HPE 领域综述 ¶
约 1901 个字 预计阅读时间 7 分钟
【万字长文!人体姿态估计 (HPE) 入门教程】 - 知乎 (zhihu.com)
人体姿态估计的过去,现在,未来 - 知乎 (zhihu.com)
基本信息
题目 :Vision-Based Human Pose Estimation via Deep Learning: A Survey
Author :Gongjin Lan, Yu Wu, Fei Hu, Qi Hao
arXiv地址:Vision-Based Human Pose Estimation via Deep Learning: A Survey (arxiv.org)

名词解释 ¶
regression paradigm
Deep learning¶
CNN(Convolutional Neural Networks)¶
AlexNet
ResNet
CNN 在 HPE 任务中通常分为两个主要部分:
-
骨干网络(Backbone Network):这是 CNN 的第一部分,通常采用现成的、经过预训练的通用网络模型来提取图像的特征。例如,ResNet 是一个非常常用的骨干网络,它通过深层的卷积层学习图像中的高级特征。这些特征包含了图像中重要的视觉信息,为后续的姿态预测提供基础。
-
预测头(Prediction Head):这是 CNN 的第二部分,负责使用骨干网络提取出的特征来预测人体的姿态。预测头的设计和实现方式可以有很多种,但它的主要任务是根据输入图像的特征,确定图像中人体各个关节的位置。
-
回归范式(直接预测关节坐标)在回归范式中,模型直接从输入图像预测出每个关节的坐标。这种方法通常采用全连接层(fully connected layers)来对具体的关键点坐标进行回归。这意味着模型输出的是一个坐标列表,每个坐标代表一个关节在图像中的位置。
举例:假设我们想要从一张人体图像中预测头部、肩膀、肘部和手腕的位置,使用回归范式的模型将直接输出这些部位的 x 和 y 坐标值,例如,头部可能被预测为 (100, 50),肩膀为 (120, 80),等等。
-
热图预测范式(生成热图后计算关节坐标)热图预测范式先生成每个关节的热图表示,然后从这些热图中计算出关节坐标。热图是一种概率分布图,表示了关节出现在图像不同位置的可能性。在生成热图之后,通过某种方式(通常是找到热图中的最大值点)来确定关节的最终坐标。为了提高热图的分辨率,常用的操作是上采样(
upsampling) 。举例:使用热图预测范式来估计同样的头部、肩膀、肘部和手腕的位置时,模型首先为每个关节生成一张热图。例如,头部的热图中最亮的点(最大概率值所在点)位于 (102, 48),这个点就被认为是头部的预测位置。肩膀、肘部和手腕也以同样的方式从它们各自的热图中确定位置。
-
RNN(Recurrent Neural Networks)¶
They are widely used in video-based HPE by considering videos as sequential RGB images.
GCN(Graph Convolutional Networks)¶
GCNs are generally expected to better exploit the relationship among key points and used for the pose refinement, joint association, 2D-to-3D pose lifting
方法解释 ¶
自上而下(Top-down)方法:
- 流程:首先通过人体检测器在图像中识别出每个人的位置,即为每个人生成一个边界框(bounding box
