传输层 |Transport Layer ¶
约 5080 个字 预计阅读时间 20 分钟

原理 ¶
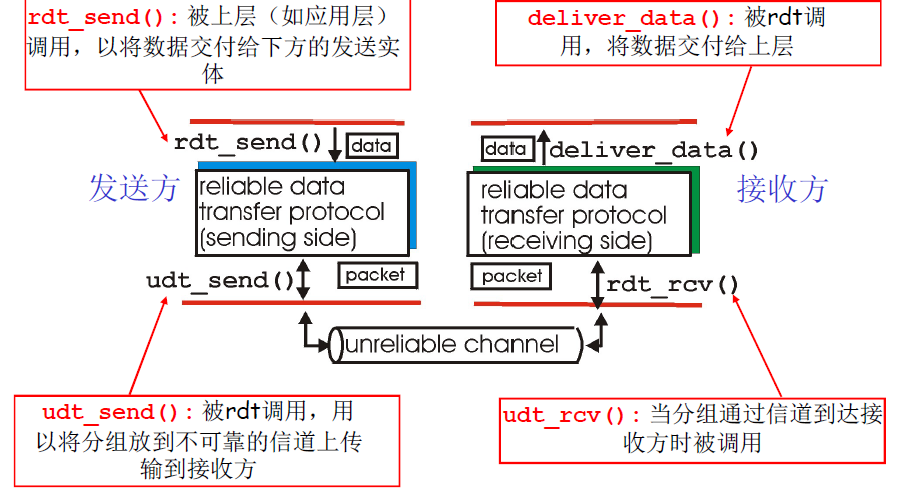
进程与进程之间 以 message 为单位的通讯
复用、解复用 ¶
多路分解
在接收端,运输层检查字段表示出接受套接字,从而将报文段定向到该套接字。将运输层报文段的数据交付到正确的套接字的工作。
接收方:将报文段重组成报文,然后传递给应用层
多路复用
在源主机从不同套接字中收集数据块,并为每个数据块封装上首部信息,从而生成报文段,然后将报文段传递到网络层
发送方:将应用层的报文分成报文段,然后传递给网络层
两个家庭互相寄信的例子
把源端的信件一团交给 postman
送到目标邮箱,从信箱里吧信件分装 →解复用
RDT 可靠数据传递 ¶
IP 是不可靠的,TCP 可以变成可靠的,在下层服务不可靠的情况下,向上保证可靠
FSM 有限状态机:引起状态变迁的事件 and 状态变迁时采取的动作
上层元语 + 本层动作 + 下层服务
Rdt1.0: 在可靠信道上的可靠数据传输 ¶
下层信道完全可靠,发送方和接收方的 FSM
-
发送方将数据发送到下层信道
-
接收方从下层信道接收数据
Rdt2.0:具有比特差错的信道 ¶
下层信道可能会出错:将分组中的比特翻转(01 互换
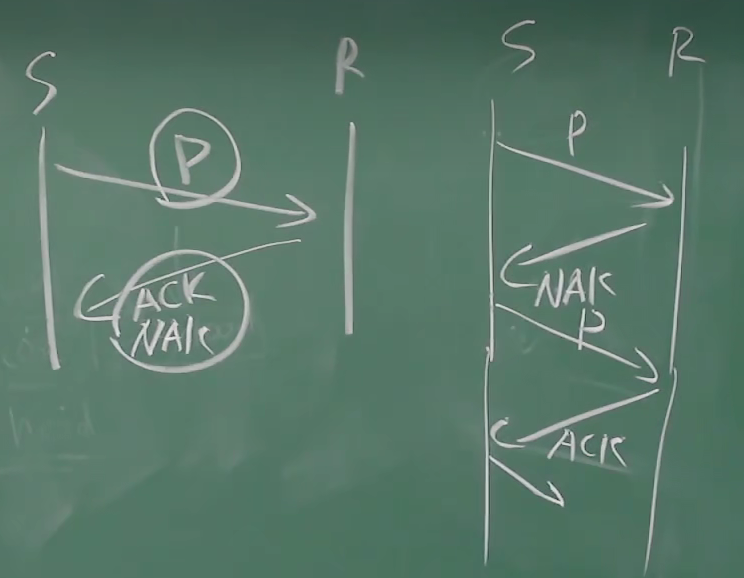
问题:怎样从差错中恢复:
- 确认 (ACK):接收方确认 - 什么都不做
- 否定确认 (NAK): 接收方声明出错,发送方重传分组
rdt2.1 ACK/NAK 出错(停等协议 ¶
加入分组序号:
-
对于发送方:每个分组中加入序号,不是 ACK 就重新发
-
接受方:检验和正确发送 ACK,再判断序号;检验和错误发送 NAK
Note
用一位表示分组的序号 没有确认的确认,如果下一次传了不同的分组,说明确认已经被发送方收到
rdt2.2:FREE NAK 无 NAK 的协议 ¶
郑老师有趣的例子:
:你说这个人漂不漂亮
:她很老实
对 ACK 做编号,对前一个分组 ACK 相当于当前分组反向确认
