图论 | Graph Theory ¶
约 4261 个字 55 行代码 预计阅读时间 17 分钟
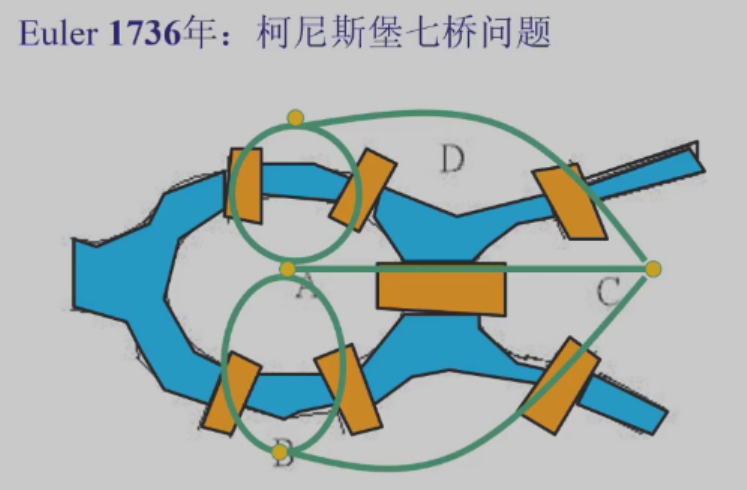
基本概念和建模 ¶
图论是数学的一个分支,主要研究图这种数据结构。图论中的基础概念主要包括:
-
图(Graph):图是由顶点(Vertex)和边(Edge)组成的数据结构,用于表示对象之间的关系。图通常表示为 G = (V, E),其中 V 是顶点集合,E 是边集合。
-
顶点(Vertex):图中的每个元素称为顶点或节点,表示问题中的一个对象或实体。
-
边(Edge):边表示图中顶点之间的连接关系,可以是有向的(表示方向)或无向的(不表示方向
) 。 -
有向图(Directed Graph):边具有方向的图称为有向图,也称为网络图。
-
无向图(Undirected Graph):边没有方向的图称为无向图。
-
权重(Weight):图中的边可以具有权重,表示连接两个顶点的成本或距离。
-
路径(Path):图中从一个顶点到另一个顶点的边的序列称为路径。
-
连通性(Connectivity):图中任意两个顶点之间是否存在路径,如果存在,则图是连通的。
-
环(Cycle):图中从一个顶点出发,经过一系列边后又回到该顶点的路径称为环。
-
子图(Subgraph):由原图中部分顶点和连接这些顶点的边组成的图称为子图。
表示方法 ¶
邻接表和邻接矩阵 ¶
11. MIT 线性代数—矩阵空间、秩 1 矩阵和小世界图 - 知乎 (zhihu.com)
【3.7】线性代数应用:图和矩阵 - 知乎 (zhihu.com)
邻接表(Adjacency List) - 知乎 (zhihu.com)
图的邻接表存储
图的邻接矩阵存储
拓扑排序 ¶
对一个有向无环图 ( Directed Acyclic Graph 简称 DAG ) G 进行拓扑排序,是将 G 中所有顶点排成一个线性序列,使得图中任意一对顶点 u 和 v ,若边 < u , v > ∈ E ( G ),则 u 在线性序列中出现在 v 之前。通常,这样的线性序列称为满足拓扑次序 ( Topological Order )
算法¶
对每个顶点计算入度,将所有入度为 0 的点放入队列,当队列不为空时,删除一个顶点 v,并将临接到 v 的所有顶点的入度 -1。只要入度为 0 就将其放入队列中,那么出队顺序记为拓扑排序。
最短路径算法 ¶
彻底弄懂最短路径问题 - 加拿大小哥哥 - 博客园 (cnblogs.com)
Dijkstra 和 Bellman-Ford 的区别
