Zero-Query Adversarial Attack on Black-box Automatic Speech Recognition Systems¶
约 1786 个字 预计阅读时间 7 分钟
珞珈学子成果被 ACM CCS 2024 录用 - 武汉大学新闻网
Zero-Query Adversarial Attack on Black-box Automatic Speech Recognition Systems
相关背景问题是什么?¶
Adversarial Attack: change behavior to avoid detection
Black Box¶
White-box attack – Attackers have full knowledge about the ML model.
Black-box attack – Attackers don’t have access to the ML model parameters, gradients,architecture – Know about used ML algorithm
Zero-Query:Don’t get query samples and query results
对于黑盒模型来说,需要考虑两方面的问题
一个是替代模型:当我们想对一个平台提供的黑盒模型进行攻击时,一种可行的方法是先训练一个与目标模型具有相似决策边界的本地模型,之后对本地模型进行白盒攻击得到对抗样本,再利用迁移性实现对目标模型的攻击,这个部署在本地的模型即为替代模型。
迁移性:假设对抗样本具有迁移性,即当一个对抗样本可以成功攻击一个模型时,它也很有可能成功攻击另一个相似的模型。
ASR | Automatic Speech Recognition Systems¶
ASR 不解决听不听懂的问题,而更关心听没听清的问题
作者研究发现,当前的智能语音识别系统主要基于注意力机制或卷积神经网络两类深度学习模型实现。
端到端 ¶
端到端模型直接将原始数据作为输出返回输出结果,非端到端模型需要使用经过数据处理后的处理数据作为模型输入
现有难点 ¶
- 目标模型是个黑盒,我们得不到相关的模型结构、参数或者训练数据;
- 在使用目标模型进行图像分类时,通常只能得到该图像的唯一标签,并且没有准确率;
- 调用 API 接口的查询次数有限,过多的查询除了带来成本上的负担外,还有可能被平台的异常检测程序制裁。
语音系统需要处理时间维度上的信息变化,这比图像分类系统要复杂得多。其次,音频采样率通常很高(例如 16kHz,这意味着每秒采样 16,000 个点
最后产生的变化需要让用户感知尽可能小
Prior works on black-box adversarial attacks on ASR systems do not require the attacker to know internal information about the target ASR system, but they still assume that the attacker can interact with the target system. In this paper, we consider a more realistic and challenging scenario where the attacker also cannot query the target ASR system during the generation of adversarial examples
解决方案 ¶
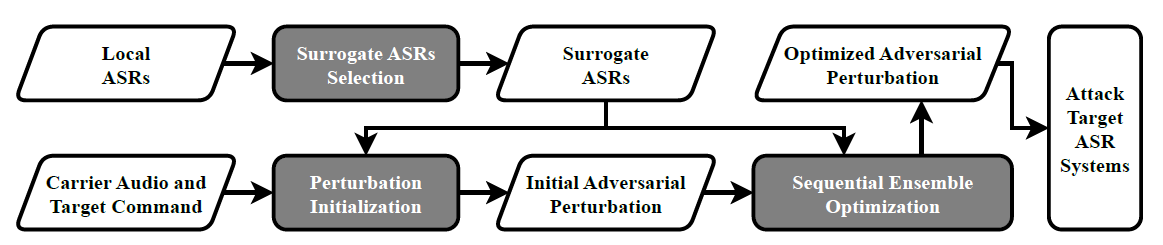
多替代模型 ¶
intuiitve way 既用 CNN 又用 transformer
We investigate modern ASR systems and categorize them into two main types: CNN-based and Transformer-based. While CNNs are more adept at capturing local features, Transformers excel at capturing global contexts. Therefore, an intuitive approach is to select surrogate ASRs that include both CNN-based and Transformer-based architectures, ensuring that the adversarial perturbations optimized on these surrogate ASRs concurrently possess both local and global features of the target command.
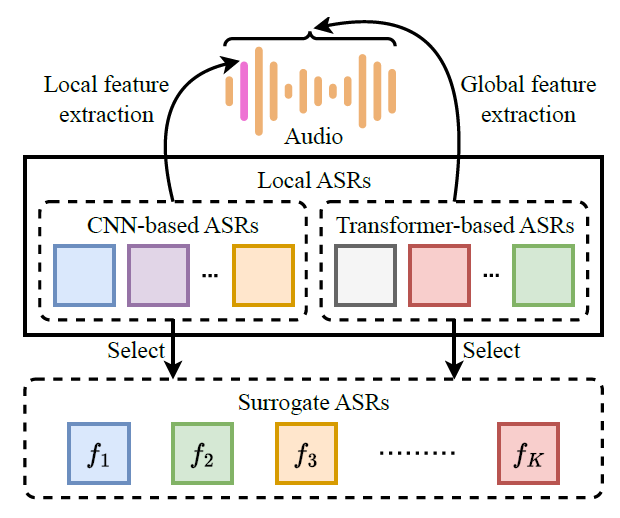
初始化 ¶
首先使用 TTS 方法生成扰动 \(x_t\), 其次对 \(x\) 和 \(x_t\) 应用缩放
其次使用了一种自己设计的动态的对抗扰动初始化方法
the adaptive search algorithm searches for the smallest value of scaling factor μ, and δ is initialized using the scaled target command audio μ · xt , ensuring that the corresponding initial adversarial example is recognized by all surrogate ASRs as the target command
I've made a chart to understand this process.