rdt3.0:alternating-bit protocol 具有比特差错和分组丢失的信道 ¶
发送方超时重传,重传时间略大约正常往返的时间
停等协议在信道容量大的时候效率较低
理解 合肥到北京高速公路:一个车过了到了北京才允许下一个车进入高速;但高速可以容纳很多车
adaptive 动态超时时间设置:过早超时可以运行,但效率低

流水线协议GBN &SR ¶
未得到对方确认,不停打分组,用多个 bit 表示分组
滑动窗口 (slide window) 协议
| 发送缓冲区 | 协议名称 | 最大 n | |
|---|---|---|---|
| SW = 1 | RW = 1 | stop and waiting | |
| SW > 1 | RW = 1 | GBN | \(2^n -1\) |
| SW > 1 | RW > 1 | SR | \(2^{n-1}\) |
发送缓冲区:内存中的一个区域,落入缓冲区的分组可以发送
发送窗口是发送缓冲区的一个子集
每发送一个分组,前沿前移一个单位;得到确认一个分组,后沿前移一个单位,不能够超过前沿
缓冲区大小:最大前沿 - 最小后沿
Go Back N¶
本部分参考 CSDN 博主岳麓山下你和我的文章【动图讲解】计算机网络之回退 N 步与选择重传 -CSDN 博客
其使用的动画网站是自顶向下的官方动画 Go-Back Protocol 动画演示
郑老师讲解视频动画展示回退 N 步(GBN)协议
-
丢失的话,回到最小次序的分组,go back 到没有确认的点,重新发送后续
-
接收方缓冲区为 1;顺序到来最高的发确认,累积确认;只维护一个定时器
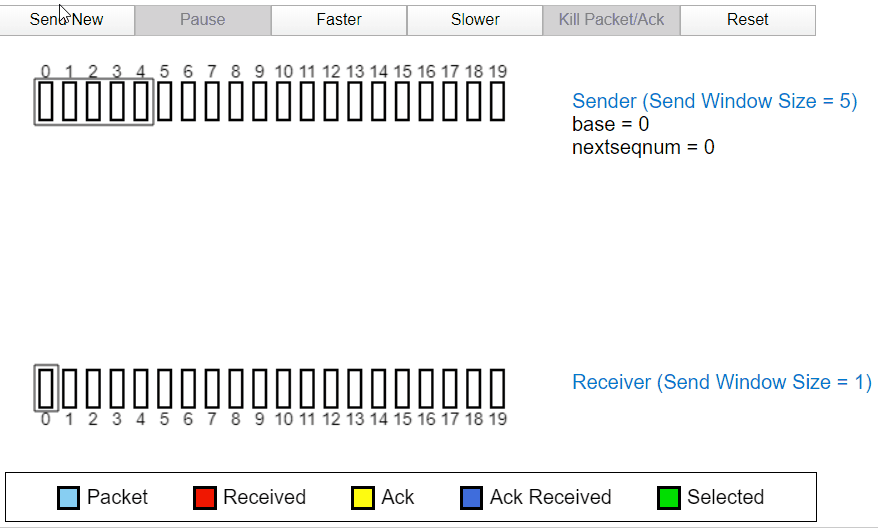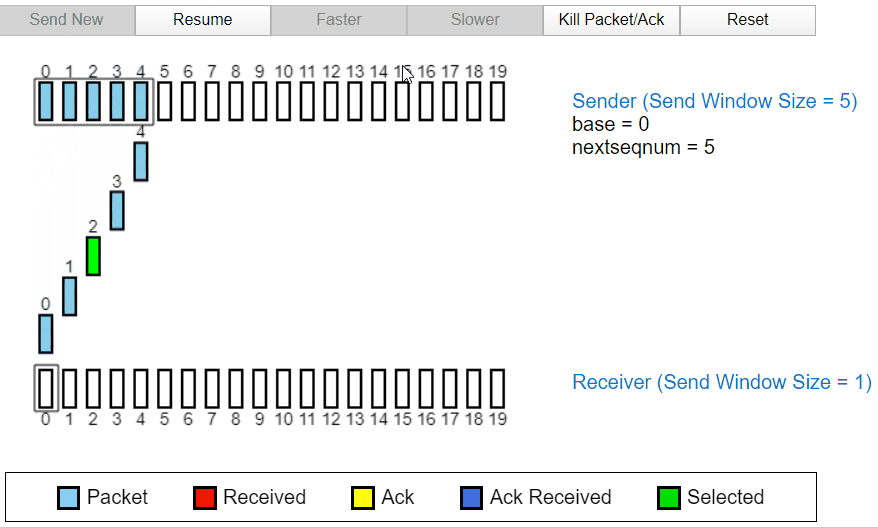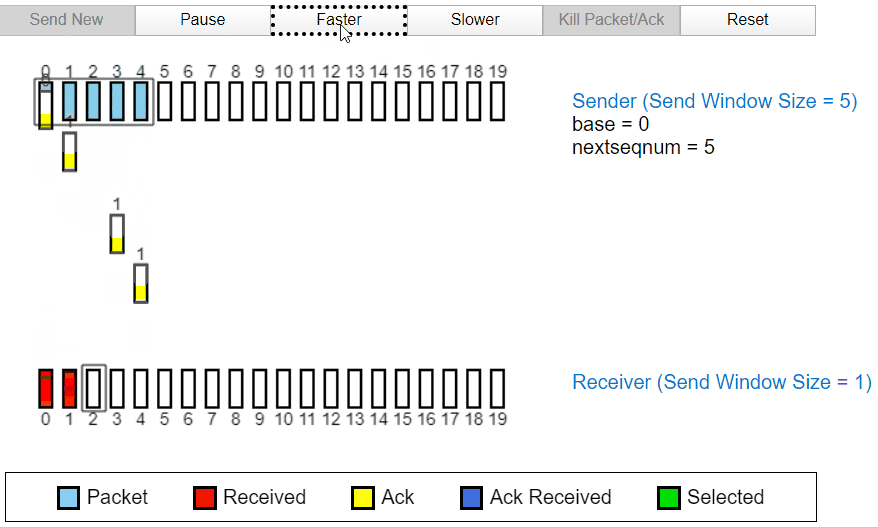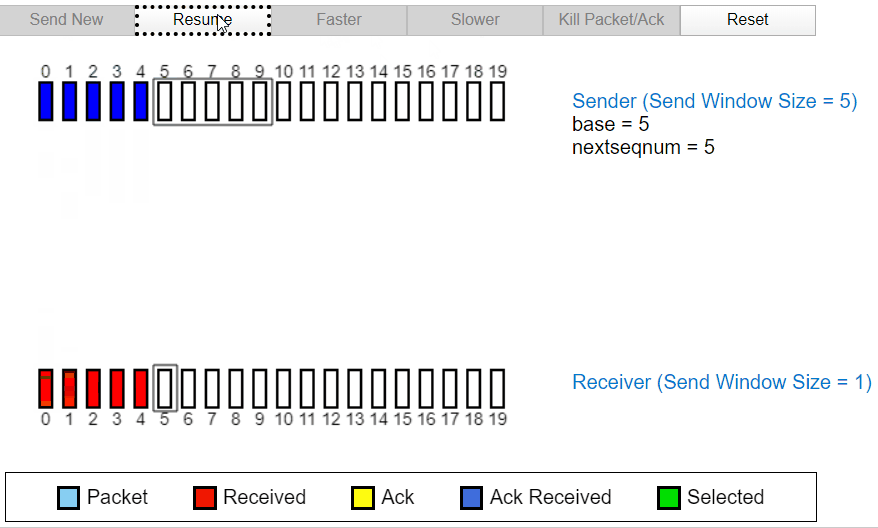
正常工作
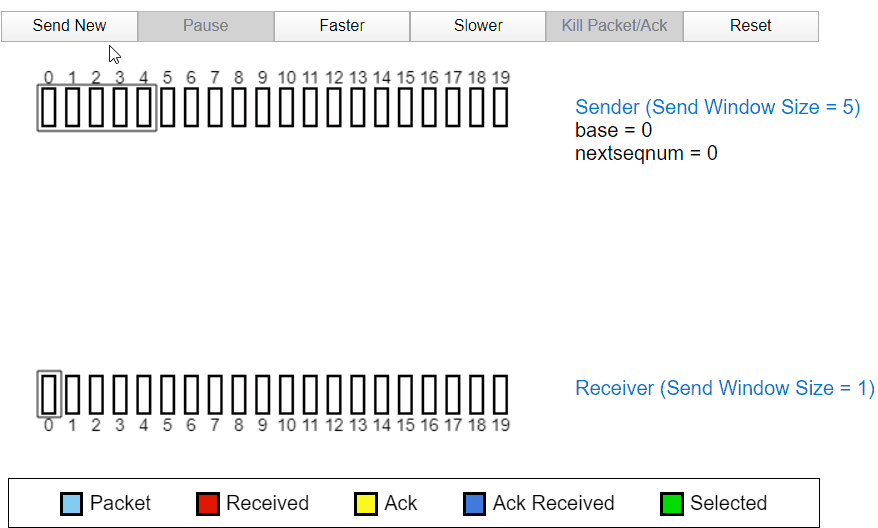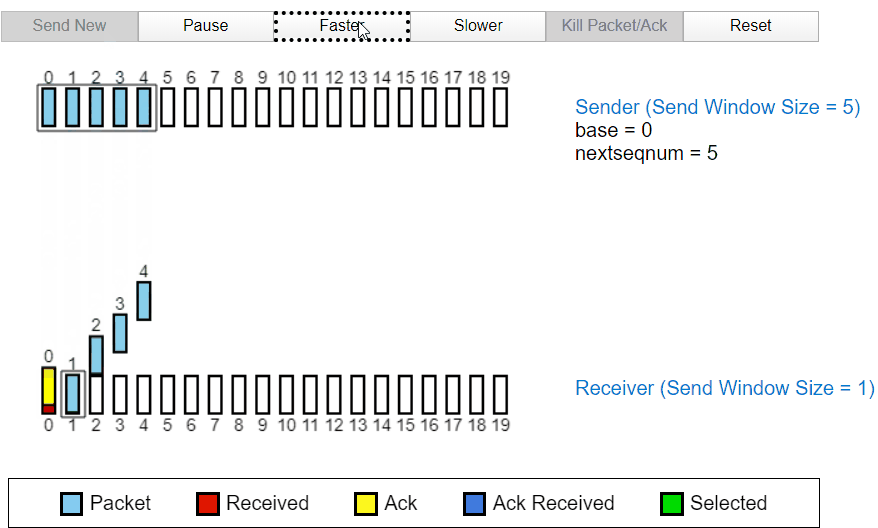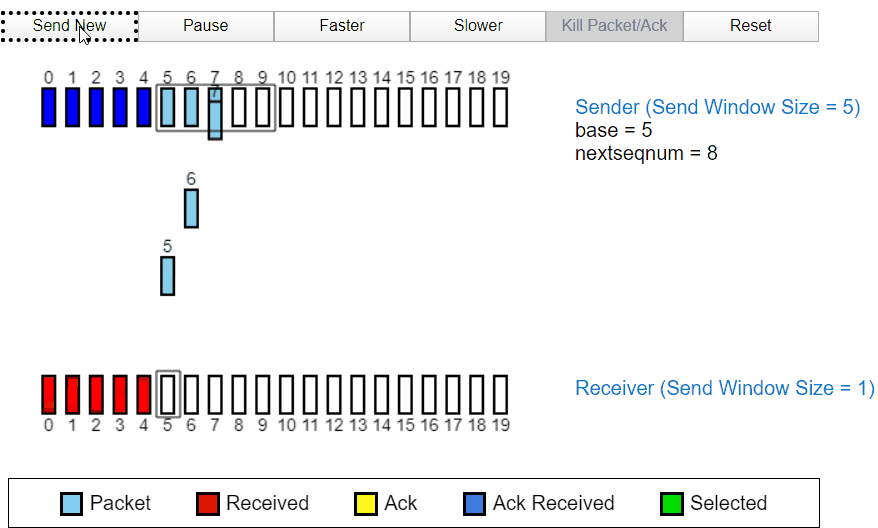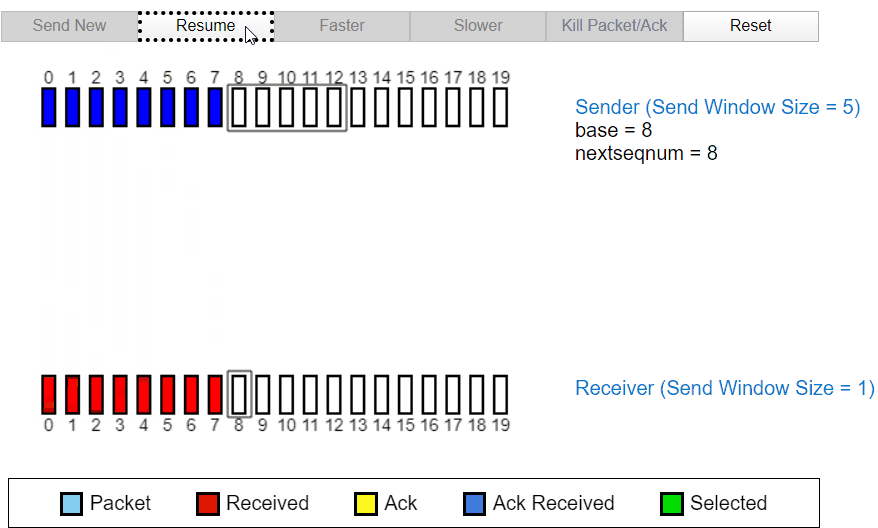
