MISC¶
约 9180 个字 18 行代码 预计阅读时间 36 分钟
什么是 MISC ¶
miscellaneous 杂项
MISC = ALL - PWN - WEB - CRYPTO - REVERSE
一般来讲 misc 包括的题型:
- 隐写、取证、OSINT(信息搜集
) 、PPC(编程类) —— 传统 misc 题 - 游戏类题目(大概也算 PPC
) 、工具运用类题目 - 编解码、古典密码 —— 不那么 crypto 的 crypto
- 网络解谜、网站代码审计 —— 不那么 web 的 web
- 代码审计、沙箱逃逸 —— 不那么 binary 的 binary
- Blockchain、IoT、AI —— 新兴类别题目
编码分析 ¶
工具
所有信息都是 01 串,而 01 串之间可以发生互相的转换
常见的 01 串转换方式有 编解码、加解密、哈希
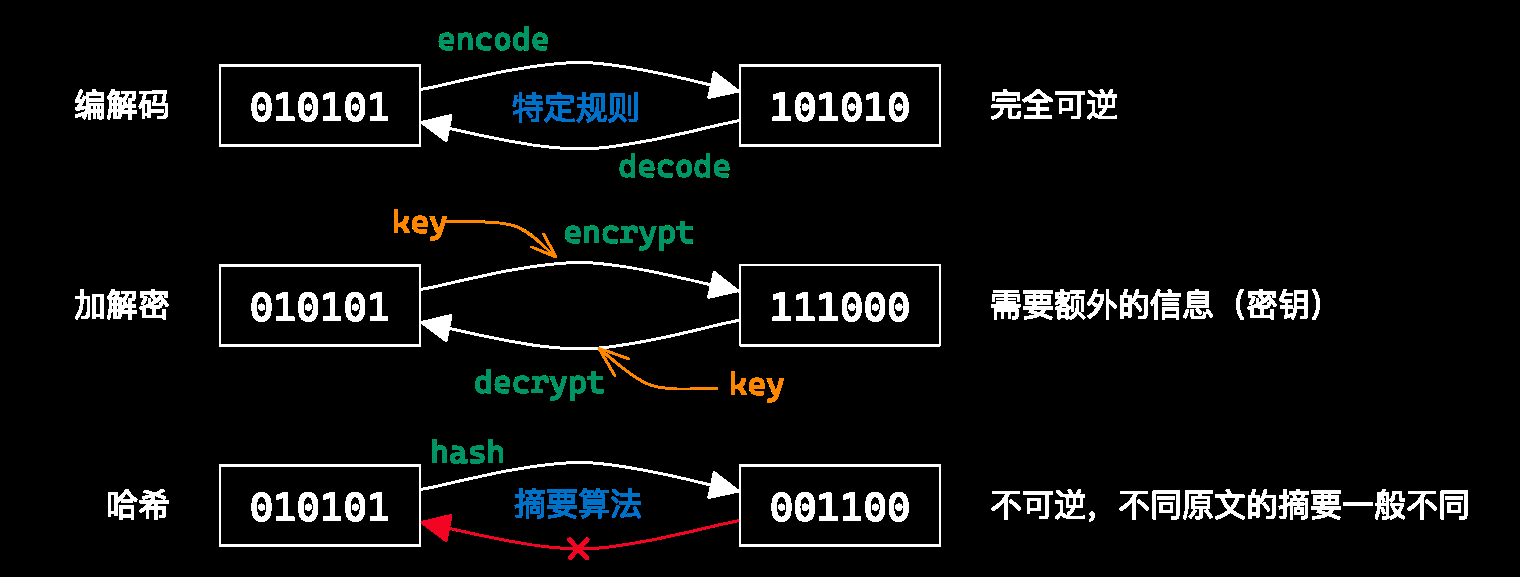
字符编码 ¶
为什么会乱码?什么是编解码?ASCII、Unicode、UTF-8 的实现原理是什么?本文帮你讲透!
人类理解的字符 to 计算机理解的 01 串之间的映射
乱码 ¶
用一种字符编码规则解读另一种字符编码的 01 串
CyberChef,通过 Input 和 Output 窗口的字符集设置 需要注意,CyberChef 的 UTF-8 不会将错误解码替换为 (非预期)vscode右下角的编码方案(重新打开 / 用编码保存)- 必要的时候可以使用
python来进行编解码 / 进制转换等
常见乱码
“国”字的 Unicode 是 U+56FD,在 UTF-8 中,它被编码为三个字节:11100101 10011011 10011101 (0xE5 0x9B 0xBD)
使用 GBK 编码读取,它是一种双字节编码方案,因此,它可能会将这三个字节解释为两种:
- 解释成 2 个字节 + 1 个字节,导致乱码。
- 解释成 2 个字节 + 2 个字节 ( 包含下一个字符的第一个字节 ),导致乱码。
ASCII 字符是不会乱码的
因为所有的编码方案都是以 ASCII 为基础的,ASCII 字符在所有的编码方案中都是一样的,不会发生乱码。 经常乱码的是有CJK字符的文本(Chinese,Japanese,Korean)
我们以 " 于是转身向大海走去 " 这句话为例,用不同的编码方式进行编码和解码,会产生不同的乱码形式。
案例
//utf-8下编码
e4 ba 8e e6 98 af //于是
e8 bd ac e8 ba ab //转身
e5 90 91 //向
e5 a4 a7 e6 b5 b7 //大海
e8 b5 b0 e5 8e bb //走去
//GBK下编码 HEX
d3 da ca c7 d7 aa c9 ed
cf f2 b4 f3 ba a3 d7 df
c8 a5
//GBK下编码 BINARY
11010011 11011010 11001010 11000111
11010111 10101010 11001001 11101101
11001111 11110010 10110100 11110011
10111010 10100011 11010111 11011111
11001000 10100101
因为匹配规则是 1 字节: 0xxxxxxx 2 字节: 110xxxxx 10xxxxxx 3 字节: 1110xxxx 10xxxxxx 10xxxxxx 4 字节: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
比如11010011不符合规则,直接变成ef bf bd
11110010 本来应该匹配四个字节,但是后面只有一个10xxxxxx,那么11110010 10110100整体变成一个ef bf bd
以此类推,11110011 10111010 10100011变成一个ef bf bd
所以最后用 GBK 解码 UTF-8 编码的文本得到“锟斤拷锟斤拷转锟斤拷锟斤拷山锟斤拷锟斤拷去”
ef bf bd ef bf bd ef bf bd ef bf bd
d7 aa ef bf bd ef bf bd
ef bf bd ef bf bd ef bf bd
ef bf bd ef bf bd
c8 a5
| 名称 | 示例 | 特点 | 产生原因 | |
|---|---|---|---|---|
| 古文码 | 浜庢槸杞韩鍚戝ぇ娴疯蛋鍘� | 大部分为不认识的古文,并加杂日韩文 | 以 GBK 方式读取 UTF-8 编码的中文 ,GBK 是双字节编码方案,会有识别不到的字符(缺字节) | 可以复原,HEX 字符不变 |
| 口字码 | ӚʇתɭϲԳڣןȥ | 大部分字符为小方块 | 以 UTF-8 的方式读取 GBK 编码的中文 | 可以复原,HEX 字符不变 |
| 符号码 | äºæ¯è½¬èº«åå±±æµ·èµ°å» | 大部分字符为各种符号 | 以 ISO8859-1 方式读取 UTF-8 编码的中文 | 可以复原,HEX 字符不变 |
| 拼音码 | ÓÚÊÇתÉíÏòɽº£×ßÈ¥ | 大部分字符为头尾带有类似声调符号的字母 | 以 ISO8859-1 方式读取 GBK 编码的中文 | |