Dijkstra 开头是 D,所以是以点为单位进行操作
Bellman-Ford 开头是 B,所以是以边为单位进行操作
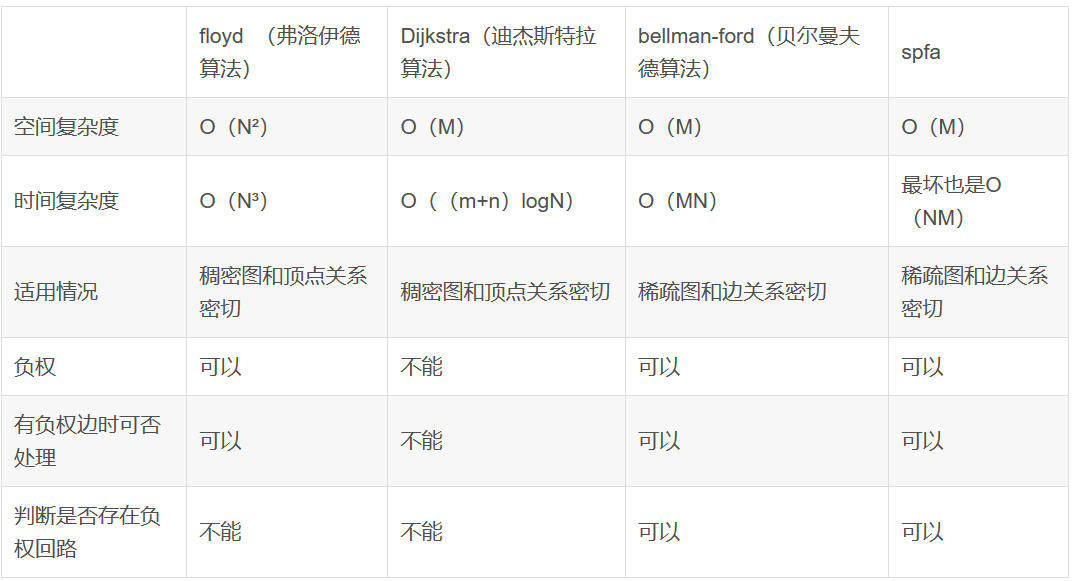
Floyd - 多源最短路 ¶
常数小,复杂度高
思路 ¶
依次将每个点作为中间点进行更新。
邻接矩阵实现,D 数组记录最短路径,Path 数据记录终点的前一个点
Floyd 算法数学描述 ¶
设 G = (V, E) 是一个带权有向图,其中 V 是顶点集合,E 是边集合,w(u, v) 表示从顶点 u 到顶点 v 的权重。Floyd 算法的数学描述如下:
- 初始化 $ D[i][j] = w(i, j)\(,如果\) i = j\(,则\) D[i][j] = 0\(;如果\) (i, j) in E$,则 \(D[i][j] = \infty\)。
- 对于每个 $ k in V$,执行以下操作:
- 对于每个 $ i, j in V$,如果 \(D[i][k] + D[k][j] < D[i][j]\),则更新 \(D[i][j] = D[i][k] + D[k][j]\)。
for (k = 0; k < V; k++) {
for (i = 0; i < V; i++) {
for (j = 0; j < V; j++) {
if (graph[i][k] + graph[k][j] < graph[i][j]) {//能松弛就松弛
graph[i][j] = graph[i][k] + graph[k][j];
}
}
}
}
注意 ¶
- 适用范围:
Floyd-Warshall算法适用于解决所有节点对之间的最短路径问题,能够计算任意两个节点之间的最短路径。 - 时间复杂度:
Floyd-Warshall算法的时间复杂度为 \(O(V^3)\),其中 V 是节点数量。 - 负权环路:
Floyd-Warshall算法不能处理带有负权环路的图,但它能够检测到负权环路的存在。
Dijkstra¶
假设现在要求出从某一点 s 到其他所有点的最短距离,对于每个点 v 均维护一个“当前距离”(dist[v])和“是否访问过”(visited[v])。首先将dist[s]初始化为 0,将其他点的距离初始化为无穷,并将所有点初始化为未访问的。记u->v的边权为weight[u->v]。然后进行以下步骤:
- 从所有未访问的点中,找出当前距离最小的,设为 u,并将其标记为已访问的。
- 调整 u 的所有边(若是有向图则为出边)连接的并且未被访问过的点:若