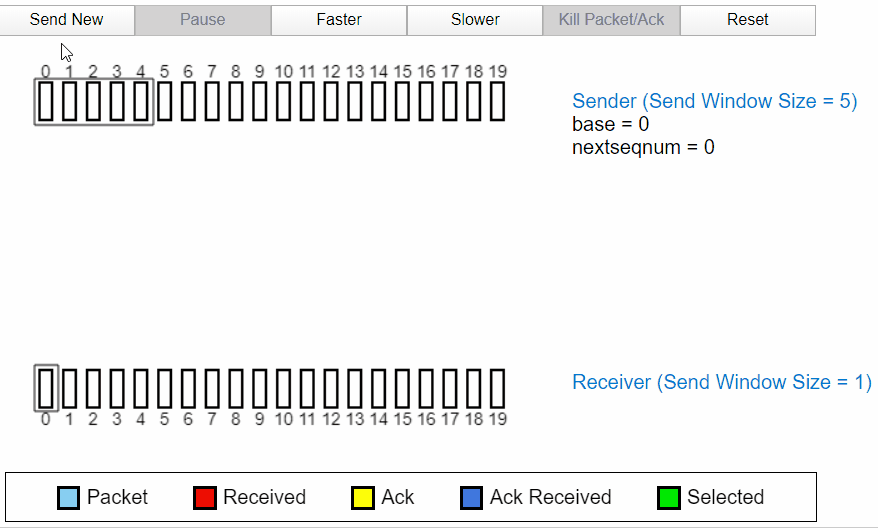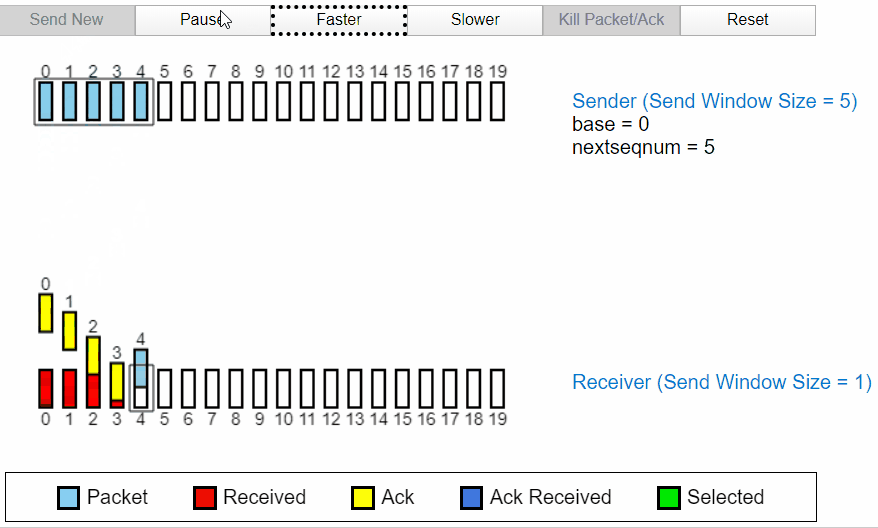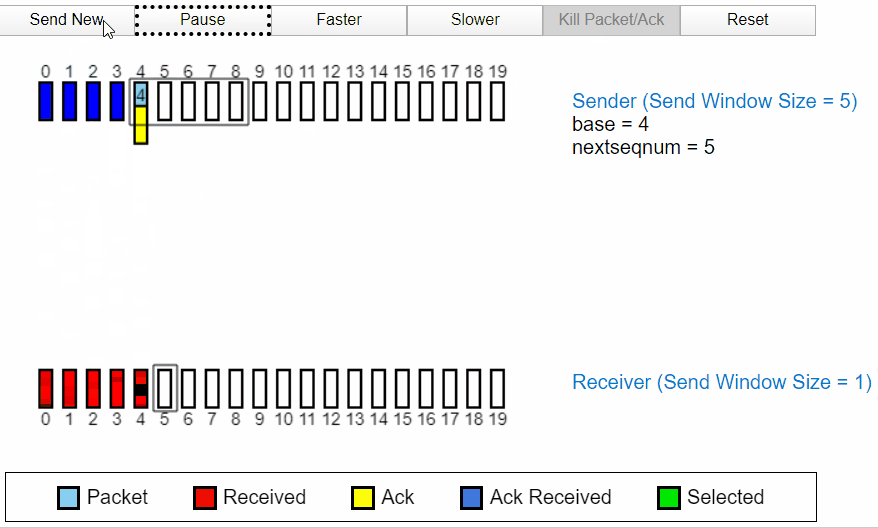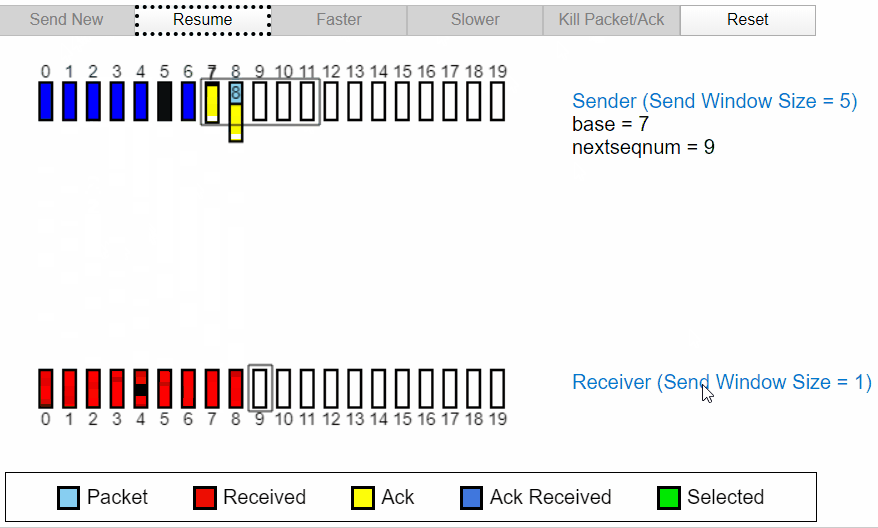
当发送过程中发生丢包
当发送过程中的 2 号包发生丢失时,发送方没有收到接收方的 ACK2,于是后面发送的 ACK3,ACK4 全部变成了 ACK1,代表接收方因为丢失了分组 2,所以分组 3 和分组 4 都被丢弃。所以全部返回 ACK1,经过一段时间后,定时器确认超时没有收到 ACK3,ACK4,所以发送方将重新发送。也代表接收方首先只收到了分组 1 及之前的包。
当接收过程中发生丢包
本次返回的为 ACK3,ACK4,所以发送方可以判断接收方已经接收到消息,不再进行重复发送。
Selective Repeat¶
SR 单独发送没有收到的
非累积确认;对到来的分组逐一确认;维护每一个点的定时器
滑动窗口的滑动,低序号到来,高序号提前到来要缓存
单个分组的差错就能够引起 GBN 重传大量分组,许多分组根本没必要重传。 随着差错率的增加,流水线可能会被这些不必要重传的分组占满,造成效率的低下。
发送过程中丢包
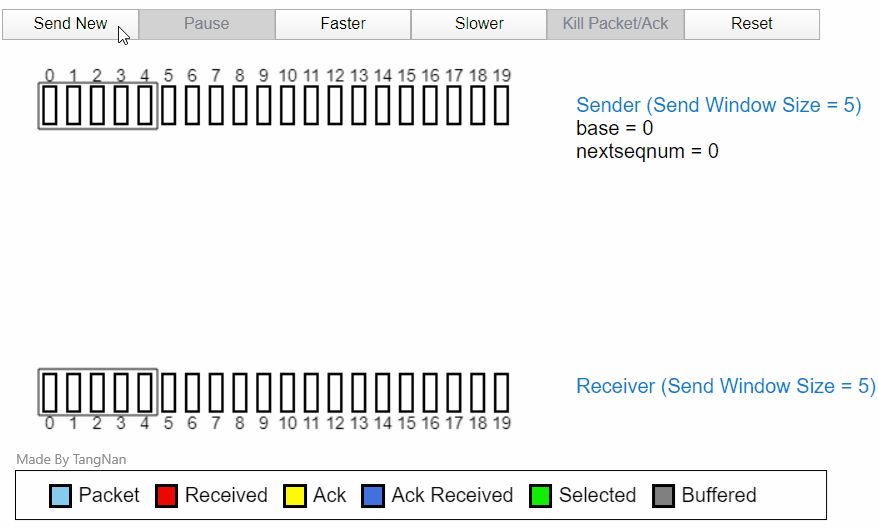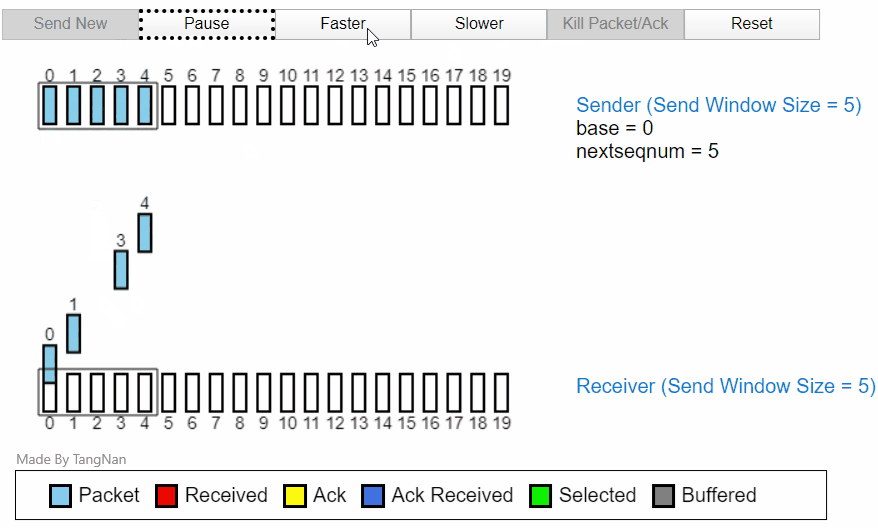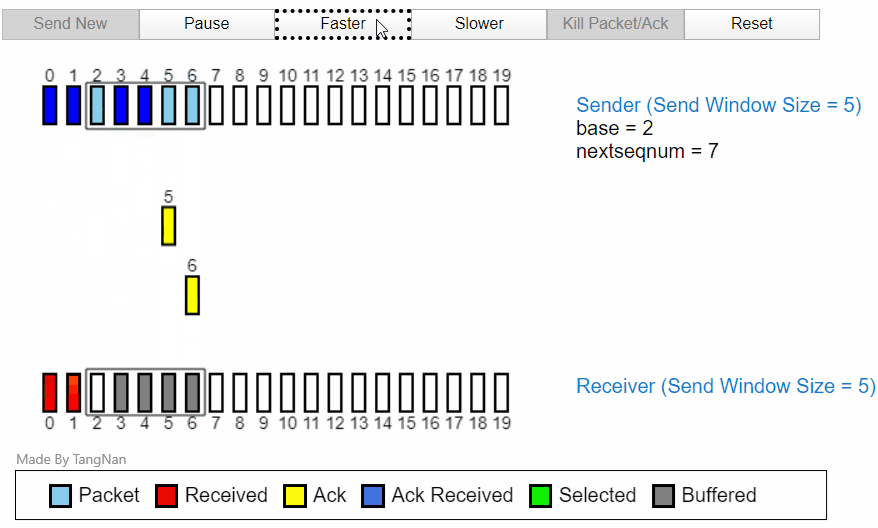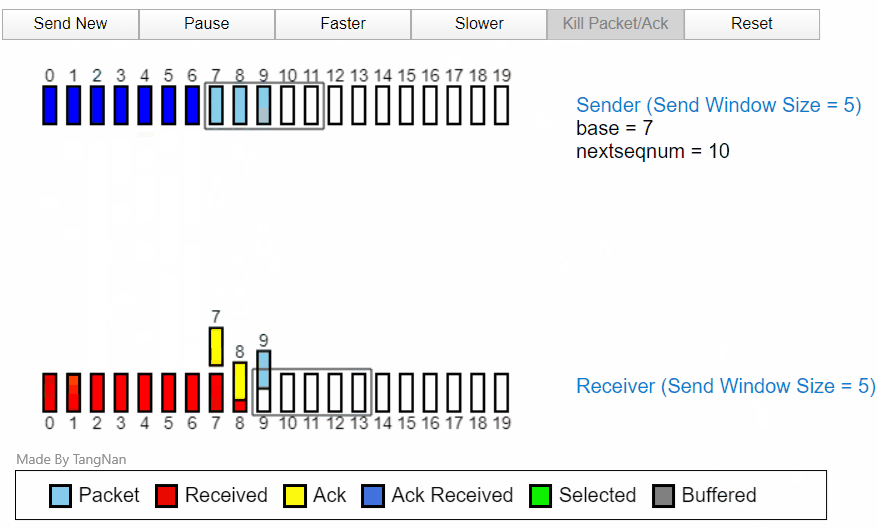
当所以ACK1返回以后,分组 5,分组 6 就已经可以发送。然后在接收方,分组 3456 都已经被缓存,等待分组 2 的计时器超时后,分组 2 将重新发送,然后在接收方的分组 23456 全部变为接收received状态。
接收过程丢包