| 问号码 | 于是转身向山海走�? | 字符长度为偶数时正确,长度为奇数时最后的字符变为问号 | 以 GBK 方式读取 UTF-8 编码的中文,然后用 UTF-8 的格式再次读取 | 无法复原,HEX 变化了 |
| 锟斤拷码 | 锟斤拷锟斤拷转锟斤拷锟斤拷山锟斤拷锟斤拷去 | 全中文字符,且大部分字符为“锟斤拷”这几个字 | 先用 UTF-8 解码 GBK 编码的文本,再用 GBK 解码前面的结果 | 大部分信息丢失 |
| 烫烫烫 | VC Debug 栈内存没有初始化 | |||
| 屯屯屯 | VC Debug 堆内存没有初始化 |
GBK 解码:在 gbk 中,半角 Ascii 字符?的编码是0x3f , 若不足双字节,最后会把多余的字符变成0x3f,所以奇数个字符的最后一个字符会变成?,这个时候数据就被破坏了,就无法复原了
UTF-8 解码:如果超出 UTF-8 的范围,会用0xef 0xbf 0xbd来表示,这个时候数据就被破坏了,就无法复原了
但实际中,有一种情况,是 100% 可以将乱码还原成最初的字符串。就是任意编码格式编码,ISO-8859-1 解码,这个主要因为 ISO-8859-1 是单字节编码,而且匹配所有单字节情况,乱码字符串总是可以还原到最初的二进制。
手持两把锟斤拷,口中疾呼烫烫烫。脚踏千朵屯屯屯,笑看万物锘锘锘
源于 GBK 字符集和 Unicode 字符集之间的转换问题。Unicode 和老编码体系的转化过程中,肯定有一些字,用 Unicode 是没法表示的,Unicode 官方用了一个占位符来表示这些文字,这就是:U+FFFD REPLACEMENT CHARACTER。那么 U+FFFD 的 UTF-8 编码出来,恰好是 \xef\xbf\xbd。如果这个\xef\xbf\xbd,重复多次,例如 'xefxbfxbdxefxbfxbd',然后放到 GBK/CP936/GB2312/GB18030 的环境中显示的话,一个汉字 2 个字节,最终的结果就是:锟斤拷——锟 (0xEFBF ),斤(0xBDEF0xBFBD\xef\xbf\xbd,连在一起就会出现锟斤拷
在 windows 平台下,ms 的编译器(也就是 vc 带的那个)在 Debug 模式下,会把未初始化的栈内存全部填成 0xcc,而放到 GBK/CP936/GB2312/GB18030 的环境中显示的话,就是烫 (0xcccc )
未初始化的堆内存全部填成0xcd,而屯字恰好是0xcdcd
所以如果出现这两种乱码需要检查初始化。
BOM 是 Byte Order Mark的缩写。是 UTF 编码方案里用于标识编码的标准标记,在 UTF-16 里本来是 FF FE,变成 UTF-8 就成了EF BB BF。这个标记是可选的,因为 UTF8 字节没有顺序,所以它可以被用来检测一个字节流是否是 UTF-8 编码的。
GBK 下:锘EFBB、匡BFEF、豢BBBF
ASCII¶
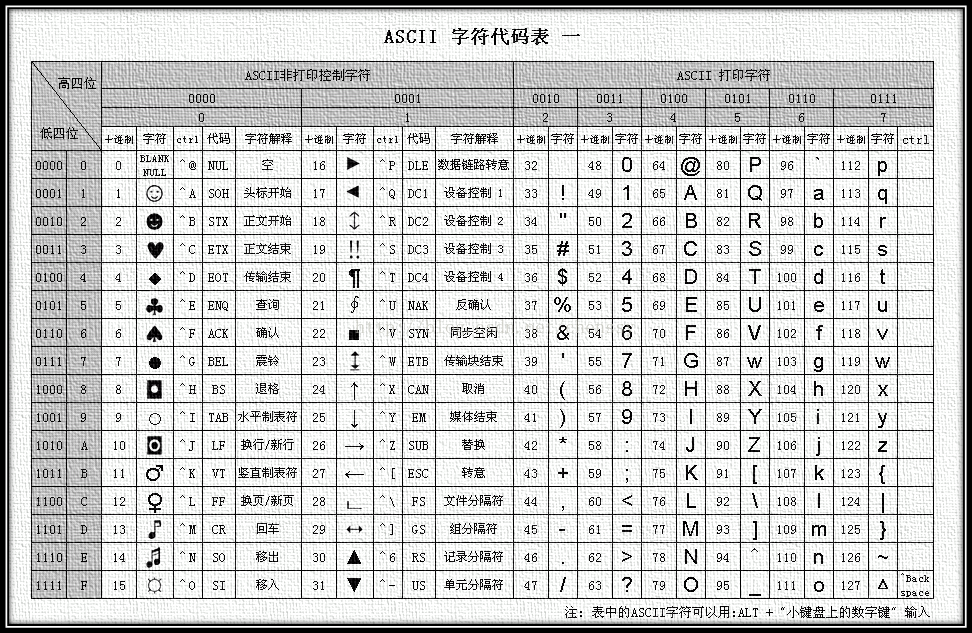
ASCII 码是为了英语使用者能够把常用的 128 个字符存储在计算机中而设置的一套规则。
(American Standard Code for Information Interchange,美国标准信息交换码
一共 128 个项,即每个字符可以用一个 7 位的 01 串表示(或一字节) 00-1F:控制字符;20-7E:可见字符;7F:控制字符(DEL)
Latin-1(ISO-8859-1)¶
扩展了 ASCII,一共 256 个项 80-9F:控制字符;A0-FF:可见字符 特点:任何字节流都可以用其解码
利用 Unicode 字符集的一系列编码 ¶
Unicode,正如它的中文意思“统一码”一样,它包含了世界上所有的通用符号(超过 110 多万个符号U+后跟一个十六进制数,例如,U+56fd表示汉字的“国”,U+0639 表示阿拉伯字母 Ain,U+0041 表示英语的字母 A 等。
UTF-8 / UTF-16 / UTF-32 / UCS
以平面划分,17 个平面,每个平面 65536 个码位(2 字节) 通过码位可以表示为 U+0000 ~ U+10FFFF
可容纳 111w+ 个字符,现有 14w+ 个字符(超过一半为 CJK 字符)
UCS(Universal Character Set)
UCS-2:直接用 2 字节表示码位;
UCS-4:直接用 4 字节表示码位
UTF(Unicode Transformation Format):
- UTF-8:变长编码(1~4),兼容 ASCII
1 字节 : 用于编码 7 位 ASCII 字符,表示范围:U+0000 到 U+007F,与 ASCII 码完全兼容 2 字节: 用于编码 11 位字符,表示范围:U+0080 到 U+07FF 3 字节: 用于编码 16 位字符,表示范围:U+0800 到 U+FFFF 4 字节: 用于编码 21 位字符,表示范围:U+10000 到 U+10FFFF
- 对于单字节的符号,UTF-8 编码和 ASCII 码是相同的:第一位为 0,后面 7 位为 Unicode 码
- 对于 \(n(n >= 2)\) 字节的符号,二进制的第一个字节,最高位有 n 个 1(1 后面紧跟一位 0
) ,二进制后面的每个字节,前两位都固定为“10”,xxx 部分全部是 Unicode 码
