错误 |
| AttributeError | 对象没有这个属性 |
| IOError | 输入 / 输出操作失败 |
| OSError | 操作系统错误 |
| KeyError | 映射中没有这个键 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
##一次捕捉多个异常
try:
x,y = map(int, input('输入两个整数:').split())
print(x/y)
except (ZeroDivisionError, TypeError, NameError):
print('输入错误')
异常变量 ¶
- 有时需要除了异常类型以外其他的异常细节:
except Exception as name
再抛异常 ¶
- 如果需要在
except子句中再次抛出刚捕捉到的异常:
def calc(expr):
try:
return eval(expr)
except ZeroDivisionError:
print('divided by zero is illegal!')
raise
自定义异常 ¶
- 根据自己的目的可以自己定义异常类型
- 异常类需要从
Exception类继承
class AgeOutofRange(Exception):
pass
Testing¶
断言 ¶
- 通常写在本文件或者同文件夹下的
_test.py - 函数是写出来给别的程序员用的
- 检查函数接口的数据错误
- 函数入口应该对传入的参数值做检查
assert <条件>, <失败提示文字>
def divide(a, b):
assert b!=0, 'Divided by zero'
return a/b
Doctest¶
placing simple tests directly in docstring of a function
def add(a, b):
"""
返回两个数的和。
示例:
>>> add(2, 3)
5
>>> add(-1, 5)
4
"""
return a + b
import doctest
if __name__ == '__main__':
doctest.testmod()
python3 -m doctest <source_file>
Doctest 的优点是它与文档紧密结合,测试用例直接嵌入在文档字符串中,使得测试更加直观和易于维护。它还可以作为文档的一部分,提供实例和用法示例。
然而,Doctest 适用于简单的测试场景,对于复杂的测试需求,如测试边界条件、异常处理等,通常需要使用其他测试框架,如 unittest 或 pytest。
函数Function ¶
python 的函数是一种数据类型
random库函数
import random
random.random()
random.randint(a, b)
random.choice(lst)
random.shuffle(lst)
random.seed(x)
- 函数要先定义,再使用
- Give each function exactly one job
- Don't repeat yourself
- Define functions generally
documentation¶
def pressure(v,t,n):
""" the job of the function
describe arguments and clarify the behavior
"""
可以在docstring中插入测试样例
声明 Defination ¶
-
分类
-
Pure Function
just return values like
abs,pow
-
Non-pure function
have side effects. like
print
-
- signature
函数的签名包括函数名、参数列表和返回类型。它用于标识函数并提供有关如何调用函数的重要信息。
def <name> (<function parameter>)
函数储存了函数体(函数内容)和它所在的位置(Parent Frame)
- 函数的命名规范
built-in name
bound name
- nested defination 嵌套定义
注意定义域问题:
parent frame : when it is defined
local frame : when it is called
def sqrt(a):
def sqrt_update(x):
return average(x, a/x)
def sqrt_close(x):
return approx_eq(x * x, a)
return improve(sqrt_update, sqrt_close)
调用Call ¶
when you call a function, it creates a new frame
-
再计算所有参数后,才可以执行这个函数
ex1:函数才可以被调用
g(f(2)),f()首先被调用,计算出f(2)之后,g()才被调用ex2:statement 和 function 的区别
def with_if_statement(): if cond(): return true_func() else: return false_func() def with_if_function(): return if_function(cond(), true_func(), false_func())
- 在函数开始执行后,同一个变量都指向同一个
frame当中的值,不会出现一会局部变量,一会全局变量的情况
x = 2
def f():
print(x)
x = 3
#UnboundLocalError: local varibale x referenced before assignment
- 如果要将函数作为一个参数,那么需要格外注意是传入的是这个函数(不带括号
) ,还是这个函数的返回值(带括号)
-
调用函数时,传递参数的值有四种方式:
- 位置参数
- 关键字参数,如
end=',' - 默认值参数
- 可变数量参数
-
关键字参数
- 为了避免位置参数带来的混乱,调⽤参数时可以指定对应参数的名字,这是关键字参数,它甚⾄可以采⽤与函数定义不同的顺序调⽤
- 位置参数和关键字参数混合
-
默认值参数(缺省 sheng)
-
默认参数值在函数对象被创建时计算
def init( arg, result=[]):##实现了持续存储 result.append(arg) print( result) init('a') init('b')
-
-
不定长数目参数 – 形参前面加上星号
- 当函数参数数⽬不确定时,星号将⼀组可变数量的位置参数集合成参数值的元组
-
print()
print(*object,sep=" ",end="\n",file=sys.stdout)object:输出参数sep=" ":输出分割符end="\n":输出函数结束换⾏file=sys.stdout:输出到屏幕
-
实参前面加上星号 -> 容器拆包
*表示将序列拆成⼀个个单独的实参,- ⽽
**则表示将字典拆成⼀个个单独的带变量名的实参
-
收集参数到字典中—
**def countnum(a,**d): #计算参数个数 print(d) print(len(d)+1) countnum(3,x1=9,x2=1,x3=6,x4=89)
-
仅限关键字参数
- 只能传入关键字参数。仅限关键字参数不可缺省(除非有默认值
) ,且只能强制性通过关键字传参
- 可变参数后面的关键字参数都是仅限关键字参数(一旦使用了可变参数,之后的参数都必须通过关键字传递)
- 也可以用单星号 "*" 表示不接受任何可变参数,它可以作为普通参数的结束标志
- 只能传入关键字参数。仅限关键字参数不可缺省(除非有默认值
- 当实参是不可变对象时,形参值改变不会影响实参!