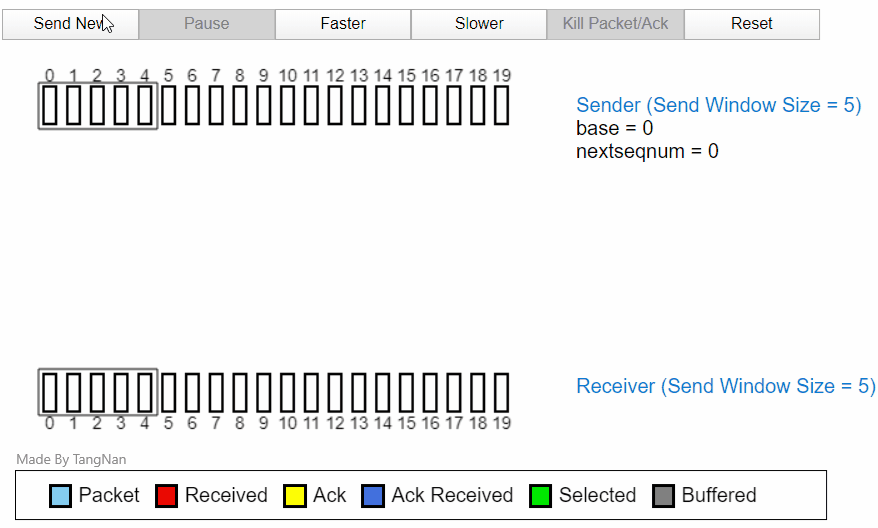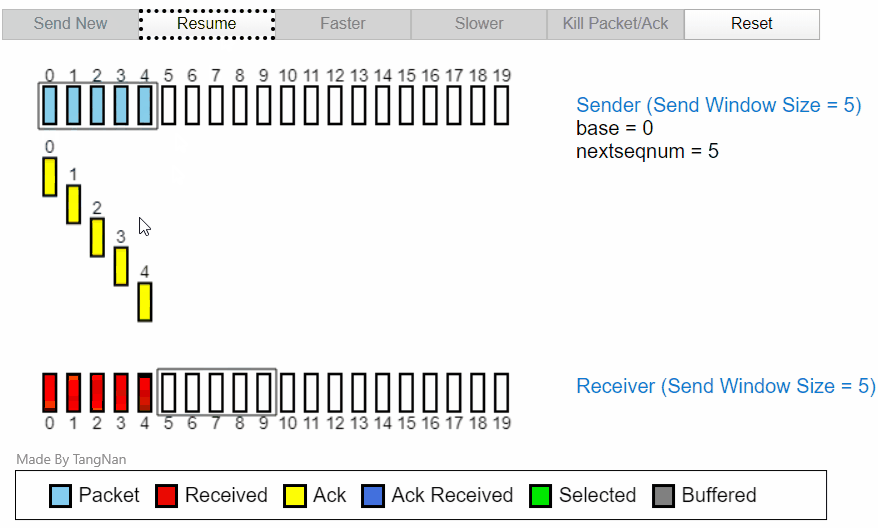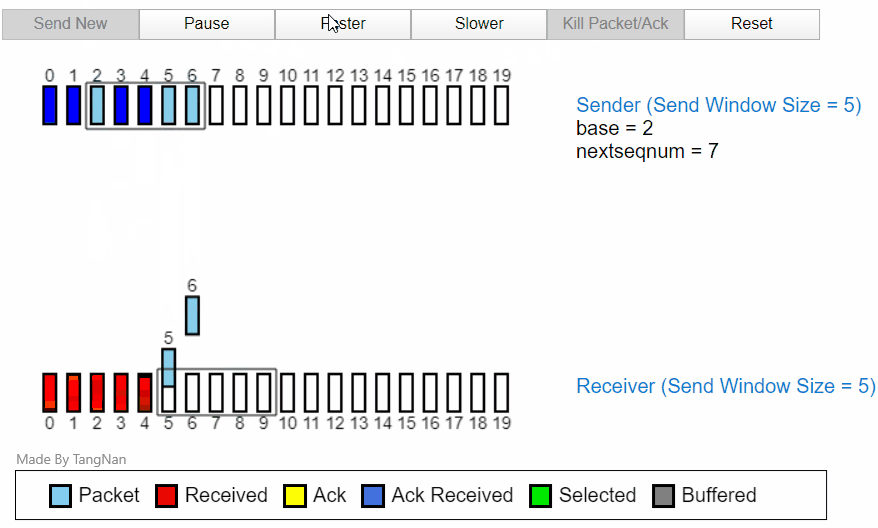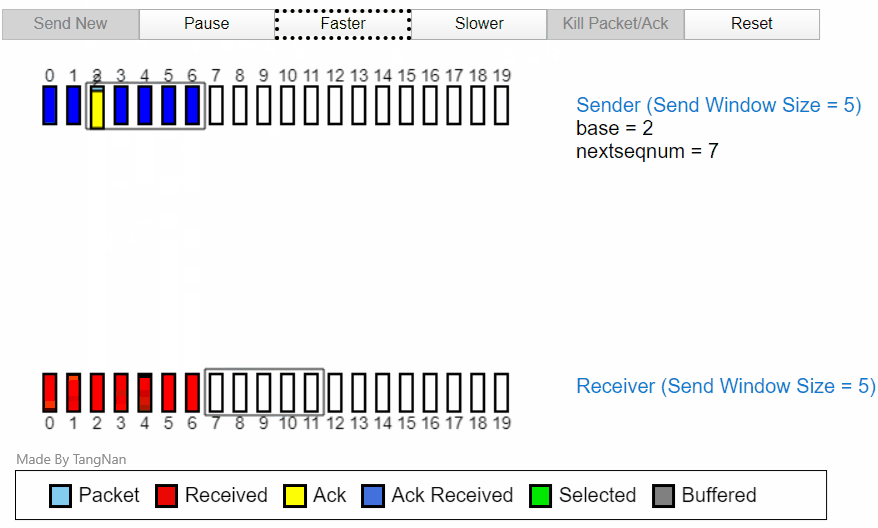
分组 2 会因为 ACK2 被丢失,在计时器计时后重新发送一次。
可以看到如果在接收过程中有丢失发生,选择重传 SR 的效率是不如回退 N 步 GBN 的。
适用范围 ¶
- 出错率低:比较适合 GBN,出错非常罕见,没有必要用复杂的 SR,为罕见的事件做日常的准备和复杂处理
- 链路容量大(延迟大、带宽大
) :比较适合 SR 而不是 GBN,一点出错代价太大
拥塞控制 |congestion control ¶
太多的数据需要网络传输,超过了网络的处理能力
表现:丢失;延迟 ¶
分组丢失 ( 路由器缓冲区溢出 );分组经历比较长的延迟 ( 在路由器的队列中排队 )
不加控制,加速拥塞
选中一条数据报,点击统计( Statistic s)-> TCP 流图形 -> 时间序列( Stevens ),观察图形。判断此文件中是否有重传的区段(序列号一直增大则无,反之则有)
原因 ¶
- 场景 1
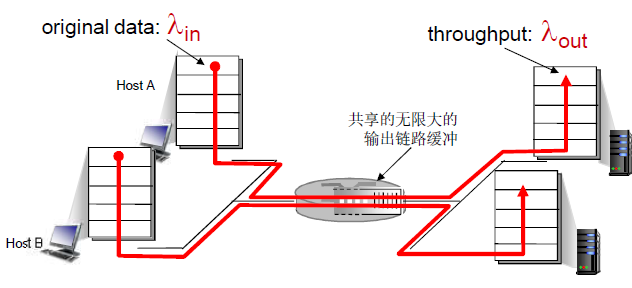
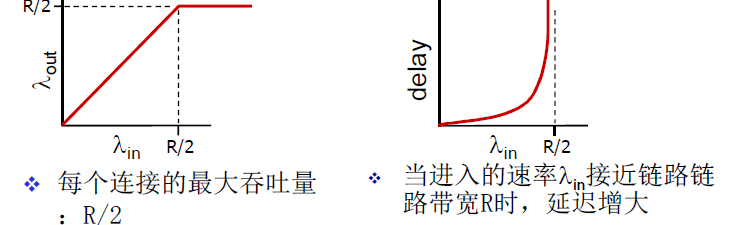
- 场景 2:有限缓存;超时重传的比例增加
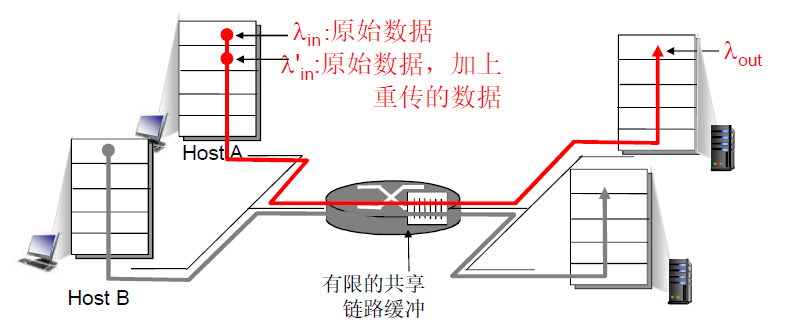
- 场景 3:被抛弃的分组在拥塞的时候已经穿过了一个或若干个路由
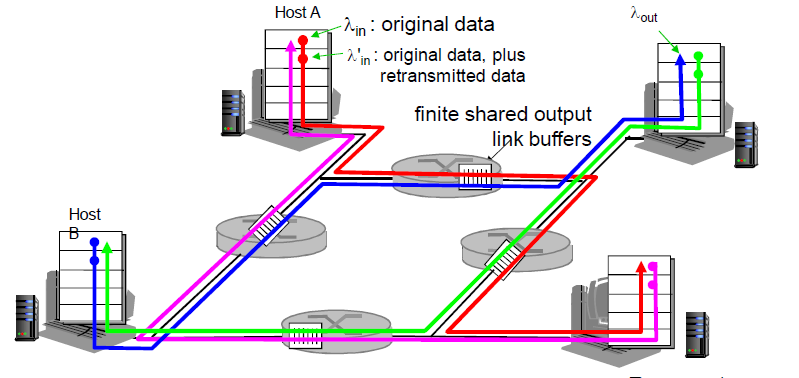
代价 ¶
-
延迟高
-
拥塞的时候灌入速率要快
开洗衣店,需要返工比例高,洗衣服的速度提高才能保证完成任务
-
发出了很多没有必要的,因为超时而重传的分组,加速拥塞
-
当分组丢失时,任何“关于这个分组的上游传输能力”都被浪费了
控制手段 ¶
-
网络提供信息给端系统,控制速率
-
端系统自己判断;段超时、收到冗余 ACK
ABR: available bit rate:
“弹性服务”