weight[u->v] + dist[u] < dist[v], 则将dist[v]更新为dist[u]+weight[u->v]。 - 重复 1 和 2 步骤,直到所有点都被标记为已访问的,则
dist[i]即s到i的最短距离。如果只想求从 s 到某一点的最短距离,那么当该点被标记为访问过之后可直接退出。 - 补充:如果除了最短距离之外还想求出具体的路径,只需建立一个
pre数组,在步骤 2 后添加操作: pre[v] = u(前提是dist[v]被更新) 。
分析 ¶
最多次数:最多需要更新 < 顶点 -1> 次,将未访问过的点更新成为已经访问过的点;
限制:所有边的权值非负
如果是正权图,集合内的点到初始点的最短距离已经确认了,把没在集合内的点加入路径只可能会增加无用的边,也就增加了路径长度;所以只根据集合内点的邻边来更新,就能得到当前的最小 d[x] 了。
但如果是负权图,注意上句话中的文字 “把没在集合内的点加入路径”,这个时候,如果边的长度是负的,就有可能产生更小的 d[x]!而 Dijkstra 根本没有不会考虑 “把没在集合内的点加入路径”这种情况,这也就是 Dijkstra 算法目光短浅的原因。
相当于加入已经访问过的集合,最短路径就不会再更新了
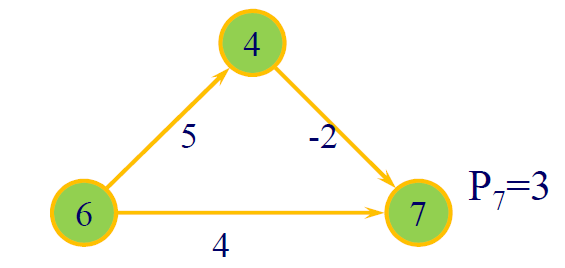
数学推导
P(v_j):表示到点v_j的最短距离。-
T^{(k)}(v_j):表示搜索到第k步时,到T点v_j的最短距离。 -
设定初值( 将起点以外距离都设置为无穷 )
- \(T^{(0)}(v_1) = 0\)
-
\(T^{(0)}(v_j) = \infty \quad j = 2, 3, ..., n\)
-
确定 P 点(从所有未访问的点中,找出当前距离最小的)(!!! 贪心体现在此处 )
-
\(P(v_j) = \min\limits_j \{ T^{(k)}(v_j) \}\)
-
更新 T 值(进行松弛操作)
- \(T^{(k+1)}(v_j) = \min\limits_i \{ T^{(k)}(v_j), P(v_j) + l_{ij} \}\) 其中,\(l_{ij}\) 表示边的权重。
复杂度分析 ¶
void djikstra(const std::vector<std::vector<int>> &graph, int V,int src){
std::vector<int> dis(V,INF);
std::vector<int> visited(V,0);
dis[src] = 0;
for(int covered_node = 0 ; covered_node < n-1; covered_node++){//外层是n-1循环