- 当实参是可变对象时,形参值改变可能会影响实参!
return 返回 ¶
- 函数⽤ return 语句返回值
- return 后⾯的表达式的值就成为这次函数调⽤的返回值
- 如函数没有⽤ return 语句返回,这时函数返回的值为
None; - 如果 return 后⾯没有表达式,调⽤的返回值也为
None
- 如函数没有⽤ return 语句返回,这时函数返回的值为
None是 Python 中⼀个特殊的值,虽然它不表示任何数据,但仍然具有重要的作⽤
# None is not displayed by the interpreter as the value of an expreesion
>>> print(print(1),print(2))
1
2
None None
# 注意Print的返回值是None
>>> None + 7
TypeError
- Python 支持函数一次返回多个值
-
返回的多个值和接收多个参数是一样的,以元组的形式打包传递
def f(a,b): return a//b, a%b x,y=f(10,3) print(x,y)##单个 x=f(10,3) print(x)##元组
- 可以将函数作为参数传给另一个函数
- 将函数作为字典的值储存
- 将函数作为另一个函数的返回值
currying 柯理化 ¶
函数式编程–柯理化(Currying) - 知乎 (zhihu.com)
柯里化(Currying)是一种处理多元函数的方法。它产生一系列连锁函数,其中每个函数固定部分参数,并返回一个新函数,用于传回其它剩余参数的功能
常见场景:传入不定量参数,给出需要剩余参数的函数
def lambda_curry2(func):
"""
Returns a Curried version of a two-argument function FUNC.
"""
return lambda x:lambda y: func(x,y)
def curry2(f):
"""Return a curried version of given weo-argument function"""
def g(x):
def h(y):
return f(x,y)
return h #注意这里不可以加括号
return g
- 解决重复传参问题,提高函数适用性
柯理化 (currying) 应用很广泛也很常见。比如,批量发送双 11 活动邮件,通常我们这样做
function sendEmail(from, content, to){
console.log(`${from} send email to ${to}, content is ${content}`)
}
sendEmail('xx公司', '双11优惠折上5折', 'zhangsan@xx.com')
sendEmail('xx公司', '双11优惠折上5折', 'lisi@xx.com')
sendEmail('xx公司', '双11优惠折上6折', 'wangwu@xx.com')
sendEmail('xx公司', '双11优惠折上6折', 'maliu@xx.com')
// ...
邮件发送方是固定的,邮件内容是相对固定的,唯一不同的是邮件的接受者。这正符合柯理化 (currying) 固定部分参数,并返回接受剩余参数新函数的规则。柯理化创建两个临时性的、适用性更强的函数 sendEmailToS5 和 sendEmailToS6,向目标群体,发送指定类型的邮件。
var sendEmailContent = currying(sendEmail)('xx公司')
var sendEmailToS5 = sendEmailContent('双11优惠折上5折')
var sendEmailToS5 = sendEmailContent('双11优惠折上6折')
// 打五折的群组
sendEmailToS5('zhangsan@xx.com')
sendEmailToS5('lisi@xx.com')
// ...
// 打六折的群组
sendEmailToS6('wangwu@xx.com')
sendEmailToS6('maliu@xx.com')
decorators 函数装饰器 ¶
函数装饰器使用 @ 符号和装饰器函数来标记要装饰的函数。
装饰器函数接受被装饰函数作为参数,并返回一个新的函数或可调用对象来替代原函数。
def decorator_function(func):
def wrapper():
print("Before function execution")
func()
print("After function execution")
return wrapper
@decorator_function
def greet():
print("Hello, World!")
#等价于
greet = decorator_function(greet)
匿名函数—lambda 表达式 ¶
- lambda 的⼀般形式是关键字 lambda 后⾯跟⼀个或多个参数,紧跟⼀个冒号,后⾯是⼀个表达式
- 作为表达式,lambda 返回⼀个值,也可以返回另一个
lambda表达式 - lambda ⽤来编写简单的函数,⽽ def ⽤来处理更强⼤的任务的函数。
# nonnested lambda
lambda n, i: count_factors(i)
count_factors(n,i)
# nested lambda
g = lambda x: lambda y : y+1
eight = g(2)(7)
>>> b = lambda x: lambda: x
>>> c = b(88)
>>> c
<function <lambda> at 0x...>
- 匿名函数实现递归
f(f) 就是递归调用的关键,它将相同的函数 f 传递给自身,实现了递归调用。
(lambda f: lambda n: 1 if n == 1 else mul(n,f(f)(n-1)))(lambda f: lambda n: 1 if n == 1 else mul(n,f(f)(n-1)))
- 作为
key参数
leaders.sort(key=lambda x: len(x))
与高阶函数配合使用 ¶
需要两个参数 , 第一个是一个处理函数 , 第二个是一个序列 (list,tuple,dict) map() 将序列中的元素通过处理函数处理后返回一个新的列表 filter() 将序列中的元素通过函数过滤后返回一个新的列表 reduce() 将序列中的元素通过一个二元函数处理返回一个结果
li = [1,2,3,4,5]