1 字节 : 0xxxxxxx 2 字节: 110xxxxx 10xxxxxx 3 字节: 1110xxxx 10xxxxxx 10xxxxxx 4 字节: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
-
字符 A(U+0041) 分析:字符’A’的 Unicode是 U+0041,位于 U+0000 到 U+007F之间,因此,一个字节就可以表示,因此,二进制为:01000001,转成十六进制为:0x41
-
字符€ (U+20AC) 分析:字符 ‘€’的 Unicode是 U+20AC,位于 U+0800 到 U+FFFF之间,因此,需要用 3个字节表示,即1110xxxx 10xxxxxx 10xxxxxx,将“20AC”中的每个字符直接转换成二进制为:0010 0000 1010 1100,然后将它从低位往高位(从右到左)依次替换x,如下图:
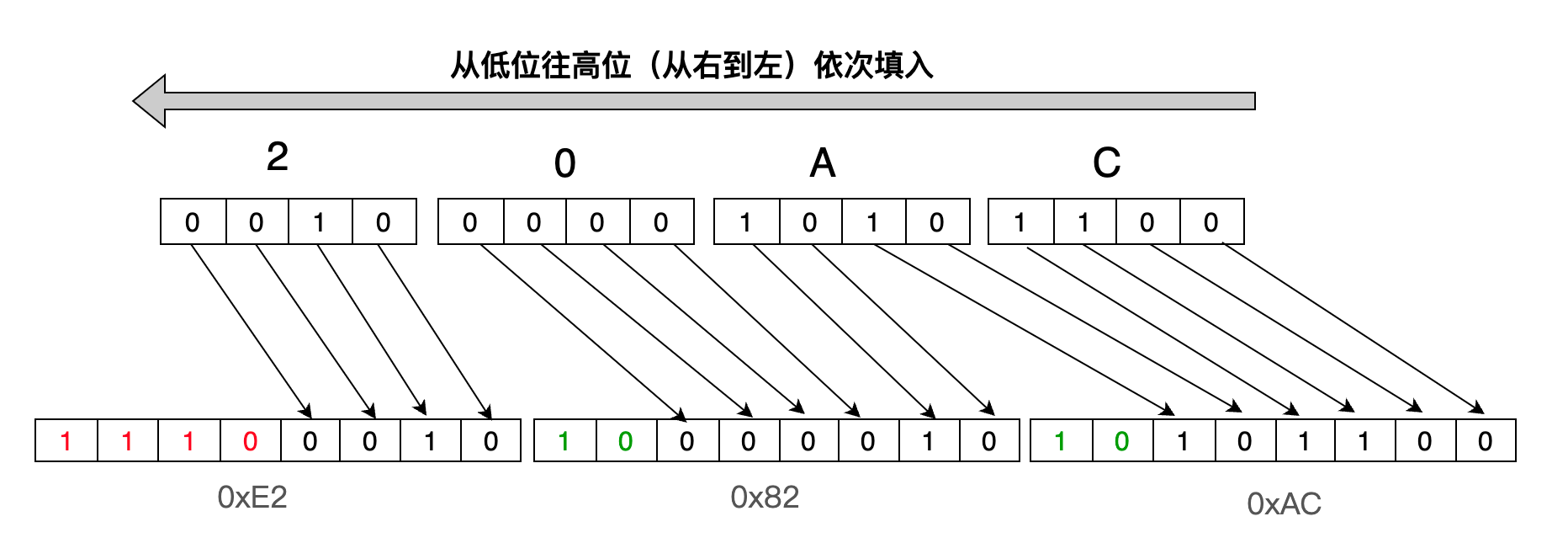 这样得出字符 € (U+20AC)用 UTF-8编码的二进制为:11100010 10000010 10101100,转换成十六进制为:0xE2 0x82 0xAC
这样得出字符 € (U+20AC)用 UTF-8编码的二进制为:11100010 10000010 10101100,转换成十六进制为:0xE2 0x82 0xAC
UTF-16:变长编码(2/4) ,不兼容 ASCII
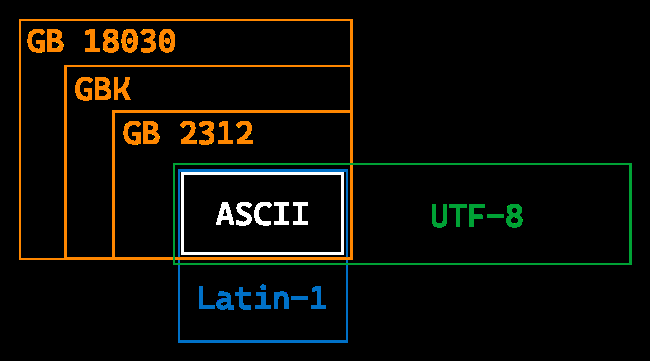
中国国标字符集系列编码 ¶
GB 2312 / GBK / GB 18030-2022
三种 GB 的递进关系
每个字符占据 1bytes,用二进制表示的话最高位必须为 0(扩展的 ASCII 不在考虑范围内
最早一版的中文编码,每个字占据 2bytes。由于要和 ASCII 兼容,那这 2bytes 最高位不可以为 0 了(否则和 ASCII 会有冲突
由于 GB2312 只有 6763 个汉字,我汉语博大精深,只有 6763 个字怎么够?于是 GBK 中在保证不和 GB2312、ASCII 冲突(即兼容 GB2312 和 ASCII)的前提下,也用每个字占据 2bytes 的方式又编码了许多汉字。经过 GBK 编码后,可以表示的汉字达到了 20902 个,另有 984 个汉语标点符号、部首等。值得注意的是这 20902 个汉字还包含了繁体字。
然而为了和 ASCII 兼容,最高位不能为 0 就已经直接淘汰了一半的组合,只剩下 3 万多种组合无法满足全部汉字要求
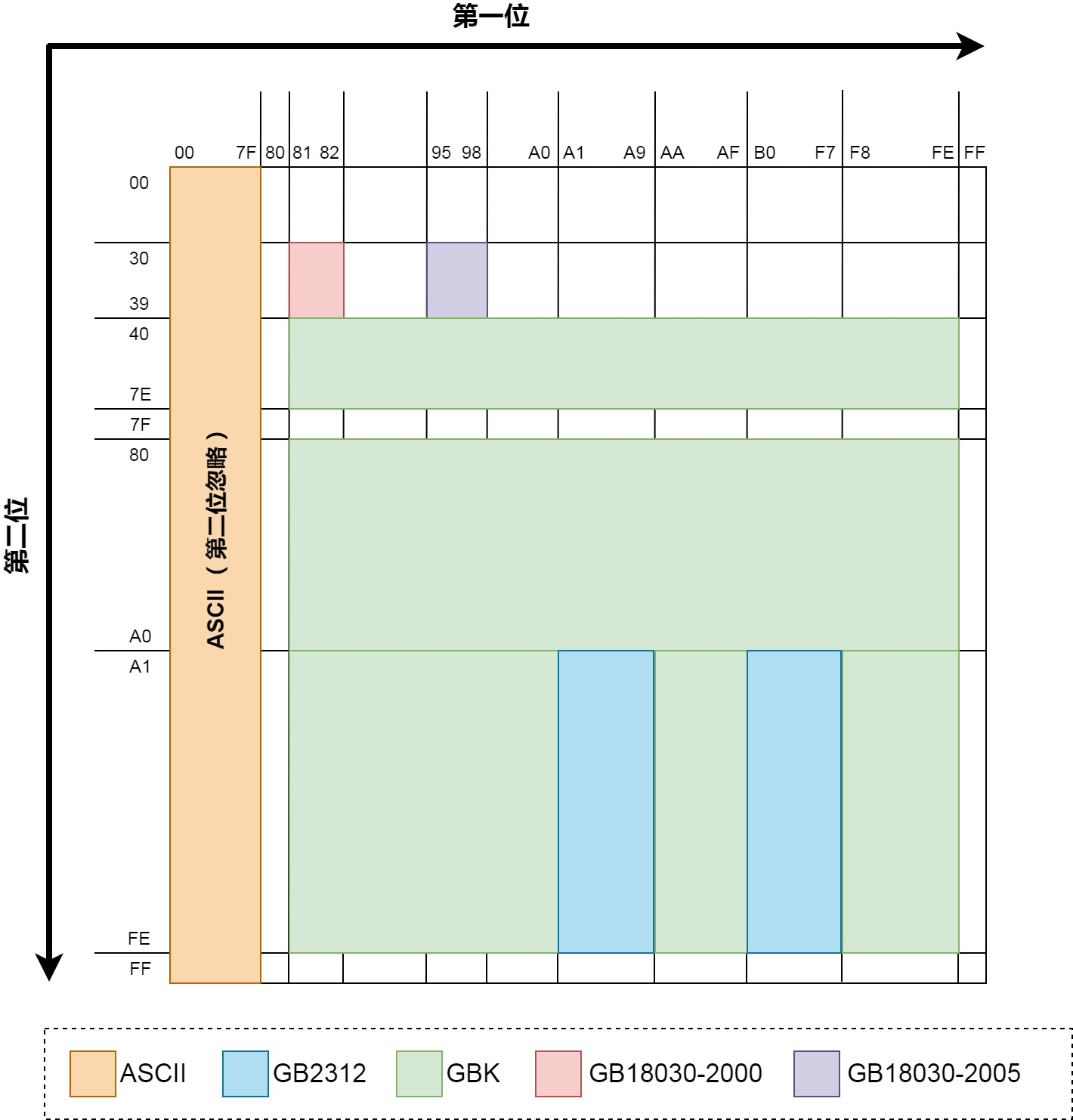
这图中展示了前文所述的几种编码在编码完成后,前 2 个 byte 的值的范围(用 16 进制表示
实际生活中,我们用到的 99% 以上的汉字,其实都在 GB2312 那一块区域内。
GB2312
GB2312 简体中文编码表 - 常用参考表对照表 - 脚本之家在线工具
ASCII 码的设计很优秀,但对于中文使用者,怎么能接受计算机存储不了中文的现实?于是,聪明的中国人在 1980 年发布了一套适用自己的新编准:GB2312。
GB2312 是中华人民共和国国家标准《信息交换用汉字编码字符集 基本集》的简称,全称为 GB 2312-1980。该标准定义了用于简体中文字符和一些其他字符的编码方法,而且兼容 ASCII,广泛应用于中文信息处理系统中。
GB2312 是一个双字节编码字符集, 总共有 7445 个字符,主要包括 6763 个汉字和 682 个非汉字字符(如 ASCII、拉丁字母、希腊字母、日文假名、符号等
- 一级汉字:3755 个常用汉字,按拼音顺序排列
- 二级汉字:3008 个次常用汉字,按部首 / 笔画顺序排列
- 非汉字字符:682 个,包括图形符号、拉丁字母、日文假名、希腊字母、俄文字母、制表符、标点符号等。
GB2312 将字符集划分为 94 个区(1-94
高字节:0xA1 + 区号 - 1 低字节:0xA1 + 位置号 - 1
“你”在 GB2312 编码表中位于第 36 区第 67 位:
高字节:0xA1 + 36 - 1 = 0xC4
低字节:0xA1 + 67 - 1 = 0xE3
GBK
最全面的 GBK 编码表 /GBK 字符集 - 常用参考表对照表 - 脚本之家在线工具
随着互联网的快速发展,GB2312 编码表中定义的字符已经不够用了,因此,GB2312 的扩展版 GBK 编码表诞生了。
GBK 是“国标扩展字符集”前 3 个汉字拼音首字母的缩写,全称是《汉字内码扩展规范
GBK 是一个双字节编码字符集,每个字符由一个或两个字节表示。其编码结构如下:
GBK 支持 21003 个汉字和图形字符,涵盖了汉字、日文假名、韩文、特殊符号等 包括 GB2312的全部字符,以及其他新增的汉字和符号
GBK 扩展了 GB2312 的编码范围,使其支持更多字符 单字节部分(与 ASCII兼容):0x00 - 0x7F
双字节部分: 第一个字节范围:0x81 - 0xFE 第二个字节范围:0x40 - 0xFE(去掉 0x7F)
单字节:00000000 - 01111111
双字节:10000001 01000000 - 11111110 11111110 ( 剔除******** 01111111 )
单字节、双字节的区分通过高字节高位区分,单字节高位为 0,双字节的高字节高位为 1。