int min = -1;
//find the closest node
for(int i = 0; i < V ; i++){
if(visited[i] != 1 && (min==-1||dis[i] <= dis[min])){
min = i;
}
}
visited[min] = 1;
for(int v = 0; v < V; v ++){
if(visited[v] == 0 && dis[min] != INF && graph[min][v] && dis[min]+graph[min][v] < dis[v]){
dis[v] = dis[min] + graph[min][v];
}
}
}
}
逐次逼近法 ¶

Bellman-Ford¶
它基于一个很基本的事实:对于一个不包含负权环的 V 个点的图,任意两点之间的最短路径至多包含 V-1 条边。
Bellman-Ford 算法大致可以分成三部分:
1. 初始化所有d[s] , 源点d[s]=0 , 其他d[s]=INF
2. 进行 n-1 次循环,在循环体中遍历所有的边,进行松弛计算
if( d[v] > d[u]+w[u][v] )
d[v] = d[u] + w[u][v]
3. 遍历图中所有的边,检验是否出现这种情况:d[v]>d[u]+w[u][v], 若出现则返回false , 没有最短路
#define inf 9999999
int s, v, e; // s为源点,v为顶点数,e为边数;
struct Edge{
int from, to, weight;
};
Edge edges[1000];
int dist[1000], pre[1000];
void bellman(){
for (int i = 0; i < v; ++i) dist[i] = inf;
dist[s] = 0;
for (int i = 1; i <= v - 1; ++i){//只需要n-1条边
for (int j = 0; j < e; ++j){//循环所有的边进行松弛
int u = edges[j].from, v = edges[j].to, w = edges[j].weight;
if (dist[u] + w < dist[v]){
dist[v] = dist[u] + w;
pre[v] = u;
}
}
}
}
SPFAShortest Path Faster Algorithm¶
【洛谷日报 #16】SPFA 算法教学 - 知乎 (zhihu.com)