# 序列中的每个元素加1
map(lambda x: x+1, li) # [2,3,4,5,6]
# 返回序列中的偶数
filter(lambda x: x % 2 == 0, li) # [2, 4]
# 返回所有元素相乘的结果
reduce(lambda x, y: x * y, li) # 1*2*3*4*5 = 120
Higher-Order Functions¶
functions that manipulate functions
#
def improve(update, close , guess=1):
while not close(guess):
guess = update(guess)
return guess
# 有趣的例子
## 注意 parent frame 和 返回类型
def print_sums(n):
print(n)
def f(k):
return print_sums(n+k)
return f
g = print_sums(1)
h = g(3)
w = h(5)
高阶函数实例 ¶
闭包 ¶
- 函数嵌套:闭包通常是在一个函数内部定义另一个函数。
- 内部函数引用外部函数的变量:在内部函数中引用了外部函数的变量,即使外部函数已经执行完毕,这些变量的引用仍然被保留。
- 保持状态:由于闭包可以持续引用外部函数的变量,因此它可以保持状态,并在多次调用时共享这些状态。
def announce_lead_changes(prev_leader=None):
"""输出两玩家分数差"""
def say1(score0, score1):
if score0 > score1:
leader = 0
elif score1 > score0:
leader = 1
else:
leader = None
if leader != None and leader != prev_leader:
print('Player', leader, 'takes the lead by', abs(score0 - score1))
return announce_lead_changes(leader)
return say1
在say1函数内部,它调用了announce_lead_changes(leader),这相当于又创建了一个新的say1函数,并且这个新的函数也引用了当前say1函数的leader变量。这样就形成了一个递归结构,多个嵌套的say1函数通过引用环境链接在一起。
先返回announce_lead_changes再返回say1。这是因为外部函数announce_lead_changes返回的是内部函数say1的引用。如果直接返回say1,那么每次调用announce_lead_changes都会创建一个新的say1函数,它们之间不会保持共享的状态。而通过先返回announce_lead_changes,外部函数将在递归调用时保持状态,并始终引用相同的say1函数。
这种方式创建了一个闭包,使得在每次调用内部函数时都能够持续跟踪之前的状态。这样,announce_lead_changes函数的每次调用都返回一个新的闭包函数,这些闭包函数共享相同的代码逻辑,但各自保持着不同的状态,即各自引用的prev_leader变量值。
常见函数 ¶
zip函数 ¶
zip()函数⽤于将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表或迭代器
- 如果各个迭代器的元素个数不⼀致,则返回列表⻓度与最短的对象相同
- 参数说明:iterable – ⼀个或多个序列返回值:* 返回元组列表
##字典键值互换
d={'blue':500,'red':100,'white':300}
d1=dict(zip(d.values(),d.keys()))
print(d1)
eval()和exec()函数 ¶
- Python 是⼀种动态语⾔,它包含很多含义
- Python 变量类型,操作的合法性检查都在动态运⾏中检查;运算的代码需要到运⾏时才能动态确定;程序结构也可以动态变化,容许动态加载新模块等。这两个函数就体现了这个特点
eval()是计算表达式 , 返回表达式的值exec()可运⾏ Python 的代码段,返回代码段运⾏的结果
exec('print("hello world")')
while True:
line = input()
if 'bye' in line:
break
exec(line)
数据Data Abstraction ¶
序列的两个特征
- Length
- Element Selection
分类
- sequence
- strings
- tuples
- containers
- sets
- dictionary
一些 ¶
lazy sequence processing¶
在惰性序列处理中,序列的元素并不立即全部计算或生成,而是在需要时逐个生成。这种方式可以节省计算资源和内存,并提高程序的性能,特别是在处理大型数据集时效果显著。
生成器表达式 ¶
圆括号、数据不存储、调⽤⼀次可以枚举⼀次
(expression for i in s if condition)
#把⽣成器表达式⽤作函数的参数值时,外⾯的圆括号可以省略
sum(x*x for x in range(10))
#但是当生成器表达式只是函数的参数之一时,必须有外面的圆括号
def fun(f, b):
for x in b:
f(x)
fun(print, x for x in range(10)) # Error
生成器函数 ¶
生成器函数是一种特殊类型的函数,使用 yield 关键字来生成序列的元素。当调用生成器函数时,并不立即执行函数体,而是返回一个生成器对象,通过调用生成器对象的 next() 方法来逐个生成元素。
def countdown(n):
while n > 0:
yield n
n -= 1
# 调用生成器函数
generator = countdown(5)
print(next(generator)) # 输出:5
print(next(generator)) # 输出:4
print(next(generator)) # 输出:3
print(next(generator)) # 输出:2
print(next(generator)) # 输出:1
生成器函数执行到 yield 关键字,函数会暂停执行并将生成的值返回给调用者。函数的状态会被保留,以便在下一次调用 next() 方法时可以继续执行。当函数执行结束或遇到 return 语句时,生成器对象会引发 StopIteration 异常,表示序列已经生成完毕。