) ,然后对每个检测到的人体边界框内的图像进行单人姿态估计。 - 优点:通常能提供较高的姿态估计精度,因为每个人体被单独处理,避免了不同人之间的姿态混淆。
- 缺点:计算量随着人数的增加而线性增加,因此在人数较多的场景中效率较低。人体检测的准确性直接影响姿态估计的结果。
- 适用场景:对精度要求较高的应用,如需要精细分析每个人姿态的场合。
自下而上(Bottom-up)方法:
- 流程:首先在整个图像范围内直接检测所有的人体关节点,然后使用某种算法(如图匹配、聚类等)将这些检测到的关节点根据归属分配到不同的人体上。
- 优点:不需要先进行人体检测,直接在图像上识别关节点,因此计算量不直接随人数增加而增加,适合于处理大规模人群的场景,具有更高的效率。
- 缺点:在关节点分配和人体实例的区分上可能面临更大的挑战,尤其是在人体密集或严重遮挡的场景中,可能导致精度略低于自上而下方法。
- 适用场景:适用于人群密集的场景,或需要实时处理的应用中。
主流数据集和技巧 ¶
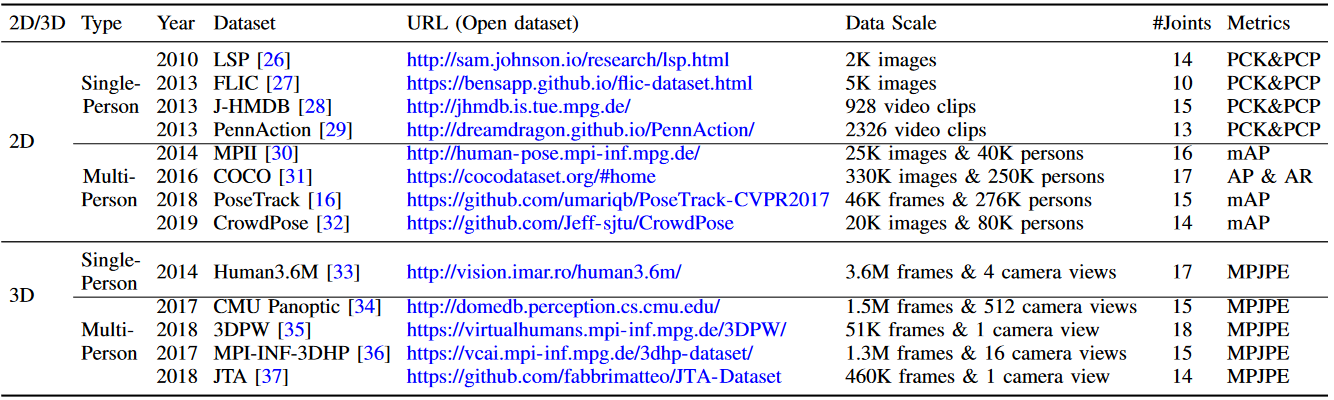
1. AIC (AI Challenger) Dataset¶
AI Challenger 是一个综合性的数据集,包含多个挑战,其中包括人体关键点检测任务。这个数据集旨在通过提供大量标注数据,推动人工智能在图像识别、语言理解等方面的研究和发展。
2. COCO (Common Objects in Context) Dataset¶
COCO 数据集是计算机视觉研究领域中最著名的数据集之一,它支持多种任务,包括目标检测、分割和人体关键点检测。COCO 数据集以其大规模和多样性而闻名,提供了大量详细标注的图像,这些图像包含了日常场景中的对象和人体。
3. CrowdPose Dataset¶
CrowdPose 数据集专注于复杂场景下的人体姿态估计,特别是在人群中。它旨在解决传统数据集忽略的问题:高度拥挤的场景中人体姿态的检测和分析。
4. H36M (Human 3.6 Million) Dataset¶
H36M 数据集是一个大规模的 3D 人体姿态数据库,提供了 360 万个 3D 人体姿态。这些数据来自于配备了标记的 9 个参与者执行各种日常活动的视频。H36M 主要用于深度学习和人体姿态估计的研究。
5. JHMDB (Joint-annotated Human Motion Data Base) Dataset¶
JHMDB 数据集是一个用于人体动作识别和姿态估计的数据集,包含从现实世界视频中提取的 21 种不同动作类别。每个视频都有相应的人体关键点标注。
6. MHP (Multi-Human Parsing) Dataset¶
MHP 数据集旨在促进多人体解析的研究,特别是在复杂场景中。它提供了大量的图像,这些图像中的每个人都有详细的像素级标注,用于身体部位的分割。
7. MPII Dataset¶
MPII Human Pose 数据集是一个大规模数据集,用于 2D 人体姿态估计。它包含了多种日常活动场景下的图像,每个图像都配有人体关键点的精确位置标注。
8. MPII_TRB Dataset¶
MPII_TRB 数据集可能是指 MPII 数据集的一个特定子集或变种,用于特定的研究或比赛任务。这个名称不是非常常见,可能需要在特定文档或资料中查找具体细节。
9. OCHuman Dataset¶
OCHuman 数据集专注于挑战性的人体姿态估计场景,尤其是高遮挡和人体交互场景。它旨在提供一个难度更高的测试基准,以推动相关技术的进步。
10. PoseTrack18 Dataset¶
PoseTrack 是一个大规模的人体姿态估计和跟踪数据集,PoseTrack18 指的是 2018 年发布的版本。它专注于视频中的人体姿态估计和跟踪,提供了大量连续帧中人体姿态的标注。