最短路算法(Dijkstra + SPFA + Floyd) - 知乎 (zhihu.com)
最长路 ¶
- 正权边图中求最长路可使用 SPFA
- 经典 Dijsktra 可在全负权边图中跑最长路、全正权边图中跑最短路
最小生成树 ¶
最小生成树详解 ( 模板 + 例题 )_ 最小生成树算法 -CSDN 博客
prim 算法 ¶
基本思想:对图 G(V,E) 设置集合 S 来存放已被访问的顶点,然后执行 n 次下面的两个步骤 (n 为顶点个数 )
每次从集合 V-S 中选择与集合 S 最近的一个顶点 ( 记为 u),访问 u 并将其加入集合 S,同时把这条离集合 S 最近的边加入最小生成树。 令顶点u作为集合S与集合V-S连接的接口,优化从u能到达的未访问顶点v与集合S的最短距离
Kruskal 算法 ¶
1 初始化。将所有边都按权值从小到大排序,将每个节点集合号都初始化为自身编号。
2 按排序后的顺序选择权值最小的边(u,v
3 如果节点 u 和 v 属于两个不同的连通分支,则将边 (u,v) 加入边集 TE 中,并将两个连通分支合并
4 如果选取的边数小于 n-1, 则转向步骤 2,否则算法结束。
- 基本概念:包括邻接矩阵、权矩阵、树、网络等。
- 最短路径问题:包括 Dijkstra 算法、逐次逼近法和 Floyd 算法等。
- 最大流问题:研究如何在网络中找到最大的流量。
- 最大流和最小割问题:将整个流网络分割为两个割集。
- 最小消费流问题:在满足一定约束条件下,找到最小消费的流量。
最大流 ¶
定义与建模 ¶
可行流¶
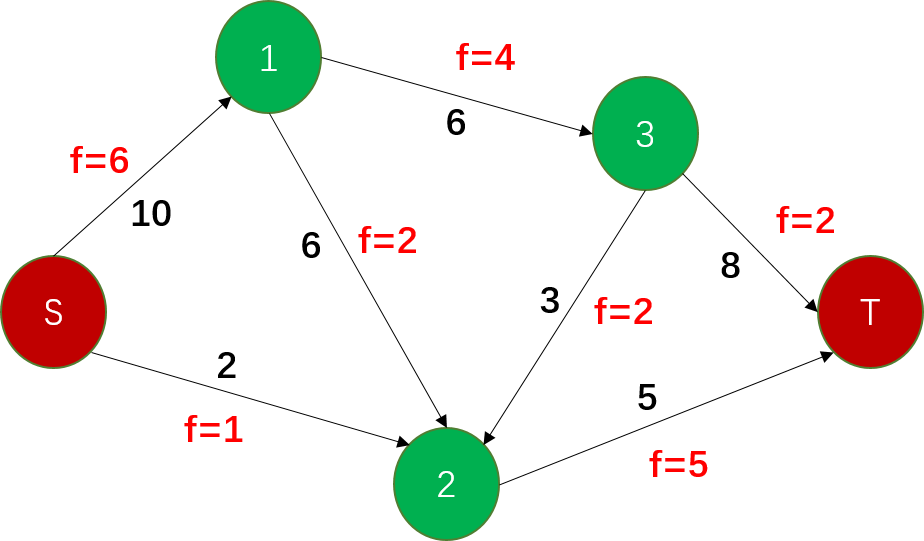
每条弧上给定一个实数 \(f(u,v)\)、,满足 \(0\le f(u,v)\le c(u,v)\)
可行流满足:
- 源点 S:流出量 = 整个网络的流量
- 汇点 T:流入量 = 整个网络的流量
- 中间的点:总流入量 = 总流出量,同时 \(0\le f(u,v)\le c(u,v)\)
车队送货问题
最大流¶
所有可行流中流量最大的流量
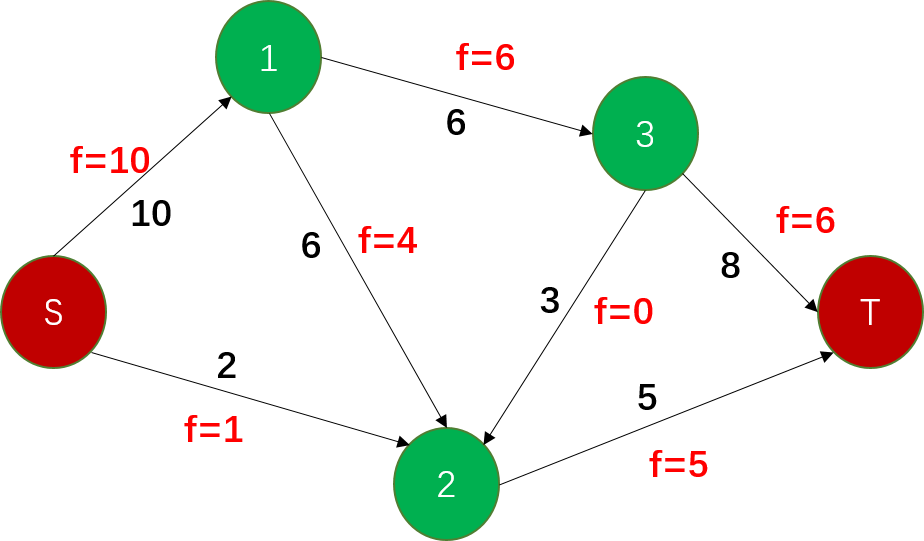
饱和 ¶
饱和边 / 不饱和边
反向饱和 / 不饱和
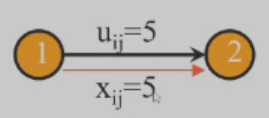
前向弧后向弧¶
前向弧:与链的方向相同
后向弧:与链的方向相反
增广链¶
设 f 是一个可行流,\(\mu\) 是从发点到收点的一条链,\(\mu\) 满足以下条件时为增广链 :
-