字符串String ¶
TypeError: Odd-length string
意思是奇数长度字符串
但我数了好几遍字符串都是偶数的,想不通,我以为我的转化方式有问题,改了好几种转化方式,后来发现在 python 终端直接输入字符串的话可以输出字节数组,就想到可能我之前的文件 file 有问题,果然发现原来在读的时候读进了一个回车,导致字符串成奇数了,所以在读后后可以加一行
f=f.strip('\n')
可以用来取出字符串中的某个字符
s[0]:s 中的第 1 个字符s[x]:s 中的第 x 个字符- 最右边(后)的字符的下标也可以用
-1来表示 - 负的下标从右向左递减,从
-1开始
字符串计算 ¶
len()返回字符串的长度
-
字符串的
*可以产生重复的长字符串
'*'*10→**********
+可以连接两个字符串
- 字符串中的数据(字符)是 == 不能修改 == 的。
- 去除嵌套
将嵌套列表中的 子元素 合并,可以用
sum函数,第二个参数传入一个空列表[]即可注意:sum 函数的参数包括两个(iterable 可迭代对象,start 求和的初始值
) ,sum 会把可迭代对象内的元素加在 start 参数传入的初始值上。 因此,如果初始值是个列表,那么可迭代对象也必须要是个列表,且必须是嵌套列表,因为只有这个列表元素也是列表时,这些元素才能跟初始值列表相加。 列表的重复 到 用sum展开二层嵌套列表将子元素合并 - 海上流星 - 博客园
sum([[1,2], [3,4]], [])
Out[13]: [1, 2, 3, 4]
切片 slice ¶
s='Zhejiang'
#切片使用负的下标访问
s[1:-3]--> 'heji'
#切片省略第2个下标,表示从第1个下标开始到最后一个的切片
s[2:] --> 'ejing'
#第1个下标为0时,可以省略
s[:3] --> 'Zhe'
s[:-2] --> 'Zhejia'
#切片使用第3个参数,该参数表示切片选择元素的步长
s[0:5:2] --> 'Zei'
#切片使用第3个参数为负数时,表示逆向取切片,逆向时在下标的右边切
s[-1:0:-1] --> 'gnaijeh'
s[::-1] --> 'gnaijehZ'
- 取左不取右;
- 从字符串中取出其中连续的一段的操作叫做切片
- 切片 中的元素编号也可以是负数,来表示从右边开始的编号
- 当切片中的第一个元素编号不存在时,表示从头开始,当第二个编号不存在时,表示到最后一个为止
- 切片还可以有第二个冒号和第三个数据,表示从切片头开始每次加多少
长字符串 ¶
- 用 3 个引号(单引号或双引号)括起来的字符串可以包含多行字符串
- 如果要在程序中用多行表示一个字符串,则可以在每行的结尾用反斜杠()结束
- 三个引号的字符串会自动把换行做进字符串数值里,而
\换行的字符串不会
转义字符\ ¶
- 如果在字符串的内容中需要出现单引号或双引号,就需要用另一种引号来做前后的括号
| t | n | \ | " | ' | ooo | xyz |
|---|---|---|---|---|---|---|
| 制表位 | 回车换行 | \ | " | ' | 8 进制 | 16 进制 |
print(len(r'hello\nworld'))
#在一个字符串字面量前加一个字符r,表示这个字符串是原始字符串,其中的\不被当作是转义字符前缀。
字符串的函数 ¶
-
find()在字符串中查找子字符串所在的位置,如果找不到就返回 -1。当子字符串是单个字符时,就是查找这个字符第一次出现的位置
还有第二和第三个参数,用来表示从哪里开始,到哪里结束
rfind()从后向前寻找
-
count()统计子字符串出现的次数
当子字符串里面只有一个字符时,就是统计字符出现的次数
strip()、rstrip()和lstrip()去掉字符串两端的空格
replace()# 替换子字符串为其他子字符串
upper()、lower()、title()调整大小写
ord()用于获得单个字符的 Unicode 编码
-
chr()用于获得某个编码所代表的字符chr(ord('A')+1)
-
字符串
join:用字符串做分隔符将列表中的元素组成一个字符串a = ['hello','good','boy','wii'] print(' '.join(a)) print(':'.join(a))
iterate 遍历字符串 ¶
s = input()
##下标写法
while i < len(s):
print(s[i])
i+=1
##for in写法
for i in s:
print(i)
##enumerate()写法
for i, element in enumerate(seq):
print(i, element)
##内置函数iter()
for every_char in iter(girl_str):
print(every_char)
enumerate()函数用于将一个可遍历的数据对象 ( 如列表、元组或字符串 ) 组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中
- 逆序的写法
## 字符串切片
a[::-1]
## reversed函数
print(''.join(reversed(a)))
## 利用列表
-
修改字符串的方法
##转换成列表,修改后用join变成新字符串 s1 = list(s) s1[4] = 'E' s = ''.join(s1) ## 序列切片方式 s='Hello World' s=s[:3] + s[8:] ## 使用字符串的replace函数 s = 'Abcdef' s=s.replace('bcd','123')
Split¶
a, b = map(int, input().split('/'))
split()根据所给的参数字符串,将字符串分隔为一些字符串,放在一个列表里
'12/18'.split('/')` --> `['12', '18']
列表List ¶
列表变量是列表的管理者,不是所有者
初始化 ¶
[],列表字面量用[]表示,里面的元素之间用逗号,分隔
-
一个序列容器乘以一个整数,可以形成一个新的重复若干遍的容器
print('6'*23) print([1,2]*3)
-
“列表字面量”是一个表达式而非常量
a = 2 t = [a, a+1, 3]
-
用切片可以复制和赋值整个列表
name = [1,2,3,4] name[2:] = [5,6,7] # [1, 2, 5, 6, 7] name[2:] = [9,10] # [1, 2, 9, 10]
- 用 del 语句删除元素