单字节 字符“A”,使用单个字节可以存储,“A”的 ASCII码十进制是65,转换成十六进制为:0x41,二进制为:1000001
双字节 字符“汉”在 GBK编码中使用双字节表示,GBK编码: BABA,分成两个字节表示成:0xBA 0xBA
GB18030 国标文档
GB18030 是国家标准化委员会(SAC)发布的字符编码标准,是一种用于汉字、汉语拼音、注音符号和汉字部首等文字的字符集和编码方案,它是继 GB2312 和 GBK 后更强劲的版本。
GB18030 的特点包括:
- 兼容性:GB18030 兼容 ASCII、GB2312、GBK 以及 Unicode 等多种编码方案。
- 完备性:GB18030 收录了 70000 多个字符,包括汉字、汉语拼音、注音符号、汉字部首、拉丁字母、数字、标点符号等。
- 可扩展性:GB18030 采用了四字节编码方案,可以容纳未来出现的所有字符。其中汉字使用双字节或四字节编码,而非汉字字符则使用单字节或双字节编码。
Base 编码 ¶
本质
字节流 -> 整数 -> n 进制 -> 系数查表
Base 16¶
base16 编码也称为十六进制编码或 Hex 编码,是一种将二进制数据表示为十六进制数字和字符的方法。它使用 16 个字符(0-9 和 A-F)来表示 4 位二进制数的每个组合。
这里就涉及一个字节序的问题:是用大端模式还是小端模式?Base16 编码明确表明是用小端模式存储。
编码过程:
1. 将二进制数据分割为 4 个一组
2. 映射,将每四位二进制数据映射到对应的 base16 字符。如下:
0000 -> 0
0001 -> 1
0010 -> 2
0011 -> 3
0100 -> 4
0101 -> 5
0110 -> 6
0111 -> 7
1000 -> 8
1001 -> 9
1010 -> A
1011 -> B
1100 -> C
1101 -> D
1110 -> E
1111 -> F
base32¶
由于 5bit 就可以表示 2^5 = 32 个字符。
结果长度必须是 5 的倍数,不足的用 = 不齐(明显特征)
编码
00000 -> A
00001 -> B
00010 -> C
00011 -> D
00100 -> E
00101 -> F
00110 -> G
00111 -> H
01000 -> I
01001 -> J
01010 -> K
01011 -> L
01100 -> M
01101 -> N
01110 -> O
01111 -> P
10000 -> Q
10001 -> R
10010 -> S
10011 -> T
10100 -> U
10101 -> V
10110 -> W
10111 -> X
11000 -> Y
11001 -> Z
11010 -> 2
11011 -> 3
11100 -> 4
11101 -> 5
11110 -> 6
11111 -> 7
base58¶
原理:
-
准备要编码的二进制数据: 将要编码的二进制数据准备好,通常是字节的形式。
-
添加版本前缀(可选
) : 在某些应用中,可以在二进制数据前添加一个版本前缀,以标识数据的类型或用途。这是可选的步骤,具体取决于编码的需求。 -
计算校验和(可选
) : 在某些情况下,可以计算二进制数据的校验和并附加到数据的末尾,以增加数据的完整性和安全性。这也是可选的步骤。 -
Base58 编码: 将经过前两步(添加版本前缀和计算校验和,如果适用)的二进制数据转换为 Base58 编码的文本。编码过程如下:
Base58 字符集通常包括 58 个字符,通常是由除去易混淆的字符(如 0、O、I 和 l)以及可能引起歧义的字符(如 + 和 /)的字符集构成。 将二进制数据视为一个大整数,使用Base58字符集中的字符作为数字的基数。
将大整数除以 58,记录余数,并继续除以 58,直到商为零。这将生成 Base58 编码的每个字符。
最后,反转生成的字符顺序以获得最终的 Base58 编码字符串。
base64¶
明显特征
结果长度必须是 4 的倍数,不足的用 = 不齐(1~2 个,明显特征)
字符表
标准字符表:A-Za-z0-9+/
另有多种常用字符表,如 URL 安全字符表:A-Za-z0-9-_
| Index | Character | Index | Character | Index | Character | Index | Character |
|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w |
| 1 | B | 17 | R | 33 | h | 49 | x |
| 2 | C | 18 | S | 34 | i | 50 | y |
| 3 | D | 19 | T | 35 | j | 51 | z |
| 4 | E | 20 | U | 36 | k | 52 | 0 |
| 5 | F | 21 | V | 37 | l | 53 | 1 |
| 6 | G | 22 | W | 38 | m | 54 | 2 |
| 7 | H | 23 | X | 39 | n | 55 | 3 |
| 8 | I | 24 | Y | 40 | o | 56 | 4 |
| 9 | J | 25 | Z | 41 | p | 57 | 5 |