集成优化 ¶
Following the perturbation initialization stage, ZQ-Attack employs a sequential ensemble optimization algorithm to collaboratively optimize the adversarial perturbation on the ordered set of surrogate ASRs. This algorithm consists of an inner loop and an outer loop. In each iteration, the ordered set of surrogate ASRs is randomly shuffled in the outer loop.
考虑每个之间的影响
这个公式有记忆功能,调整 \(\eta\) 的值就可以决定每轮 \(\delta_0\) 的影响的占比
Then, the sequential ensemble optimization takes place within the inner loop. For each surrogate ASR, this algorithm integrates collaborative information from all preceding surrogate ASRs in the ordered set, facilitating collaborative optimization
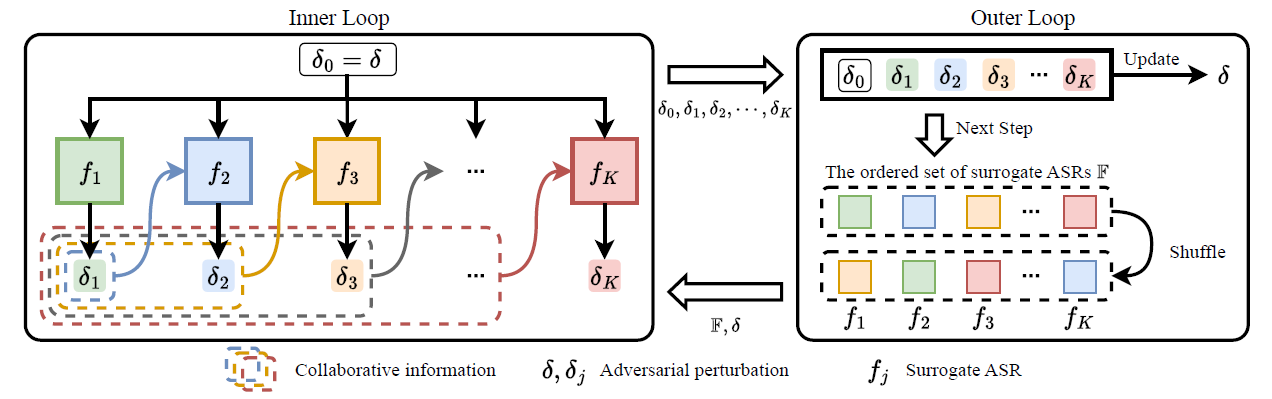
序列化的集成优化算法
$$ text{clip}_epsilon(delta, x) = max(min(delta, epsilon cdot |x|), -epsilon cdot |x|), $$ 这个函数看起来比较复杂,但其实就是在音量较大的部分,允许的扰动更大,而在音量较小的部分,扰动被严格限制,从而减少了人耳对小扰动的察觉。这种自适应扰动可以减少对原音频的可感知干扰。
这里加入了高斯扰动项目,在内环的时候,使用梯度进行 \(\delta\) 值的更新
loss function¶
考虑了三重因素,加权求和
- adversial attack
- 不可感知性:设计一种新的度量方式:
- 特征提取:使用了 \(L_2\)norm
实验验证 ¶
实验设计:本文在两种设置下进行了广泛的实验,包括在线语音识别服务、商业 IVC 设备和开源 ASR。在每种设置下,都选择了不同的目标 ASR 系统,并使用 ZQ-Attack 生成音频对抗示例来攻击它们。
实验数据和结果:
- 在线语音识别服务:在在线语音识别服务设置下,ZQ-Attack 在 4 个不同的服务上取得了 100% 的成功率,平均信号噪声比 (SNR) 为 21.91dB。
- 商业 IVC 设备:在商业 IVC 设备设置下,ZQ-Attack 在 2 个不同的设备上取得了 100% 的成功率,平均 SNR 为 15.77dB。
- 开源 ASR:在开源 ASR 设置下,ZQ-Attack 在 16 个不同的 ASR 上取得了 100% 的成功率,平均 SNR 为 19.67dB。 这些实验结果表明,ZQ-Attack可以生成具有高转移性和高成功率的音频对抗示例,以攻击各种ASR系统。
不足:
计算成本:ZQ-Attack 需要在多个代理模型上优化对抗扰动,这可能会导致较高的计算成本。 不可感知性:尽管ZQ-Attack在over-the-line设置下具有较好的不可感知性,但在over-the-air设置下可能仍然可以被人类察觉。
对你的启发 ¶
Through the process of this class, I have adopted the fundamental methods of reading papers at first,by the way , it's also my first experience to read a paper in English for begining to end and figure out each formula.
I download paper managing tools like Zotero, and i have also learned how to gather information through platforms like Google Scholar and Arxiv.
Furthermore, I've discovered that most of the latest thesis and information in frontier areas are in English, as few thesis themselves are mostly in English and there isn't an atmosphere of sharing up-to-date on Today's Chinese Internet. Therefore, I appreciate this opprotunity to learn and
零查询黑盒攻击:本文展示了在零查询黑盒设置下,如何生成具有高转移性的音频对抗示例以攻击各种 ASR 系统。这为其他类型的黑盒攻击提供了新的思路。
集成优化:本文提出的序列集成优化算法可以应用于其他类型的集成模型,以提高其性能和鲁棒性。