- “轻载”:发送方使用可用带宽
- 发送方拥塞:速度限制到一个最小保障速率上
RM ( 资源管理 ) 信元 :
网络是否发生拥塞的标志位
由发送端发送 , 在数据信元中间隔插入 RM信元中的比特被交换机设置(“网络辅助”)
-
NI bit: no increase inrate( 轻微拥塞 ) 速率不要增加了 -
CI bit: congestion indication拥塞指示 ER (explicit rate)字段:发送端发送速度因此是最低的可支持速率
通过反馈方式让源主机知道最小的带宽
协议 Protocol ¶
UDP | User Datagram Protocol¶
[RFC 768] 用户数据报协议
实时性
特点¶
无连接、不可靠、无流量控制、无拥塞控制
不需要握手,头部占比小开销小,简单
应用于:
- 流媒体(丢失不敏感,速率敏感、应用可控制传输速率)
- DNS
- SNMP
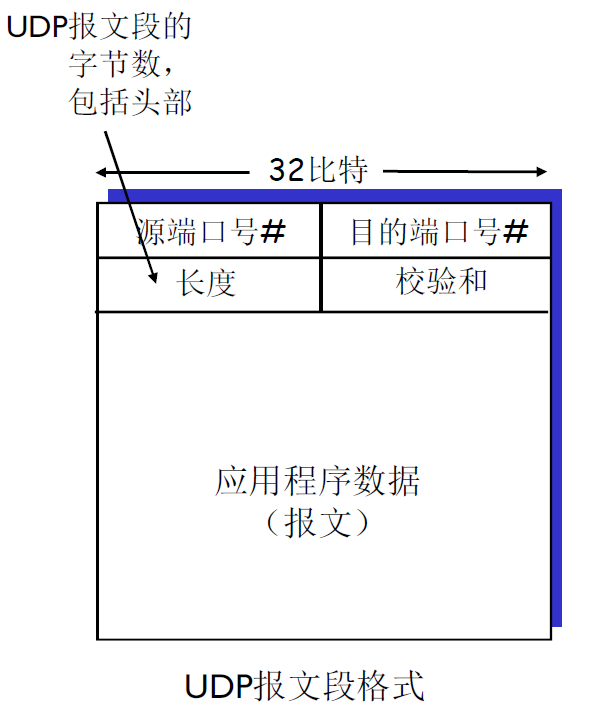
报文 ¶
- 8 字节头部——2 字节源端口号、2 字节目的端口号、数据长度(包括头部
) 、校验和 EDC。 - 报文部分——校验和出错后全部丢掉。
以datagram为单位
UDP 校验和 ¶
本部分参考了博文关于 UDP 的检验和计算
看了郑老师的视频 TCP 和 UDP 校验和
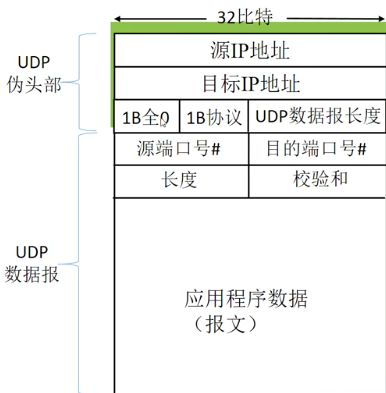
发送方:加法 + 进位回滚 + 最后的和取反码
- 填上伪头部,校验和一开始全 0,将报文段的内容全零;分成 16 比特的整数
- 伪头部 + 头部 + 数据采用二进制反码求和
- 检验和:把上一步结果的反码填入检验和
- 去掉伪头部,发送

接收方:
-
填上伪首部
-
伪首部 + 首部 + 数据部分采用二进制反码求和
-
检查:
-
不是全 1 —— 检到差错
-
全 1 —— 没有检测到差错,但也许还是有差错残存错误 ( 概率小 )
注意
之前在操作检验和的过程中 , 我一直有一个误解 , 那就是计算时都把数据当成源码 , 取反再进行上述规则的运算
但其实不是这样的, 数据本身就以"反码"形式存在, 直接按此规则计算即可.