输入输出 ¶
用print()直接输出整个列表的时候,也会输出两端的[]
in¬ in判断是否在序列中
print('e' in 'Hello')
print(1 in [1,2,3])
print('el' not in 'Hello')
print([1,2] in [1,2,3])
比较 ¶
- 比较是从左到右逐个元素(字符)比较的,一旦在某个位置上的元素已经可以比较出结果,就不再比较下去了
- 当两个序列不等长时,比较到多出来的那个位置为止,此时短的序列的元素值以 0 计算
- 对于字符串中的字符,是按照它们的 Unicode 编码来比较的
函数 ¶
range()用来产生一个数列的迭代器range(b, e, s)不包含右边界
-
list()可以把这个迭代器转成列表增
append():在列表后面增加一个元素 , 返回None
extend():把另一个列表的内容添加到列表的后面
insert():插入
append()和extend()添加一个列表时是不同的
insert()插入到指定位置之前,插入的位置不存在时,加到最后
-
copy():复制列表删
remove():删除第一次出现的那个元素,如果没有,则TypeError
del()删除指定位置上的元素
[x:x+1]=[]也可以删除某个位置上的元素
[:]=[]可以清空整个列表
-
pop():弹出指定位置的元素,不指定则弹出最后一个。返回最后一个值### 抛空一个表 line = input().split() while line: print(line.pop())查
index():查找第一次出现的位置 列表中不用字符串中的 find 函数 ; 查不到ValueError
reverse():反转自己
sum()
len()
-
min(),max()改
c.sort(key = a.index)
列表推导式 ¶
[ expression for item in iterable ]
nl=[number**2 for number in range(1,8) if number % 2 == 1]
#数列求和
n=int(input())
sum([1/i if i%2==1 else -1/i for i in range(1,n+1)])
#求 6+66+666+...+666...666
n=int(input())
sum([int('6'*i) for i in range(1,n+1)])
#双变量 -- 看做for的嵌套
[ x*y for x in [1,2,3] for y in [10,20,30] ]
#因数
x = int(input())
[i for i in range(2,x) if x%i==0]
#素数
x = int(input())
not [i for i in range(2,x) if x%i==0]
#zip与推导式组合用法
a = map(int,input().split())
b = map(int,input().split())
[x*y for (x,y) in zip(a,b)]
高阶函数与列表 ¶
map()- 应用于所有元素 ¶
-
map(f, sq)函数将函数
f作用到可枚举量sq的每个元素上去,并返回结果组成的map对象,map对象本身是一个可枚举量
print(list(map(lambda x: x ** 2, [1, 2, 3, 4, 5])))
# 使⽤ lambda 匿名函数
print(list(map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])))
# 提供了两个列表,对相同位置的列表数据进⾏相加
filter() - 筛选 ¶
filter(f, sq)函数的作用是对于sq的每个元素s,返回所有f(s)为True的s组成的filter对象,filter对象对象本身是一个可枚举量
def is_even(x):
return x % 2 == 0
filter(is_even, range(5))
- 把
map()和filter()合起来
map(square, filter(is_even, range(5)))
reduce() - 所有元素二元操作 ¶
reduce(f, sq)函数接受一个二元操作函数f(x,y),并对于序列sq做累进计算- 这里
f(x,y)的x是累计值,而y是当前值,即序列中的一个元素
from functools import reduce
def my_add(x, y):
return x + y
reduce(my_add, [1,2,3,4,5])
##
from functools import reduce
s1 = reduce(lambda x, y: x+y, map(lambda x: x**2, range(1,10)))
print(s1)
sorted()¶
sorted()函数对字符串,列表,元组,字典等对象进行排序操作- 同样是对列表操作,
list的sort()⽅法是对已经存在的列表进⾏操作 - ⽽内建函数
sorted()返回的是⼀个新的list,原来的list不会被修改
sorted 函数语法
sorted(iterable ,key=None, reverse=False)
iterable– 序列,如字符串,列表,元组等key– ⽤来进⾏⽐较的函数,这个函数只有⼀个参数,参数的值就是取⾃于可迭代对象中的一个元素,函数返回在这个元素上的一个计算结果来作排序,通常当元素本身是一个复合类型(如列表、字典)时,取其中的某个元素- reverse– 排序规则
reverse = True降序reverse = False升序(默认)
元组Tuple ¶
- 与列表相似,元组
Tuple也是个有序序列,用()生成。而且元组的字面量也实际上是表达式 - 可以被索引、切片
- 不能修改 , 所以是静态的,在大数据样本上处理速度较快
(2)不能被当作是元组
函数 ¶
tuple()将列表转成元组
集合Set ¶
(set)是⼀类容器- 没有先后顺序不重复
- 集合的字面量用花括号 {}
初始化 ¶
- 直接给变量赋值⼀个集合字面量
- 使⽤
set()创建⼀个空集合 - 使⽤ set() 将列表或元组转换成集合
- 集合的值不重复,创建集合的时候,python 会消除重复的值。
- 集合的元素是不可变对象
- 但是集合本身是可变的
- 集合内的元素是⽆序的,所以不能通过下标来访问集合元素
函数 ¶
| 函数 | 示例 | 结果 | 说明 |
|---|---|---|---|
| len() | len(s) | 5 | 返回集合中元素的数量 |