若弧 \((v_i,v_j)\) 是前向弧,则 \(0\le f_{ij} \le c_{ij}\),即 \(\mu^+\) 中每一条弧都要是非饱和弧
-
若弧 \((v_i,v_j)\) 是后向弧,则 \(0\le f_{ij} \le c_{ij}\) 即 \(\mu^-\)中每一条弧都要是非零流弧
可行流成为最大流的充分必要条件
不存在发点到收点的增广链
割集(Cut)¶
将网络中的点集 V 分成两个非空集合 \(V_1\)\(\bar{V_1}\),使得发点和收点位于两个集合,则弧集 \((V_1,\bar{V_1})\) 是分离发点和收点的割集
只要让源和汇不直接相连就可以了,如下图中 \((v_1,v_2),(v_3,v_4)\) 是一个割集
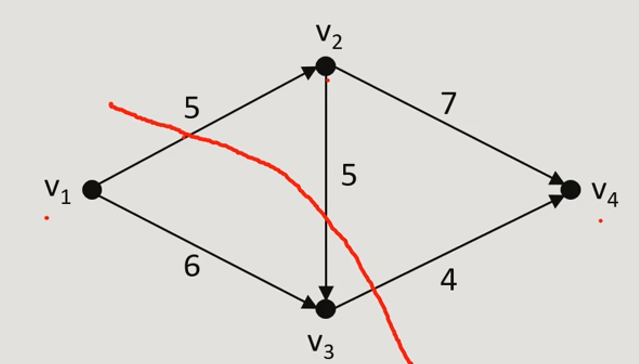
割量(Cut-set)¶
对于一个割集 S,割量就是 S 中所有边的容量之和。数学上,割量可以定义为:
割量可以用于描述网络流的瓶颈,即网络中限制流量通过的最小容量。在最大流问题中,最小割量等于最大流。
最小割集和最小割量
最大流最小割定理(Max-Flow Min-Cut Theorem)¶
该定理指出,在任何流网络中,从源点到汇点的最大流等于最小割量。这意味着要找到最大流,可以寻找一个将源点和汇点分开的割集,使得通过该割集的流量最小。
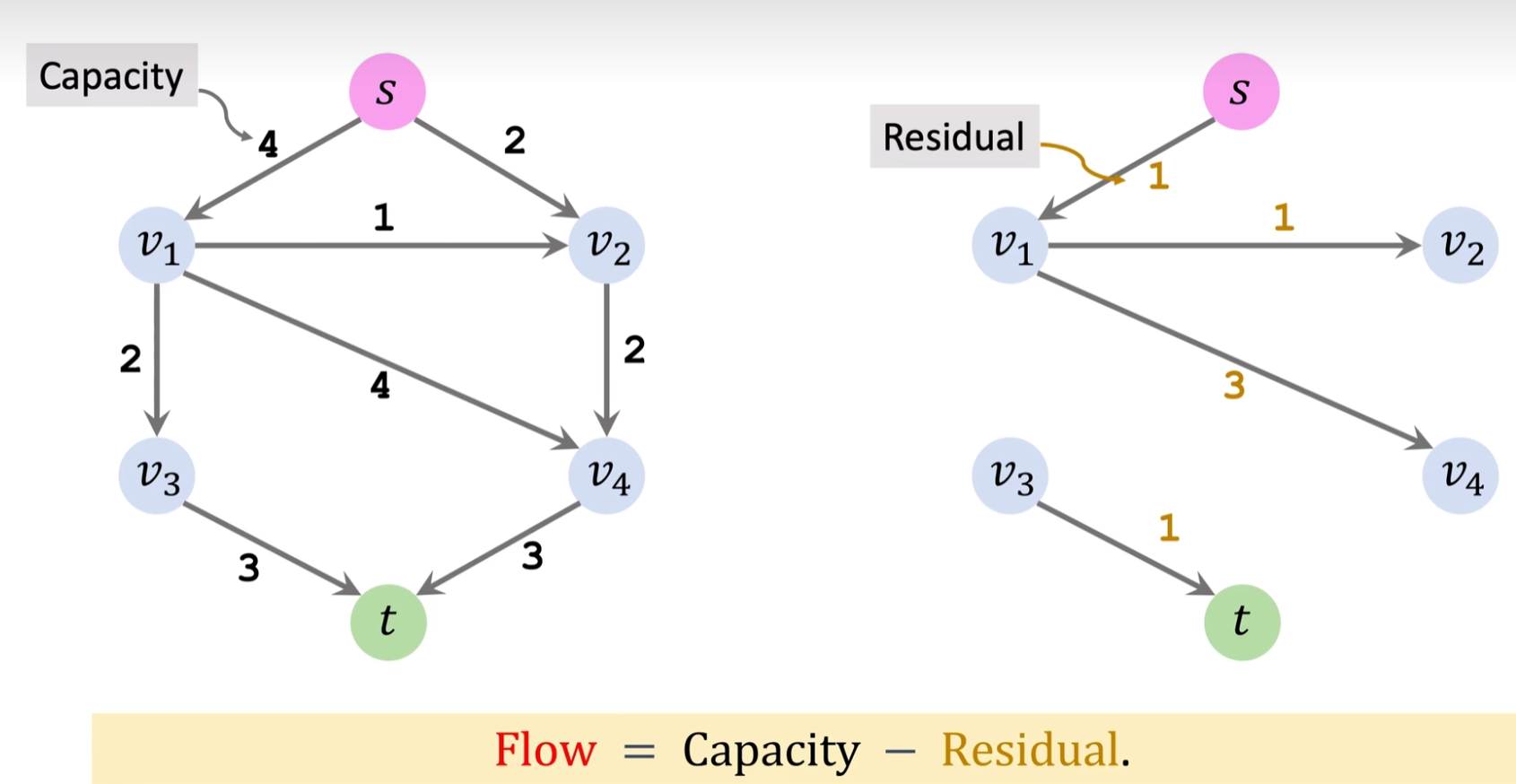
用 \(流量=容量-空闲\),可以得到阻塞流(blocking flow)
标号法 ¶
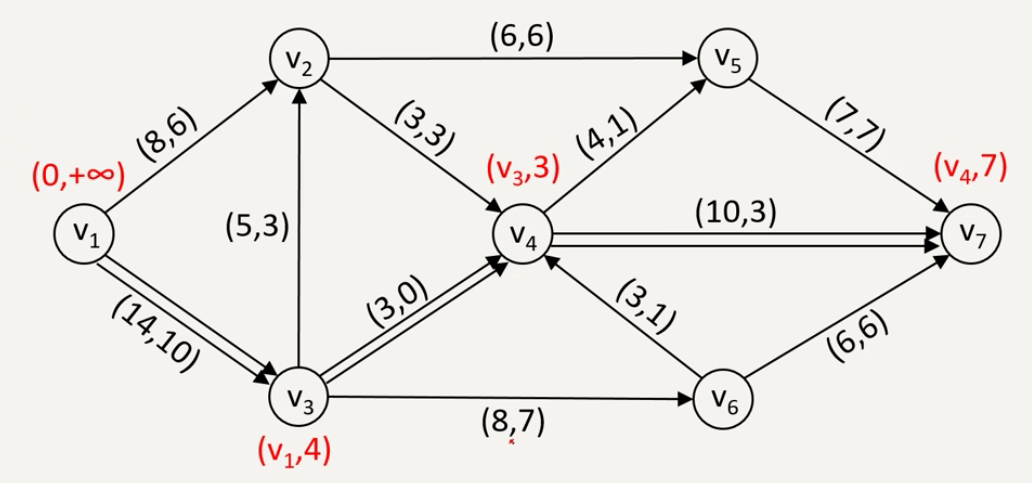
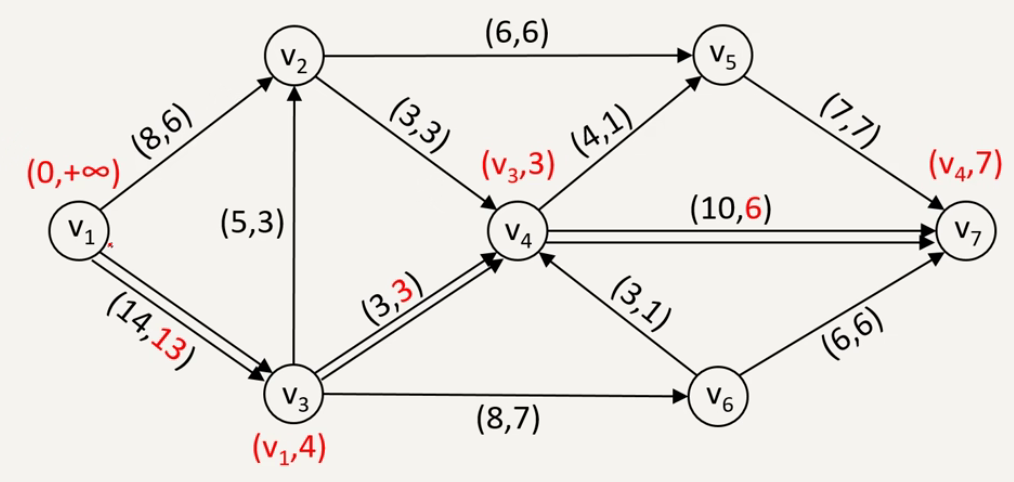
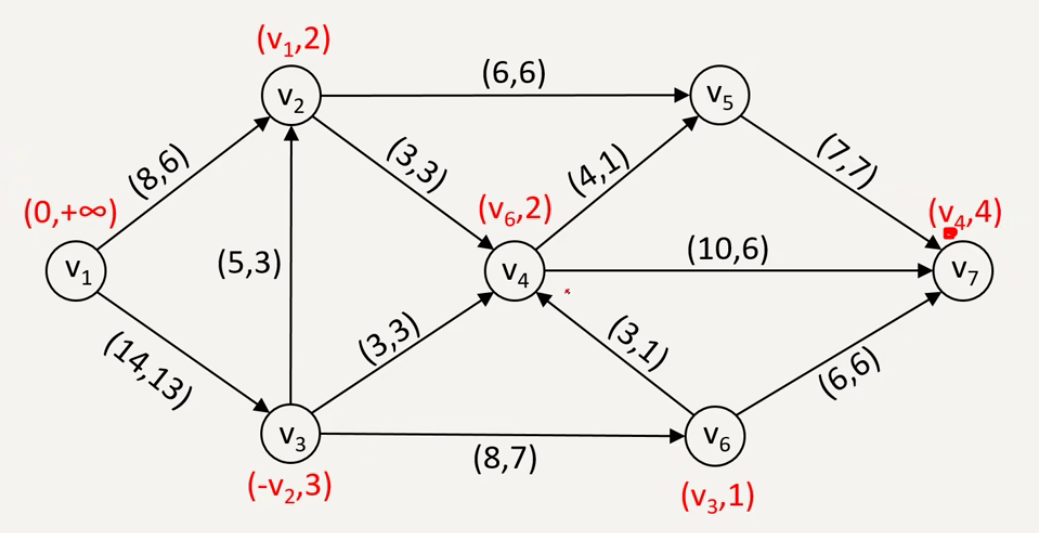
步骤一:
找出一个可行流(若网络中没有给定初始可行流,可设所有弧的流量 \(f_i=0\)
步骤二:标号以寻增广链
(1)发点标号 \(\{0,+\infty\}\)。
(2)选一个点 \(v\) 已标号且另一端点 \(u\) 未标号的弧沿着某条链向收点检查。
①若弧为前向弧,且 \(f_{ij}<c_{ij}\),则 \(u\) 标号 \(\{v_i,\theta_j\}\),\(\theta_j = c_{ij}-f_{ij}\)。
②若弧为后向弧,且 \(f_{ji}>0\),则 \(u\) 标号 \(\{-v_i,\theta_j\}\),\(\theta=f_{ji}\)。
(3)重复(2
步骤三:调整流量