| 10 | K | 26 | a | 42 | q | 58 | 6 |
| 11 | L | 27 | b | 43 | r | 59 | 7 |
| 12 | M | 28 | c | 44 | s | 60 | 8 |
| 13 | N | 29 | d | 45 | t | 61 | 9 |
| 14 | O | 30 | e | 46 | u | 62 | + |
| 15 | P | 31 | f | 47 | v | 63 | / |
步骤 1. 准备要编码的二进制数据: 将要编码的二进制数据准备好,通常是字节的形式。
-
分组: 将二进制数据分成固定大小的组,每组通常为 3 字节(24 位
) 。如果最后一组不足 3 字节,通常需要进行填充,以便每组都有 3 字节。 -
将每个组的二进制数据转换为十进制: 将每个 3 字节的二进制数据视为一个 8bit*3=24bit 位的二进制整数,再转化为一个十进制整数。
-
Base64 编码: 将每个十进制整数编码为 Base64 字符。
-
Base64 字符集通常包括 64 个字符,通常是大写字母 A 到 Z、小写字母 a 到 z、数字 0 到 9 以及两个额外的字符(通常是 "+" 和 "/"
) 。 - 以 24 位整数为例,将它分成 4 组,每组 6 位。这 4 组 6 位整数将被编码为 4 个 Base64 字符。
- 每个 6 位整数对应一个 Base64 字符,根据其在 Base64 字符集中的位置来选择。
- 如果原始数据不足 3 字节,会添加一个或两个额外的 0 位,以确保每个 6 位整数都有 6 位。
- Base64 编码的结果是一个文本字符串,其中包含一系列 Base64 字符,每 4 个字符分为一组,每组表示一个 24 位整数。
- 填充(可选
) : 如果原始数据的长度不是 3 的倍数,可以使用一个或两个填充字符“=”来补全 Base64 编码,以确保编码长度是 4 的倍数。
import base64
str1 = "cPQebAcRp+n+ZeP+YePEWfP7bej4YefCYd/7cuP7WfcPb/URYeMRbesObi/=" # 待解密的base64编码
string1 = "LMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/ABCDEFGHIJK" #替换的表
string2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
print (base64.b64decode(str1.translate(str.maketrans(string1,string2))))
总结 ¶
base 家族编码都不算难,根据特征特点找到对应的加解密方式就可以了。下面总结一下各个 base 编码的特点。
-
base16 特征:由大写字母(A-Z)和数字(0-9)组成,通常不需要“=”填充
-
base32 特征:由大写字母(A-Z)和数字(2-7)组成,需要“=”填充
-
base64 特征:大小写字母(a-Z)和数字(0-9)以及特殊字符('+','/')不满 3 的倍数用“=”补齐,结尾有少量等号
-
base58 特征:同 base64 相比,少了数字‘0’和字母‘O' 数字’1‘和字母’I‘以及 '+' 和 '/' 符号 , 也没有“=”
-
base85 特征:有很多奇怪的符号,但一般没有“=”
-
base91 特征:由 91 个字符(0-9,a-z,A-Z,!#$%&()*+,./:;<=>?@[]^_`{|}~”)组成
-
base100 特征:全是 emoji 表情。
其他编码 ¶
- UUencode、XXencode
- QR Code 二维码:介绍
- 条形码
- 盲文编码
- 一些其他好玩的类编码:
- 北约音标字母
- 地点三词编码 What3Words
信息搜集 | OSINT ¶
Open Source INTelligence | 公开信息情报
Information Protection & OSINT resources
Don't be evil
构造了一个全新的虚拟身份 ¶
sherlock:sherlock-project/sherlock
namechk:https://namechk.com/
图片、文档等附件泄漏 ¶
一些常用的搜索引擎: - 百度识图搜索:中文互联网图片搜索结果 - Google 图片搜索:用来搜索外国范围的图片 - Bing 图片搜索:和 Google 差不多,都可以参考 - Yandex 图片搜索:搜索相似图片;搜索风景时更常用 - TinEye:搜索完全相同的图片(找来源)
图片信息 注意图片中的文字、牌匾、标志性建筑等,可用来作为关键词搜索
如果图片中关键信息较少,可以优先考虑使用搜索引擎识图 2023
- 太阳角度、阴影长度等太阳相关
- https://www.suncalc.org/
- https://www.sunearthtools.com/cn/index.php 时间 <=> 位置互相估计
- 天气信息、云层信息等
- 飞机航班信息
- https://flightaware.com/
- 估计方向,位置,时间等
- 风景信息 -> Yandex 搜索
几何学信息解算楼层 如何根据一张照片判断出女孩住在几层楼?