简单来说, 对于图中的检验和计算过程, 就是这样的:
把数据视为无符号16位整数相加, 如果产生了进位,则需要额外加1
TCP¶
传输控制协议
面向连接的 (connection-oriented)、点对点的
reliable: 不重复、不乱序、不丢失、不出错
TCP 报文 ¶
packet为单位
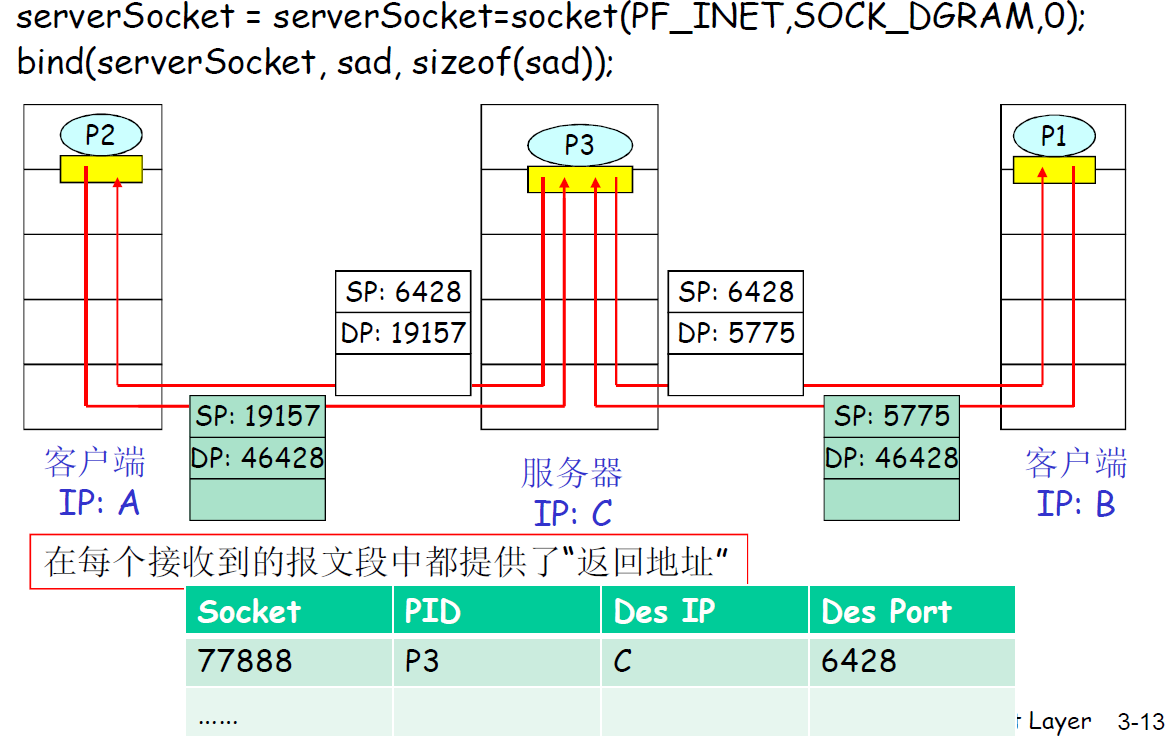
socket是一个整数 记录四元组:本地 ip+port 对方 ip+port 进程 PID
message + 本地 port + 对方 port 形成 TCP 数据报
再加上本地 ip + 对方 ip 形成 IP 数据报文
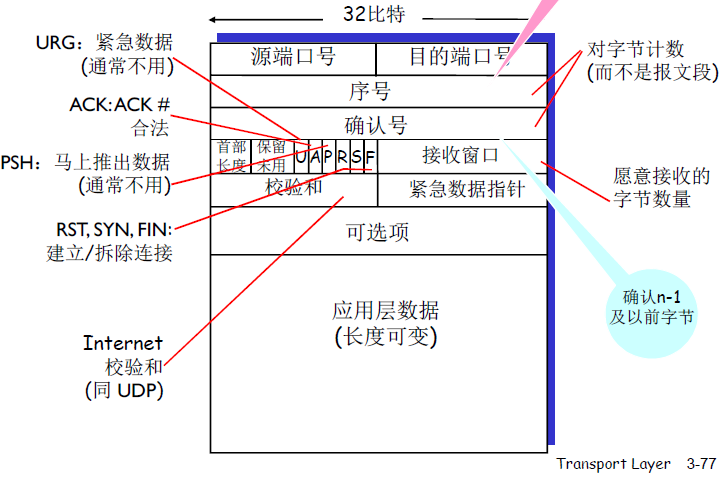
重要字段
- 序号 (sequence number):seq 序号,占 32 位,用来标识从 TCP 源端向目的端发送的字节流,发起方发送数据时对此进行标记。
- 确认号(acknowledgement number):ack 序号,占 32 位,只有 ACK 标志位为 1 时,确认序号字段才有效,ack=seq+1。
- 标志位(Flags):共 6 个,即 URG、ACK、PSH、RST、SYN、FIN 等。具体含义如下:
SYN:发起一个新连接。ACK:确认序号有效。 (为了与确认号 ack区分开,我们用大写表示)只有当ACK=1时,确认号字段才有效;当ACK=0时,确认号无效。RST:重置连接。FIN:释放一个连接。PSH:接收方应该尽快将这个报文交给应用层。URG:紧急指针(urgent pointer)有效。CWR:( 拥塞窗口减小 ) 缓存区已满或者拥挤,通信双方都应该降低传输的速率。
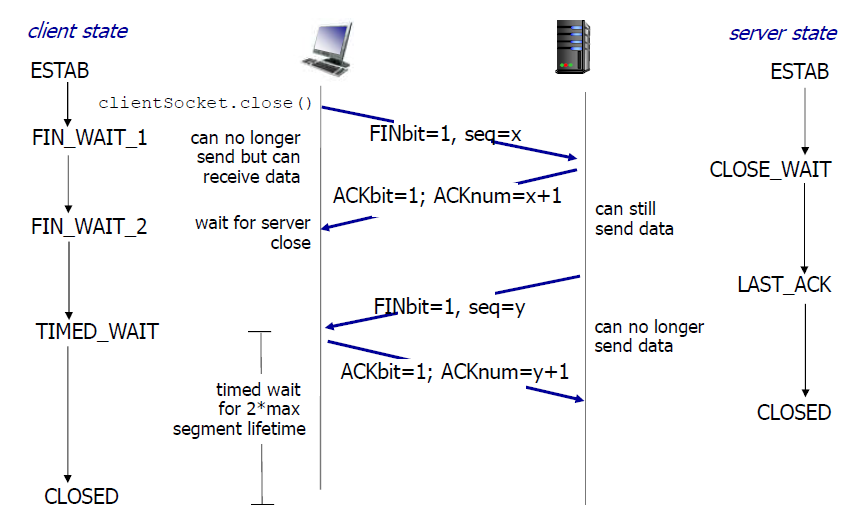
建立连接 ( 三次握手 ) ¶
与 ACK 序号有关的时间序列图
双方知道和对方通信;要准备一些必要的资源
发送方:老铁,可以听得到我说话吗,老铁。
接收方:可以听到,你听得到吗?
发送方:听到了,那我开始说正事了。
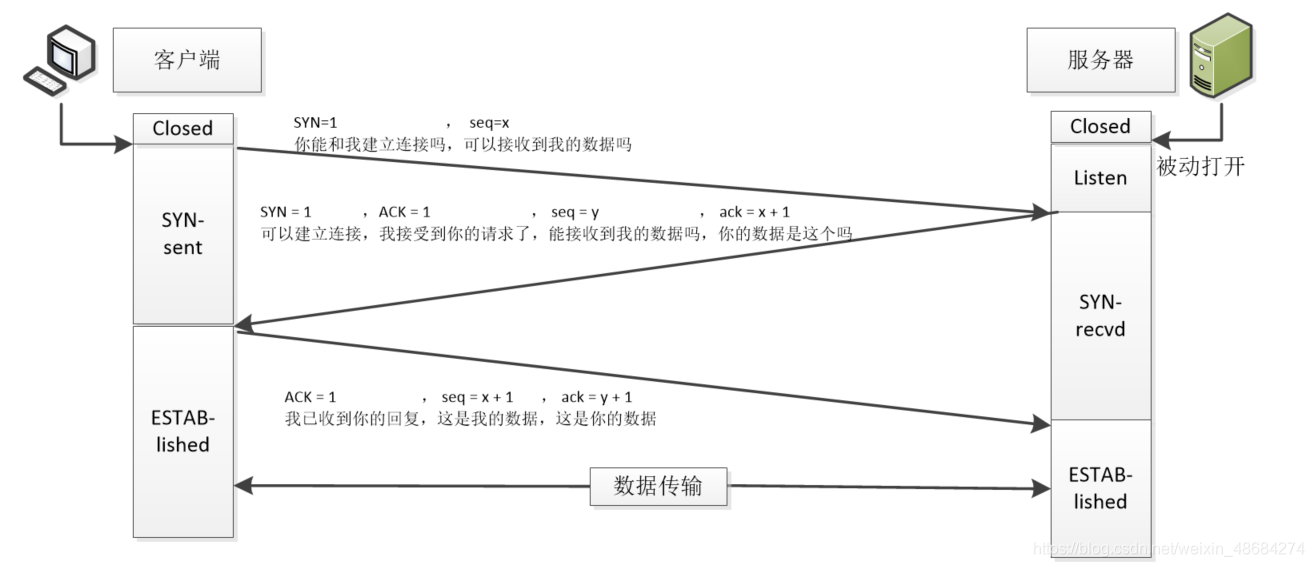
第一次握手
探测是否可以进行通信,告诉客户端 seq X
客户端将标志位 SYN 置为 1 ,随机产生一个值SEQ = X,并将该数据包发送给服务器,客户机进入 SYN_SENT 状态,等待服务器确认;
第二次握手
是接收方返回给发送方的,可以明确一些信息 ;
确认X,告诉服务器seq Y;相当于把确认和seq Y 捎带发送了
服务器收到数据包后由标志位SYN = 1,知道客户端请求建立连接,服务器将标志位 SYN 和 ACK 都置为 1 ,ACK = X + 1,随机产生一个值SEQ = Y,并将该数据包发送给客户端以确认连接请求,服务器进入 SYN_RCVD 状态;
第三次握手
确认seq Y,Y 是 server 维护的滑动窗口的下沿;和数据传递同步进行
客户端收到确认后,检查 ACK 是否为X + 1,ACK 是否为 1 ,如果正确则将标志位 ACK 置为 1 ,ACK = Y + 1,并将该数据包发送给服务器,服务器检查 ACK 是否为K + 1,ACK 是否为 1 ,如果正确则连接建立成功,客户端和服务器进入 ESTABLISHED 状态。
握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据。理想状态下,TCP 连接一旦建立,在通信双方中的任何一方主动关闭连接之前,TCP 连接都将被一直保持下去。
服务器把老的连接当成新的连接
初始序号的选择;与时钟的第一个 32 位有关;