| min() | min(s) | 2 | 返回集合中最⼩的元素 |
| max() | max(s) | 11 | 返回集合中最⼤的元素 |
| sum() | sum(s) | 27 | 将集合中所有的元素累加起来 |
| add() | s.add(13) | {2,3,5,7,11,13} | 将⼀个元素加⼊集合中 |
| remove() | s.remove(3) | {2,5,7,11} | 从集合中删除⼀个元素,如果这个元素在集合中不存在,则抛出 KeyError 异常 |
| sorted() | 排序,返回列表 | ||
| update() |
运算 ¶
| 运算 | 函数 | 运算符 | 示例 | 结果 | 说明 |
|---|---|---|---|---|---|
| 并集 | union() |
| | s1.union(s2) |
{2,3,4,5,6,7,11} |
结果是包含两个集合中所有元素的新集合 |
| 交集 | intersection() |
& |
s1 & s2 |
{2,3,5,7} |
交集是只包含两个集合中都有的元素的新集合 |
| 差集 | difference() |
- |
s1 - s2 |
{11} |
s1-s2 的结果是出现在 s1 但不出现在 s2 的元素的新集合 |
| 对称差 | symmertric_difference() |
^ |
s1 ^ s2 |
{4,6,11} |
结果是⼀个除了共同元素之外的所有元素 |

从属判断 ¶
s1.issubset(s2)来判断 s1 是否为 s2 的⼦集s2.issuperset(s1)来判断 s2 是否为 s1 的超集- 使⽤关系运算符
==和!=判断 2 个集合是否包含完全相同的元素。
示例 ¶
from matplotlib_venn import venn3
import matplotlib.pyplot as plt
set1 = {1,2,3} ## 等同于 set1=set((1,2,3))
set2 = {2,3,4}
set3 = {3,4,5}
# Use the venn3 function
venn3([set1,set2,set3], ('set1', 'set2','set3'))
plt.show()

##挑选名单
#要在104位同学中随机挑选20位参加周三上午的连麦分享,但是有7位同学已经在预定的名单中了
#输⼊数据:104⼈名单(学号)和7⼈名单(学号)
#输出数据:20⼈名单和剩下的84⼈名单
import random
ta = {'3190101849', '3190102191', '3190104143', '3190104515'
, '3190104602', '3190104958', '3190105360'}
md = set()
for i in range(104):
md.add(input())
md -= ta
tc = set(random.sample(md, 13)) # 随机取样
tc = tc | ta
print(*tc, sep='\n')
print('-'*80)
print(*(md-tc), sep=', ')
字典Dictionary ¶
- 字典是⼀个⽤“键”做索引来存储的数据的集合。⼀个键和它所对应的数据形成字典中的一个条目。
- 字典⽤花括号
{ }来表示,元素之间用逗号,分隔,每个元素⽤冒号分隔键和数据
字典的键
- 不可变对象可作为字典的键,如数字、字符串、元组
- 可变对象不可以作为字典的键,如:列表、字典等
创建 ¶
- 可以⽤ {} 或者 dict() 来创建空字典
-
⽤
{}或dict()创建字典fac={'math': '0001', 'python': '0002', 'c': '0003'} print(fac) fac=dict([("math","0001"),("python","0002"),("c","0003")]) print(fac) fac=dict(math="0001",python="0002",c="0003") print(fac) #json将字符串转换为字典 import json user_info= '{"name" : "john", "gender" : "male", "age": 28}' user_dict = json.loads(user_info)
操作 ¶
- 删:
del
- 改
- 查:
in和not in
- 遍历:
for
###用items()实现字典遍历
score = {'张三':78, '李四':92, '王五':89}
for key,value in score.items():
print(f'{key}:{value}')
- 运算:⽤
==和!=⽐较两个字典是否相同(键和值都相同)
| 方法 | 功效 | |
|---|---|
keys() |
返回由全部的键组成的一个序列 |
values() |
返回由全部的值组成的一个序列 |
items() |
返回一个序列,其中的每一项是一个元组,每个元组由键和它对应的值组成 |
clear() |
删除所有条目 |
get(key,value) |
返回这个键所对应的值 , 如找不到返回value |
pop(key) |
返回这个键所对应的值,同时删除这个条目 |
- 函数
get()和运算符[ ]不同之处,在于如果键key在字典中不存在,则get(key)返回None值,⽽运算符[ ]会抛出KeyError异常 - 函数 keys()、values()、items() 都是返回⼀个迭代器可以被
for in遍历,由于字典中键不重复,所以keys()和items()的返回结果可以转换成集合⽽values()返回值由于可能存在重复值,应该转换为列表或元组
例子 ¶
##星期
days={1:"Mon",2:"Tue",3:"Wed",4:"Thu",5:"Fri",6:"Sat",7:"Sun"}
num=int(input())
print(days[num])
##四则运算
result={
"+":"x+y",
"-":"x-y",
"*":"x*y",
"/":'x/y if y!=0 else "divided by zero"'}
r=eval(result.get(z))
##统计各位数字次数
str=input()
countchar={}
for c in str:
countchar[c]=countchar.get(c,0)+1
print(countchar)