文档信息泄露
(metadata)可能包括作者、修改时间等信息 - 图片的 EXIF 信息,可通过 exiftool 查看 - 一般以 xml 形式存储,可以直接通过二进制抹除,或者通过操作系统
- Visual Studio 的各种配置文件,
.vs文件夹中信息 .vscode文件夹中的配置文件.git文件夹,泄漏全部修改历史、提交信息、提交者等
.DS_Store文件,macOS 下的文件夹布局信息- 前面各种工程配置文件等也会泄漏(比如 vs 的 pdb 调试信息)
- markdown 文件图片路径(本地路径 / 图床用户 / 自建图床网站)
文件隐写 ¶
文件系统 ¶
不同的文件系统,不同的组织方式 - MS 派:FAT、NTFS、exFAT、ReFS - Apple 派:HFS、APFS - Linux 派:ext[234]、XFS、Btrfs、ZFS… 文件是一串二进制数据 在 HDD 上是微小磁极的磁化方向;在 SSD 上是电荷的存储状态
文件名 “文件名”是由文件系统管理的,不是文件本身数据的一部分 - 文件系统会记录文件名、文件大小、创建时间、修改时间等信息 - 文件内容才是真正的数据
文件类型 ¶
扩展名 .jpg .webp .txt .docx ..是文件名的一部分,可以随意修改(在一些桌面环境下);决定了打开文件的默认程序
内容 - 通过文件内容来识别文件类型(√) - file 命令:根据文件内容判断文件类型 - 不同文件类型有不同的“魔数”
| 文件类型 | 文件头 | 对应 ASCII |
|---|---|---|
| JPEG | FF D8 FF | … |
| PNG | 89 50 4E 47 0D 0A 1A 0A | .PNG.... |
| GIF | 47 49 46 38 39 61 | GIF89a |
| 25 50 44 46 | ||
| ZIP | 50 4B 03 04 | PK.. |
| RAR | 52 61 72 21 | Rar! |
| 7zip | 37 7A BC AF 27 1C | 7z..'. |
| WAV | 52 49 46 46 | RIFF |
文件结束 ¶
大部分文件类型都有一个标记文件内容结束的标志 - 比如 PNG 的 IEND 块、JPEG 的 EOI 标志(FF D9)
所以一般在文件末尾添加其他字节时,不会影响原文件本身的用途,因此有些隐写是将数据隐藏在文件末尾达到的
附加文件的识别
- exiftools
- binwalk
附加文件的分离
- binwalk 或 foremost 识别并分离
- dd if=<src> of=<dst> bs=1 skip=<offset> 手动分离
- 图像末尾叠加一个压缩包,就是所谓的“图种”
- 修改后缀名可能可以解压(部分解压软件会忽略前面的图像)
- 其实不如直接分离
图片格式 ¶
图像需要存储什么
- 图像信息:宽高、色彩模式、色彩空间等
-
EXIF 信息:拍摄设备、拍摄时间、GPS 信息等
-
像素数据:每个像素的颜色信息;二值、灰度、RGB、CMYK、调色盘等 BMP 格式
压缩算法 - PNG 无损,JPEG 有损 - GIF 有损且只支持 256 色 - 新兴格式如 HEIF、WebP、AVIF 等
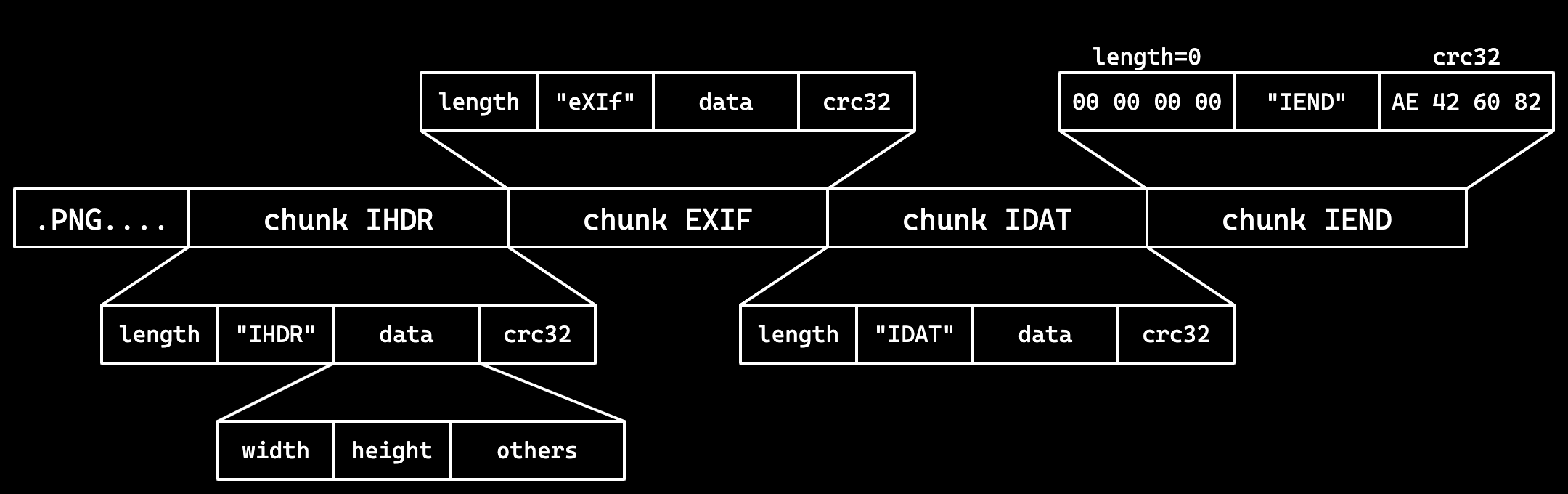
- 文件头
89 50 4E 47 0D 0A 1A 0A | .PNG....采用分块的方式存储数据, 每块的结构都是 4 字节长度 + 4 字节类型 + 数据 + 4 字节 CRC 校验 - 四个标准数据块:IHDR、PLTE、IDAT、IEND
- 其他辅助数据块:eXIf、tEXt、zTXt、tIME、gAMA……
- eXIf 元信息,tIME 修改时间,tEXt 文本,zTXt 压缩文本

JPEG 使用分段的结构来进行存储,各段以 0xFF 开头,后接一个字节表示类型: |开始|作用| |—|—| |FFD8(SOI)|文件开始| |FFE0(APP0)|应用程序数据段,包含文件格式信息(上图没有)| |FFE1(APP1)|应用程序数据段,包含 EXIF 信息(上图没有)| |FFDB(DQT)|量化表数据| |FFC0(SOF)|帧数据,包含图像宽高、色彩模式等信息| |FFC4(DHT)|huffman 表数据| |FFDA(SOS)|扫描数据,包含数据的扫描方式,huffman 表的使用方式等| |FFD9(EOI)|文件结束|
JPEG 的压缩原理是 DCT(离散余弦变换)+ Huffman 编码 - 由 RGB 转换到 YCbCr,然后减少 Cb、Cr 的采样率 - 将图像分块,每个块 8x8,进行 DCT 变换,将图像转换为频域,便于压缩高频部分 - 量化,将 DCT 变换后的系数除以量化表中的系数:再次减少高频部分的数据,根据不同的量化表,可以调整压缩质量 - 通过游程编码和 huffman 编码进行压缩
IHDR:包含图像基本信息,必须位于开头
- 4 字节宽度 + 4 字节高度