关闭连接 ( 四次挥手 ) ¶
分成两个方向分别拆除;
连接释放是不可靠的
启动一个定时器,如果定时器结束之前没有数据传递,那么通信就真正关闭了
超时定时器 ¶
设置不合理效率较低,重复发送
- 如果比较集中,就可以设置一个具体的数值,例如 \(\mu + 4\sigma\)处;如局域网
- 如果数值不确定,那么 adaptive 动态调整;定期测量往返延时
adam算法一阶动量计算
$$
EstimatedRTT = (1-alpha) times EstimatedRTT + alphatimes SampleRTT
$$
- 指数加权移动平均
- 过去样本的影响呈指数衰减
- 推荐值:\(\alpha = 0.125\)
重发像 SR,把最老的段重传;
累积确认
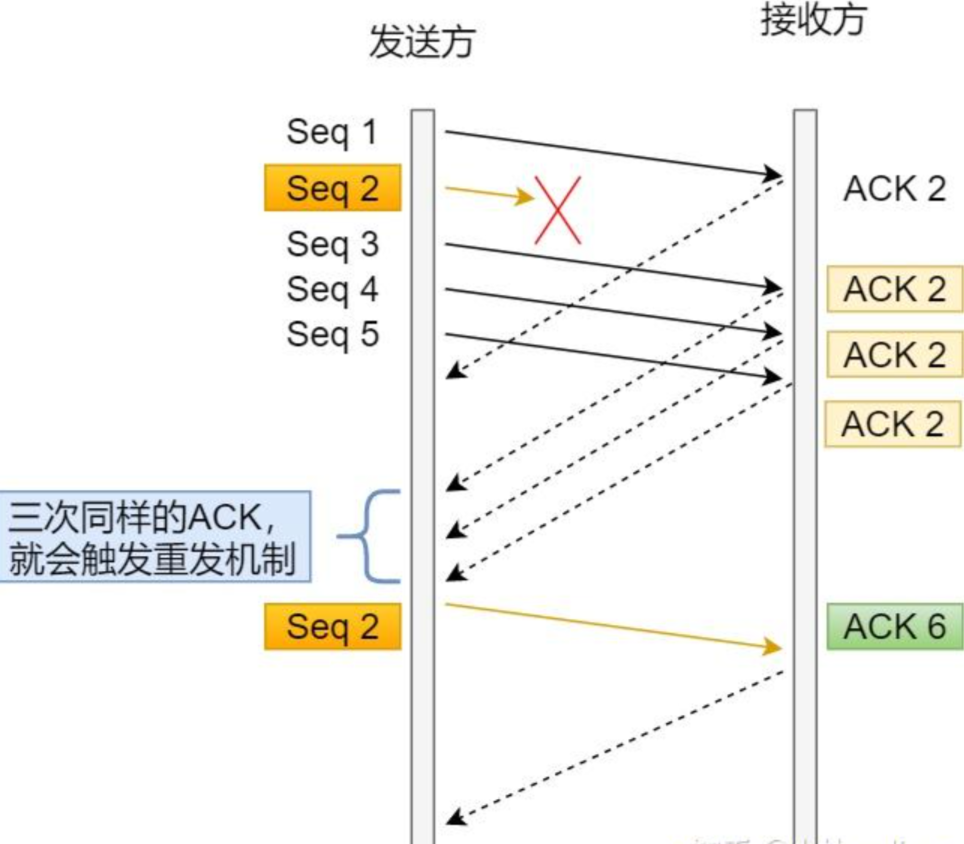
快速重传
最小的 ACK 没有收到,接收方三次收到比期望序号大的 ACK,这个时候即使没有到预定的超时重传时间,也要重传
流量控制 | Flow control ¶
遏制发送方的速率
接收方控制发送方,不让发送方发送的太多、太快以至于让接收方的缓冲区溢出
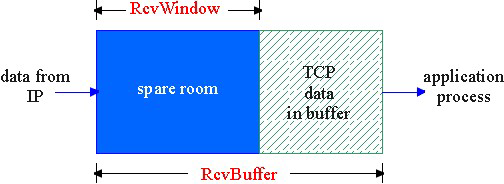
TCP 通过让发送方维护一个称为接收窗口 ( receive window ) 的变量来提供流量控制
UDP
UDP 没有流量控制,多发的包将丢失
接收方
接收方在其向发送方的 TCP 段头部的rwnd字段“通告”其空闲buffer大小
缓存中的可用的空间
$$
V = RcvWindow = RcvBuffer-[LastByteRcvd - LastByteRead]
$$
发送方
-
限制未确认 (
inflight) 字节的个数≤接收方发送过来的rwnd值 -
保证接收方不会被淹没
问题:TCP 只在有数据发或者确认的时候才发报文,所以当 B 的rcvd = 0时候,A 无法知道
为了解决这个问题, TCP 规范中要求 : 当主机 B 的接收窗口为 0 时,主机 A 继续发送只有一个字节数据的报文段。这些报文段将会被接收方确认。最终缓存将开始清空,并且确认报文里将包含一个非 0 的rvnd值。
拥塞控制 | Congestion control ¶
TCP/IP 复杂性放在网络边缘,靠端系统感知
TCP 拥塞控制常常被称为加性增、乘性减 (Additive-Increase Multiplicative-Decrease , AIMD )
如何检测拥塞¶
- 某个段超时了(丢失事件
) :拥塞 - 超时时间到,某个段的确认没有来
原因1:网络拥塞(某个路由器缓冲区没空间了,被丢弃)概率大
原因2:出错被丢弃了(各级错误,没有通过校验,被丢弃)概率小 - 有关某个段的 3 次重复 ACK:轻微拥塞
控制策略 ¶
维持一个拥塞窗口的值:CongWin动态的,是感知到的网络拥塞程度的函数
发送端限制已发送但是未确认的数据量(的上限): $$ LastByteSent-LastByteAcked le CongWin $$
MSS最大报文段SS
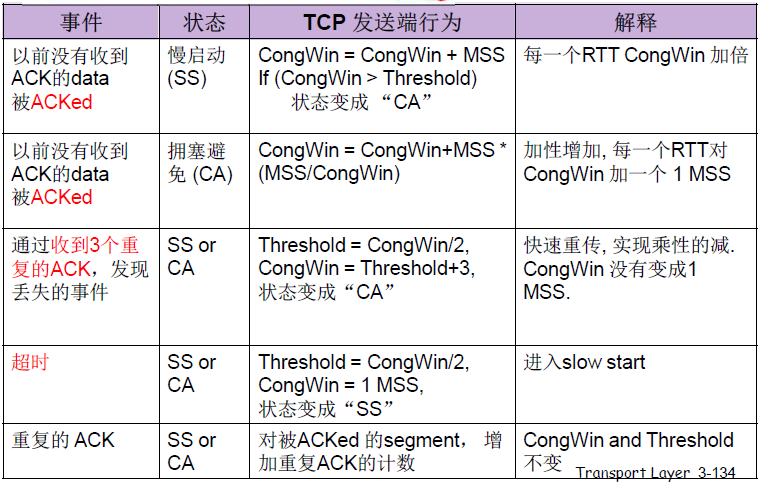
slow start阶段:加倍增加的阶段(每个 RTT)——慢启动阶段CA
congestion-avoidance阶段:线性增加的阶段(每个 RTT)——拥塞避免阶段
慢启动:当 \(CongWin<Threshold\), 发送端处于SS , 窗口指数性增长 .
拥塞避免:当 \(CongWin>Threshold\), 发送端处于CA , 窗口线性增长 .