## sort by key
cnt = sorted(cnt.items(), key=lambda d: d[0], reverse=False)
## sort by value
cnt = sorted(cnt.items(), key=lambda d: d[1], reverse=False)
可以根据两个乘数,查阅字典得到乘积。以3的乘法为例:
d1={(3,1):3,(3,2):6,(3,3):9,(3,4):12,(3,5):15,(3,6):18,(3,7):21,(3,8):24, (3,9):27}
d1[(3,9)]
迭代器Iterator ¶
iter¶
可使用iter函数的:序列、容器、iter本身
r = range(1,10)
s = iter(r)
next(s)
Built-in iterators¶
- map zip filter¶
itertools模块 ¶
count(start, [ste[]):无穷计数cycle(p):循环遍历 prepeat(e, [n]):重复得到 e(可限制为 n 次)
from itertools import count
my_list =["Geeks", "for", "Geeks"]
for i in zip(count(start = 1, step = 1), my_list):
print(i)
| 迭代器 | 实参 | 结果 |
|---|---|---|
| product() | p, q, … [repeat=1] | 笛卡尔积,相当于嵌套的 for 循环 |
| permutations() | p[, r] | 长度 r 元组,所有可能的排列,无重复元素 |
| combinations() | p, r | 长度 r 元组,有序,无重复元素 |
| combinations_with_replacement() | p, r | 长度 r 元组,有序,元素可重复 |
| 例子 | 结果 |
|---|---|
| product('ABCD', repeat=2) | AA AB AC AD BA BB BC BD CA CB CC CD DA DB DC DD |
| permutations('ABCD', 2) | AB AC AD BA BC BD CA CB CD DA DB DC |
| combinations('ABCD', 2) | AB AC AD BC BD CD |
| combinations_with_replacement('ABCD', 2) | AA AB AC AD BB BC BD CC CD DD |
ranks = ['A', 'K', 'Q', 'J', '10', '9', '8', '7', '6', '5', '4', '3', '2'
suits = ['H', 'D', 'C', 'S']
# 生成器表达式版本
cards = ((suit, rank) for suit in suits for rank in ranks)
print(*cards)
# product版本
import itertools as it
cards = it.product(suits, ranks)
print(*cards)
生成器Generator ¶
yield
preserve newly created environment for later call
when next is called, execution resumes where it left off
def letter_generator():
current = 'a'
while current <= 'd':
yield current
current = chr(ord(current) + 1)
项目 ¶
程序结构 ¶
- 模块⽤于组织较⼤的 Python 项⽬
- Python 标准库拆分为多个模块,以便管理。
- 模块以⽂件形式存放,⼀个模块定义了⼀组 Python 函数和其他对象,它们是有关联的
- ⼀个 Python 程序可以在不同⽂件中,这些⽂件是⼀个个模块。⽤ import 语句引⼊
- 模块名是另外⼀个 Python ⽂件的⽂件名 , 不包含扩展名 , 模块就是可以运⾏的程序
import <模块名>就是执⾏由模块名代表的程序-
引入模块中的函数另⼀⽅法
from <模块名> import *- 这种⽅法引⼊模块中的所有函数,调⽤的时候不需要再加模块名
from <模块名> import <函数名>- 这种⽅法引⼊模块中的单个函数,调⽤的时候也不需要再加模块名
- 模块名字空间
- 每个 py 文件是一个模块,模块名就是文件名
- 在每个模块里的全局变量和函数是模块内的,在模块内部可以直接使用,在模块外部要通过模块的名字引用
- 用哪个 py 文件启动程序,那个 py 文件的模块的模块空间就是全局名字空间
dir(模块名):显示模块属性__main__- 程序运⾏时,解释器会制造变量
__name__ - 如果模块作为主程序运⾏,
__name__变量的值是__main__ - 如果模块被另⼀模块导⼊,
__name__变量的值是 模块名
- 作为主程序运⾏(⽂件名 factorial.py)
sys模块 ¶
- 如果 area.py 和 triangle.py 上述两个⽂件在同⼀个⽬录下,通过 Python 运⾏主程序 area.py, 会引⽤ triangle 模块,执⾏函数 area
- 如不在同⼀⽬录,可⽤ sys 模块加⼊搜索路径后调⽤。
- 模块的查找路径:
sys.path
-
sys 模块中的常⽤函数和其他重要对象
sys.argv:命令行参数
sys.exit([arg]):程序中间的退出,arg=0为正常退出
sys.getdefaultencoding():获取系统当前编码
sys.setdefaultencoding():设置系统默认编码
sys.getfilesystemencoding():获取⽂件系统使⽤的编码⽅式,Windows 下返回 'mbcs',mac 下返回 'utf-8'
sys.path:模块搜索路径的字符串列表
sys.platform:获取当前系统平台
sys.stdin, sys.stdout, sys.stderr: 变量包含与标准 I/O 流对应的流对象 . 如果需要更好地控制输出 , ⽽print不能满⾜你的要求 , 它们就是你所需要的 . 你也可以替换它们 , 这时候你就可以重定向输出和输⼊到其它设备 , 或者以⾮标准的 ⽅式处理它们
命令行参数 ¶
- sys.argv[0] # 程序的⽂件名
- sys.argv[1] 第⼀个参数
包 ¶
- 包是模块概念的⾃然扩展,旨在应付⼤型的项⽬