(1)求增广链上所有标号点第二个标号的最小值,得到调整量 \(\theta=\min\limits_{i=1}^n \theta_i\)。
(2)调整流量:增广链上的前向弧 \(f_u=f_u+\theta\);增广链上的后向弧 \(f_u=f_u-\theta\)。
(3)得到新的可行流后,去掉所有有标号,重复步骤二、三,直到收点不能标号为正。
Ford-Fulkerson 算法 ¶
【运筹优化】网络最大流问题及三种求解算法详解 + Python 代码实现 _ 网络最大流问题例题详解 -CSDN 博客
该方法运用贪心的思想,通过寻找增广路来更新并求解最大流;
增加反向边的目的
可以反悔,去掉不好的路
在做增广路径时可能会阻塞后来的增广路径,换计划说,做增广路径本来是有一个顺序的,只有按照有这一顺序,才能知道最大流。
但是我们在寻找时是任意的,为了修正,我们就每次讲流量加入到了反向弧中从而让后面的流能够进行自我的调整。
$$ flow = capacity -residual $$ 残存网络其实就是用边的剩余容量来表示每条边,如下图所示的残存网络。S->v2这条边上的数字“2”代表这条边剩余可通过容量为2。
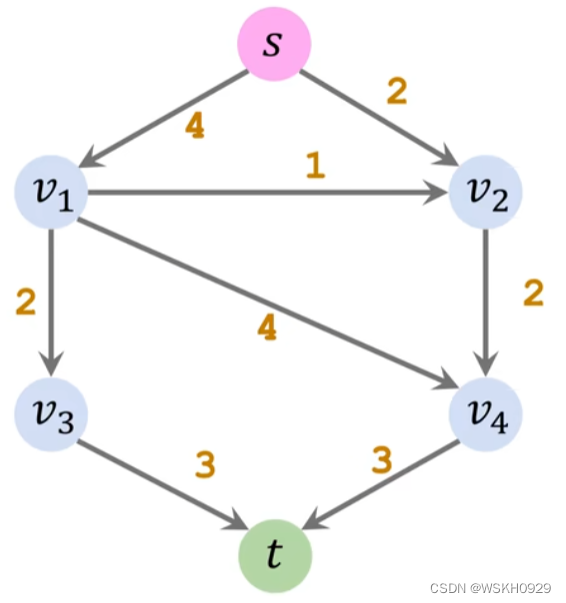
该算法概况起来,就是在残存网络中不断寻找增广路径,每找到一条增广路径,就递增最大流 \(f\),并更新残存网络,直到残存网络中不存在增广路径,则此时 \(f\) 即为最终的最大流。
Ford-Fulkerson 算法是通过 DFS(深度优先遍历)的方式在当前残存网络中寻找增广路径的。
根据木桶原理,增广路径的流量等于该路径的边的最小剩余流量。如下图所示的增广路径,它的流量就是 3,因为v4->t 的容量为 3
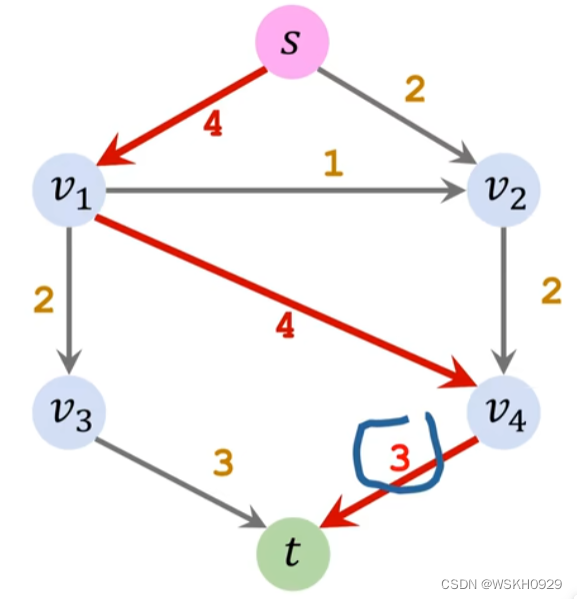
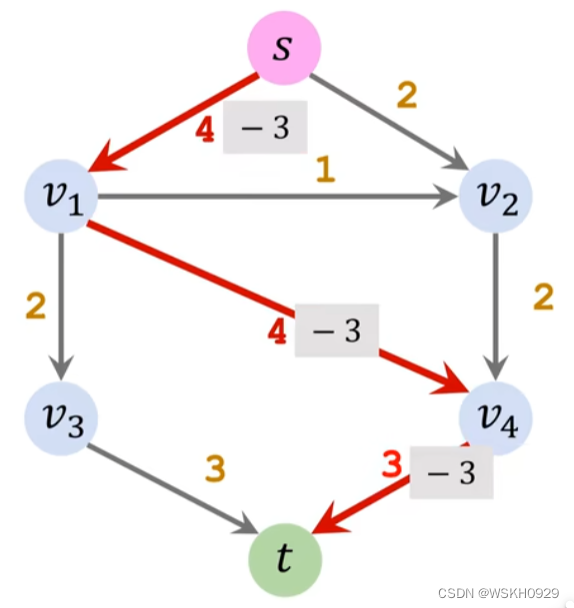
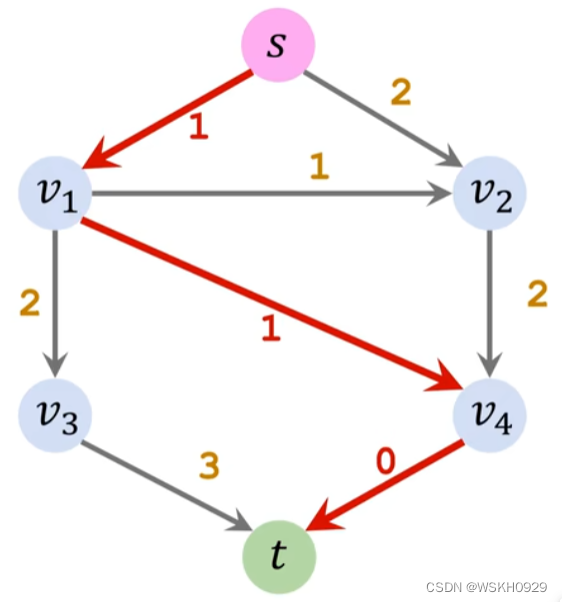
添加反向边是这一算法能够精确求解最大流问题的基础保障
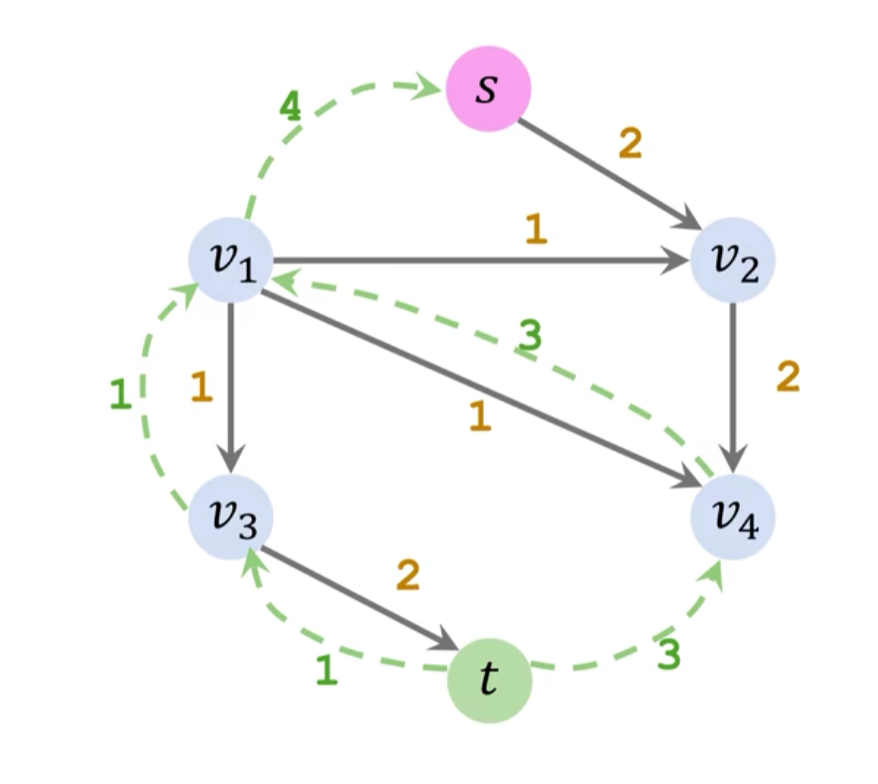
然后重复上述过程,直到找不到增广路径,算法结束
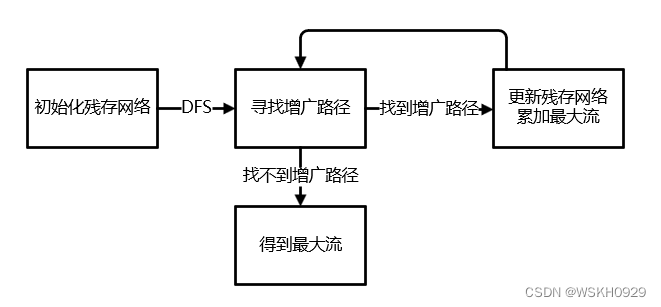
分析 ¶
最大循环次数 等于最大流,因为最坏情况下每轮循环流量只能增加 1
时间复杂度:最坏时间复杂度:\(O(\mathop{flow}\limits_{max}\times m)\),每一轮需要 \(O(m)\) 的时间找到路径