- 1 字节位深度:1、2、4、8、16
- 1 字节颜色类型:0 灰度,2 RGB,3 索引,4 灰度透明,6 RGB 透明
- 1 字节压缩方式,1 字节滤波方式,均固定为 0
- 1 字节扫描方式:0 非隔行扫描,1 Adam7 隔行扫描
PLTE:调色板,只对索引颜色类型有用 ,把像素编码,变成索引编码
IDAT:图像数据,可以有多个,每个数据块最大 2 31 -1 字节
IEND:文件结束标志,必须位于最后,内容固定
PNG 标准不允许 IEND 之后有数据块 结尾时AE 42 60 82
- PNG 使用 Deflate 压缩算法 : 是 LZ77 结合 huffman 编码的一种压缩算法 ;LZ77:利用滑动窗口,找到最长的重复字符串,用指针和长度表示
- 会进行滤波,减少数据的冗余性,提高压缩率 ; 五种滤波器:None、Sub、Up、Average、Paeth
图片隐写 ¶
两篇博客 CTF MISC图片隐写简单题学习思路总结(持续更新)_ctf jpg 末尾隐写-CSDN博客
常见的隐写工具的使用 _stegoveritas-CSDN 博客
WorkFlow
- 使用
file查看信息,使用exiftool检查图片元信息,看看有没有看起来会有用的信息 - 使用十六进制编辑器打开,观察文件中有无附带信息、图片基本格式是否正确
- 使用
binwalk检查文件末尾是否叠加了多余的文件 - 使用
stegsolve打开图片 / 或者使用CyberChef - 使用
steghide extract -sf <file> -p <passwd>解密数据 zsteg:自动检测隐写,zsteg <file>stegoveritas -steghide <file>- 观察各个通道的
bit plane - 使用
Extract LSB尝试提取数据格式的 LSB(或者使用zsteg猜测) - 考虑能否查找原图,如果找到了尝试进行比较
- 考虑是否是使用工具进行的图片隐写,多尝试一些常见的工具
图像大小修改 ¶
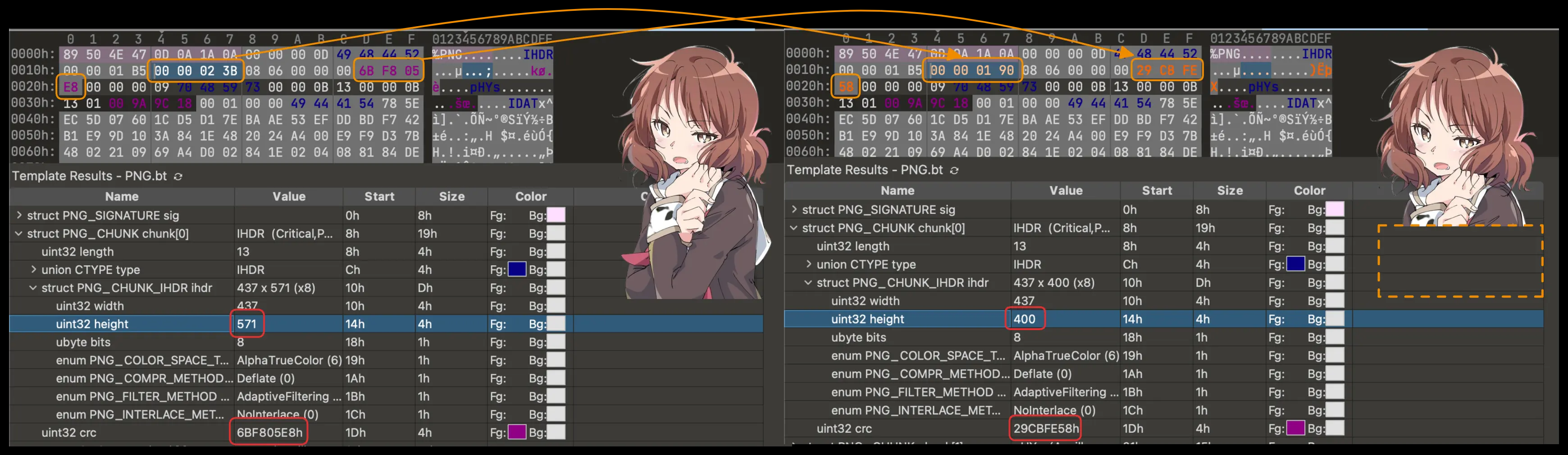 - PNG 图像按行进行像素数据的压缩,以及存储 / 读取
- 当解码时已经达到了 IHDR 中规定的大小就会结束
- 因此题目可能会故意修改 IHDR 中的高度数据,使之显示不全
-恢复的话更改高度即可,同时注意 crc 校验码,否则可能报错
- PNG 图像按行进行像素数据的压缩,以及存储 / 读取
- 当解码时已经达到了 IHDR 中规定的大小就会结束
- 因此题目可能会故意修改 IHDR 中的高度数据,使之显示不全
-恢复的话更改高度即可,同时注意 crc 校验码,否则可能报错
binascii.crc32(data),data 为从 IHDR 开始的数据 ( 包含 IHDR)
需要原图的图片隐写 ¶
使用识图工具进行搜索 一般需要搜原图的题题目描述会带有来源暗示之类的 多注意搜到的图像大小、质量,确保是真正的原图 接下来利用原图和隐写图像的差异进行分析
图像像素异或观察差异
- PIL 手动处理 /
ImageChops.difference - stegsolve image combiner
盲水印系列 - 给了打水印的代码的话直接尝试根据代码逆推即可 - 没有给代码的可能就是常见的现有盲水印工具
LSB 图片隐写 ¶
LSB 全称为 least significant bit,是最低有效位的意思
LSB 隐写将颜色通道的最低位用来编码信息 - 图像:stegsolve / CyberChef View Bit Plane - 数据:stegsolve / CyberChef Extract LSB / zsteg / PIL
# PIL库的使用
from PIL import Image #导入和图像读写处理有关的 Image 类
img = Image.open(file_name) #打开图像
img.show() 显示图像;img.save(file_name) #保存图像
img.size #图像大小
img.mode #图像模式
img.convert(mode) #转换图像模式
img.getpixel((x, y)) #获取像素点颜色
img.putpixel((x, y), color) #设置像素点颜色
np.array(img) #将图像转换为 numpy 数组
具体图像模式 - '1':黑白二值(0/255);'L':灰度(8 bit),'l':32 bit 灰度 - L = 0.299 R + 0.587 G + 0.114 B - 'P':8bit 调色盘,获取的像素值是调色盘索引 - 'RGB'、'RGBA' - 'CMYK':转换时有色差,CMY = 255 - RGB,K = 0 - 'YCbCr'、'LAB'、'HSV' 等,转换时有复杂公式(可能出现新的隐写)
PIL 其他模块用途 - ImageDraw 用于绘制图像、绘制图形 - ImageChops 用于图像通道的逻辑运算 - ImageOps 用于图像整体的运算一类 - ImageFilter 用于图像的滤波处理