- 模块把相关的函数、类和变量组织到⼀个⽂件中
- 包则把相关的模块组织到⼀个⽬录中
- 包是⼀个⽬录,其中包含⼀组模块⽂件和⼀个
init.py⽂件 init.py可以是空⽂件,但⽬录中必须有- 第⼀次加载包时,会执⾏
init.py⽂件,完成初始化⼯作 - 如果模块存在于包中,使⽤
import 包名.模块名形式导⼊包中模块 - ⽤以下形式调⽤函数:
包名.模块名.函数
对象和类 ¶
OOP:Object Oriented Programming
对象三个要素
- 类(类型
) :int、 float 、bool 、string list 、tuple 、dict 、set - 对象举例:
3,[5.7,’a’],{1:4,2:5} type()函数判断对象的类
- 类 (class): 定义属性 ( 数据 ) 和⾏为(⽅法)的模板
- 实例 (instance):是⽤类产⽣的对象,
- 术语对象 (object) 和实例 (instance) 经常是可以互换的
- 使⽤圆点运算符 (.) 引⽤⽅法和属性
- 类有⾃⼰名字空间
- 每个对象也有⾃⼰的名字空间
创建和使用 ¶
class <类名>:
initializer
methods
class Student: #学⽣类:包含成员变量和成员方法
def __init__(self,mname,mnumber): #构造方法
self.name = mname #成员变量
self.number = mnumber
self.Course_Grade = {}
self.GPA = 0
def getInfo(self): #成员方法
print(self.name,self.number)
s1 = Student("wang","317000010") #创建s1对象
s1.getInfo()
Student.getInfo(s1)
s2=Student("zhang","317000011") #创建s2对象
s2.getInfo()
-
__init__()__init__()⽅法是 Python 类中的⼀种特殊⽅法,⽅法名的开始和结束都是双下划线,该⽅法称为构造⽅法,当创建类的对象时,它被⾃动调⽤
__init__()⽅法中可以声明类所产⽣的对象属性,并可为其赋初始值。该⽅法有⼀个特点,不能有返回值,因为它是⽤来构造对象的,调⽤后实例化了⼀个该类型的对象
-
self参数- 类的实例⽅法有⼀个名为
self的参数,并且必须是⽅法的第⼀个形参(如果有多个形参的话) ,self参数代表将来要创建的对象本身
- 在类的⽅法中访问实例变量(数据成员)时需要以 self 为前缀
- 在外部通过对象调⽤对象⽅法时并不需要传递这个参数,如果在外部通过类调⽤对象⽅法则需要显式为
self参数传值
- 类的实例⽅法有⼀个名为
封装 ¶
- 将数据和对数据的操作组合起来构成类,类是⼀个不可分割的独⽴单位
- 类中既要提供与外部联系的接⼝,同时⼜要尽可能隐藏类的实现细节。
- Python 类中成员分为数据(变量、属性)成员和⽅法(函数)成员。
方法和属性类型 ¶
- Python 类中成员:
- 数据成员(变量、属性)
- 类数据成员
- 实例数据成员
- 公有
- 内部:以两个下划线
__开头
- ⽅法(函数)
- 实例⽅法:
- 公有
- 私有 :⽅法名以两个下划线
__开头
- 实例⽅法:
- 类⽅法 : @classmethod
- 静态⽅法:@staticmethod
- 在 Python 中,以下划线开头的⽅法名和变量名有特殊的含义,尤其是在类的定义中
文件 ¶
打开文件 ¶
fileobj = open(filename,mode)
fileobj是open()返回的文件对象filename是该文件的文件名mode是指明文件类型和操作的字符串mode的第一个字母表明对其的操作mode的第二个字母是文件类型:t(可省略)代表文本类型文件b代表二进制类型文件
| 文件打开模式 | 含义 |
|---|---|
"r" |
read 只读模式 ( 默认 ) |
"w" |
write 覆盖写模式 ( 不存在则新创建;存在则重写新内容 ) |
"a" |
append 追加模式 ( 不存在则新创建;存在则只追加内容 ) |
"x" |
create 创建写模式 ( 不存在则新创建;存在则出错 ) |
"+" |
与 r/w/a/x 一起使用,增加读写功能 |
"t" |
文本类型 |
"b" |
二进制类型 |
文件读写函数 ¶
## 文件迭代器
f = open("1.txt","r")
for i in f:
XXXX
| 名称 | 含义 |
|---|---|
open() |
打开文件 |
read(size) |
从文件读取长度为 size 的字符串,如果未给定或为负则读取所有内容 |
readline() |
读取整行,返回字符串 |
readlines() |
读取所有行并返回列表 |
write(s) |
把字符串 s 的内容写入文件 |
writelines(s) |
向文件写入一个元素为字符串的列表,如果需要换行则要自己加入每行的换行符 |
seek(off, whence=0) |
设置文件当前位置 |
tell() |
返回文件读写的当前位置 |
close() |
关闭文件。关闭后文件不能再进行读写操作 |
文字编码 ¶
- ANSI 编码:
- Windows 常用的编码
- UTF-8 编码:
- UTF-8 是缺省编码格式
- 中文编码:
- GB2312,GBK
- Windows 可在 cmd 下用
chcp命令查看 - 默认会以本地编码打开文件
- 打开编码为 GBK 的文件:
open(<文件名>,<模式>,encoding='GBK')
重定向 ¶
sys.stdin标准输入sys.stdout标准输出sys.stderr标准错误输出
import sys
s=sys.stdin.readlines() #从文件读入变为从键盘输入
print(s)
文件与异常 ¶
try:
f = open('xxx')
except:
print('fail to open')
finally:
f.close()
- with 方法
with open("1.txt") as file:
data = file.read()
With open('1.txt') as f1, open('2.txt') as f2:
do something
- 紧跟
with后面的表达式被求值后,将调用返回对象的__enter__(),然后将函数的返回值赋值给as后面的变量 - 当
with后面的代码块全部被执行完之后,将调用前面返回对象的__exit__()方法