Edmonds–Karp 算法 ¶
Dinic 算法 ¶
最小费用流 ¶
最小费用最大流问题:在网络 \(G = (V, E)\) 上,对每条边给定一个权值 \(w(u, v)\),称为费用(cost
其中 \(f_g\) 是一个先验的值,当 \(f_g\) 为最小割容量的时候,是最小费用最大流问题
对于 \(G\)所有可能的最大流,我们称其中总费用最小的一者为最小费用最大流。
| 名称 | 特点 | 不足 |
|---|---|---|
| Bellman-Ford | 可以解决负权边,但不允许有负环 | 每次循环值均对所有元素进行松弛判断,造成许多不必要的操作。 |
| SPFA | 进阶版的 BF,使用队列进行优化,每次循环值选择当前节点相邻的若干节点进行松弛。在稀疏图上十分高效。 | 单路增广。SPFA 需要维护较为复杂的标号和队列操作,同时为了修正标号,需要不止一次地访问某些节点,速度会比较慢。 |
| 改进的 Dijkstra | 速度普遍比 SPFA 要快。 | 无法直接处理负权边图,需要对算法进行改进。 |
SSP 算法 ¶
SSP(Successive Shortest Path)算法是一个贪心的算法。它的思路是每次寻找单位费用最小的增广路进行增广,直到图上不存在增广路为止。
如果图上存在单位费用为负的圈,SSP 算法无法正确求出该网络的最小费用最大流。此时需要先使用消圈算法消去图上的负圈。
证明¶
我们考虑使用数学归纳法和反证法来证明 SSP 算法的正确性。
设流量为 \(i\) 的时候最小费用为 \(f_i\)。我们假设最初的网络上 没有负圈,这种情况下 \(f_0=0\)。
假设用 SSP 算法求出的 \(f_i\) 是最小费用,我们在 \(f_i\) 的基础上,找到一条最短的增广路,从而求出 \(f_{i+1}\)。这时 \(f_{i+1}-f_i\) 是这条最短增广路的长度。
假设存在更小的 \(f_{i+1}\),设它为 \(f'_{i+1}\)。因为 \(f_{i+1}-f_i\) 已经是最短增广路了,所以 \(f'_{i+1}-f_i\) 一定对应一个经过 至少一个负圈 的增广路。
这时候矛盾就出现了:既然存在一条经过至少一个负圈的增广路,那么 \(f_i\) 就不是最小费用了。因为只要给这个负圈添加流量,就可以在不增加 \(s\) 流出的流量的前提下,使 \(f_i\) 对应的费用更小。
综上,SSP 算法可以正确求出无负圈网络的最小费用最大流。
实现 ¶
只需将 EK 算法或 Dinic 算法中找增广路的过程,替换为用最短路算法寻找单位费用最小的增广路即可。