人为隐写 ¶
- JPEG 中 DCT 系数可以进行 LSB 隐写
- JPEG 中 DHT 定义的 huffman 表可能有冗余项,可以隐写
- PNG 中附加多余 IDAT 数据块的隐写(显示时被忽略)
- PNG 中使用调色盘时可以进行调色盘隐写(EZStego 隐写)
工具隐写 ¶
steghide、stegoveritas、SilentEye 等 一般找到了类似密码一类的大概率是工具题
音频隐写 ¶
使用 Python 的 soundfile / librosa 库进行音频处理
mp3:有损压缩
wav:无损无压缩(waveform) - 直接存储的是音频的波形数据,可操作性更高 - 文件结构也是分 chunk 的,有 RIFF、fmt、data 等 - 编码音频数据的 sample 也可以进行 LSB 隐写
flac:无损压缩,如果出现可能考虑转换为 wav
音频叠加 ¶
如果可以找到原音频,或提供了原音频,可以进行比较
方法是在 Audition 中创建多轨会话 - 将两个音频拖入两个轨道 - 效果 > 匹配响度,将两条音轨的响度匹配 - 点进其中一条音轨,效果 > 反相,将波形上下颠倒 - 两条音轨匹配上波形之后播放 / 混音,就能听到差异了
频谱隐写 ¶
一般使用 Adobe Audition 打开来进行进一步的分析
频谱隐写是观察音频的频谱图,可能会有部分信息经过了调整
压缩 ¶
ZIP 也使用分段的方式存储数据 - 本地文件记录 50 4B 03 04,可以有多个 - 中央目录记录 50 4B 01 02,可以有多个 - 中央目录结束 50 4B 05 06 在中央目录记录中有一个字段记录加密方式 - 如果不为 0 表示有加密 其他字段,如最小版本 - 可能修改为一个不合法的值,无法用解压软件解压
沙箱逃逸 ¶
- 沙箱:做了某些限制的隔离环境;例如 Docker,或一个沙箱程序,如 rbash;Python 解释器也可以作为一个沙箱
- 通过限制模块、限制函数、代码审计等方式
- 沙箱逃逸就是在沙箱中执行代码,获取到沙箱外的权限
- Python 的 os 及 importlib 模块是常见的逃逸点
PPC¶
Quine¶
流量取证 ¶
流量取证一般就是拿到这些数据包(cap、pcap、pcapng 格式)进行分析
- 如有损坏的话修复数据包(少见,pcapfix 可以修复)
- 分析、提取得到正在通信的内容(可能包含有效信息)
- 分析一些特定的、不太常见的协议(比如一些自定义协议)
- 分析、解密一些加密的协议(比如 VMess 等)
常用工具 ¶
- tcpdump 抓 TCP 包(Linux 命令行)
- Wireshark 直接抓包,得到物理层的全部数据并解析(开源)
- 自带命令行工具 tshark:官网,可以再 wireshark 中筛选,然后得到对应的指令 一文读懂网络报文分析神器Tshark: 100+张图、100+个示例轻松掌握-腾讯云开发者社区-腾讯云
- termshark 类似 Wireshark 的开源命令行工具
- pyshark:tshark 的 Python 封装,可以用 Python 脚本分析
- scapy:Python 库,也可以用来分析流量包
HTTP 协议流量分析 ¶
- 分析统计信息,查看所有的 HTTP 请求 URI
- 分析 HTTP 往返的情况,流量整体信息
- 具体分析某些请求:利用过滤器
- 分析某一数据包具体内容:跟踪流,跟踪 TCP 解析 TCP,跟踪 HTTP 可以自动解压 gzip 等;分析请求头、响应头、请求体、响应体等 Wireshark分析sql布尔盲注流量包_sql注入wireshark抓包分析-CSDN博客
其他协议 ¶
ICMP 协议:ping 某时也会带有一些信息,可以进行进一步分析 OICQ 协议:QQ 使用,是加密的,但是可以看到双方 QQ 号等
WIFI 协议(IEEE 802.11) 可以使用 Linux aircrack 套件爆破密码 有了密码后可以在 Wireshark 中设置并解密流量
Kali-WIFI 攻防 ( 二 )---- 无线网络分析工具 Aircrack-ng_airdecap-ng-CSDN 博客
USB 协议 安装了 USBcap 之后可以在 Wireshark 中捕获 USB 流量 有工具可以解析流量,绘制鼠标轨迹,得到按键信息等
VMess,需要读文档 / 源码,实现解密
内存取证 ¶
先 strings ¶
提取出文件中所有的 ASCII 字符串,没准就发现有效信息秒杀了 会有超多,可以输出到文件然后搜索,或者直接 grep strings mem.raw | grep "flag" 提取 Unicode 字符 strings -el
再上 volatility ¶
- 开源的内存取证工具,可以分析 Windows/Linux/macOS
- 先识别系统信息
- 针对不同系统使用不同命令分析
- 能跑的都跑一遍,注意看输出