快速恢复:
-
TCP Reno:当收到三个重复的 ACKs,
Threshold设置成CongWin/2(快速重传)\(CongWin=Threshold+3\) -
TCP Tahoe:当超时事件发生时
timeout, \(Threshold=CongWin/2\),\(CongWin=1 MSS\),进入 SS 阶段
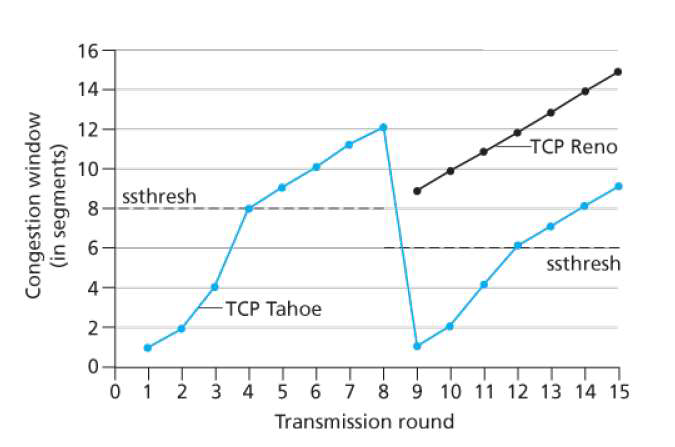
老师的神奇例子:
我家有很多酒,测老哥酒量;第一天喝 1 两,啥事没有;第二天 2 两,洒洒水啦;第三天 4,第四天 8 两,都莫有问题;
第五天,1 斤 6 两干趴了。下次就从警戒值 8 两(16 两的一半)开始一点点加
喝醉——超时
微醺——3 个冗余 ACK,进入拥塞避免
发送端控制发送但是未确认的量同时也不能够超过接收窗口,满足流量控制要求 $$ SendWin=min { CongWin, RecvWin } $$
同时满足拥塞控制和流量控制要求
吞吐量
TCP 连接的吞吐量公式
$$
平均吞吐量 = frac{1.22 times MSS}{RTT sqrt{L}}
$$
该公式作为丢包率(L) 往返时间(RTT)和最大报文段长度(MSS) 的函数
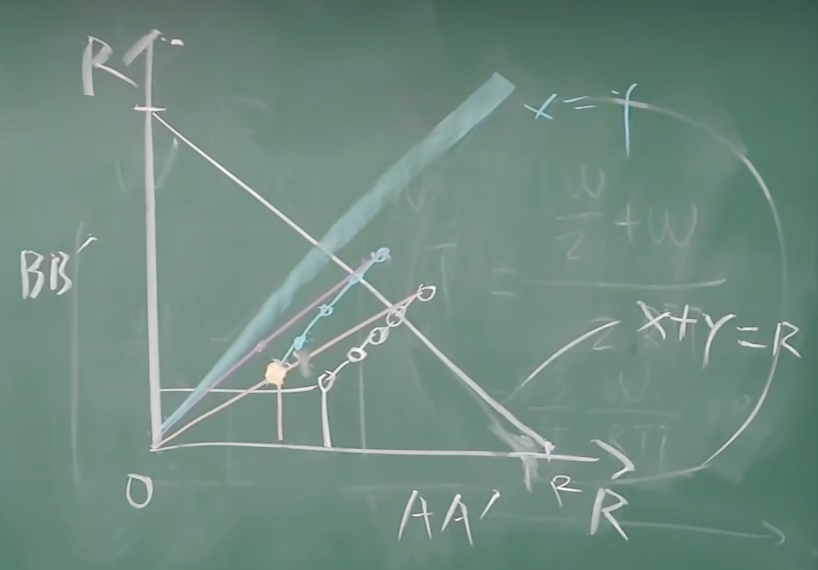
公平性 ¶
如果 K 个 TCP 会话分享一个链路带宽为 R 的瓶颈,每一个会话的有效带宽为 R/K
证明
随机选一个点,进入 CA 阶段,向白线靠近
超时之后,会减少到一半,重复这个过程
之后会逐渐趋近于 X=Y 这条线路
超长报文(不要求)¶
注意
字节流的服务,不提供报文的界限,需要靠应用进程自己维护
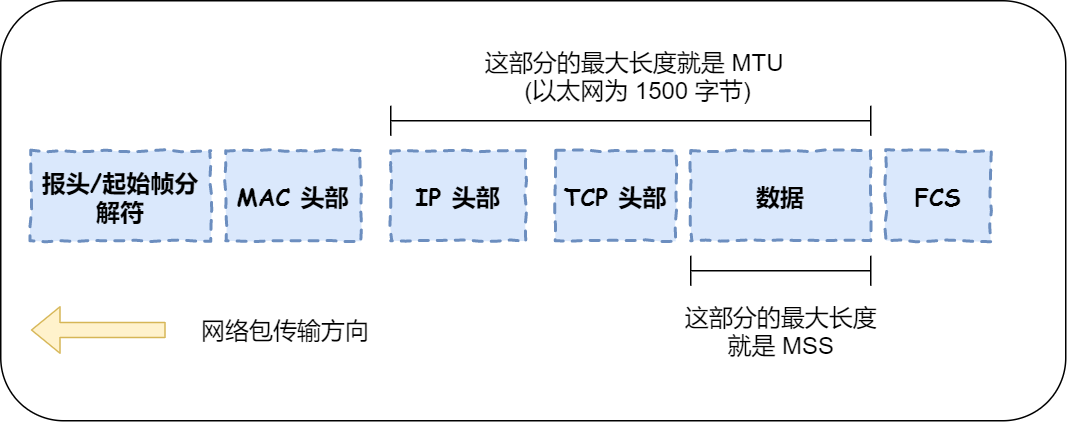
MTU 最大交换单元:一个网络包的最大长度,以太网中一般为 1500 字节;
MSS 最大报文段:除去 IP 和 TCP 头部之后,一个网络包所能容纳的 TCP 数据的最大长度;
在以太网中,最大传输单元(MTU)为 1500 个字节,在一个 IP 包中,去除 IP 包头的 20 个字节,可以传输的最大数据长度为 1480 个字节。在 TCP 包中,去除 20 个 TCP 包头,可以传输的最大数据段为 1460 个字节。因此,当数据超过最大数据长度时,将对该数据进行分片处理,在 IP 包头中会看到有多个片在传输,但标识号是相同的,表示是同一个数据包。
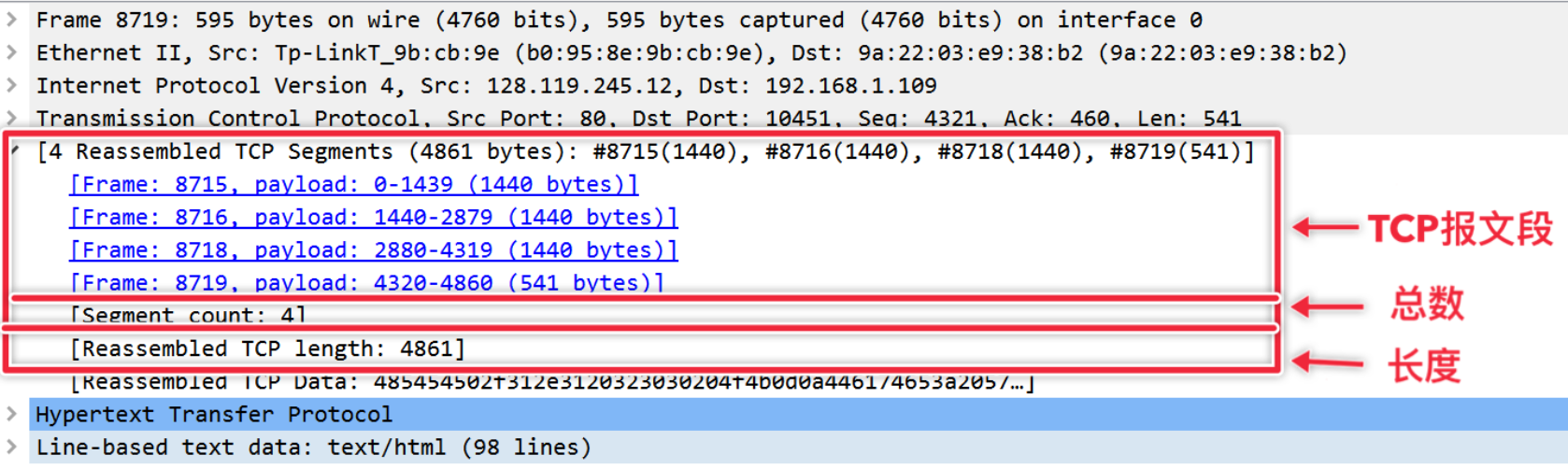
HTML 文件相当长时,例如: 4861 字节太大,一个 TCP 数据包不能容纳。因此,单个 HTTP 响应消息由 TCP 分成几个部分,每个部分包含在单独的 TCP 报文段中,如下图:长度为 4861 的报文被分为长度分别为 1440,1440,1440,541 的 4 个 TCP 段,编号分别为 8715,8716,8718,8719 。
-
序号:数据部分第一个字节在整个字节流的偏移量
offset进行编号 -
确认号:
ACK number累计确认;例如 ACK555 表示 554 及之前都已经收到,表示对 number 及以后字节的期待
TCP's error-recovery mechanism is probably best categorized as a hybrid of GBN and SR protocol
乱序报文段处理没有规定
为什么 IP 层有分片,TCP 还要分段
动图图解 | TCP/IP 到底是怎么分片的?-CSDN 博客
TCP的分片
因为 IP 层本身没有超时重传机制,它由传输层的 TCP 来负责超时和重传。
当接收方发现 TCP 报文(头部 + 数据)的某一片丢失后,则不会响应 ACK 给对方,那么发送方的 TCP 在超时后,就会重发「整个 TCP 报文(头部 + 数据)」。
因此,由 IP 层进行分片传输,是非常没有效率的。
所以,为了达到最佳的传输效能 TCP 协议在建立连接的时候通常要协商双方的 MSS 值,当 TCP 层发现数据超过 MSS 时,则就先会进行分片,当然由它形成的 IP 包的长度也就不会大于 MTU ,自然也就不用 IP 分片了。

经过 TCP 层分片后,如果一个 TCP 分片丢失后,进行重发时也是以 MSS 为单位,而不用重传所有的分片,大大增加了重传的效率。