性能度量 ¶
约 1778 个字 预计阅读时间 7 分钟
机器学习:分类模型评估指标(准确率、精准率、召回率、F1、ROC 曲线、AUC 曲线)_ 二分类模型准确率多少才算高 -CSDN 博客
性能 ¶
\(经验性能E \approx 泛化性能E^*\)
iid 假设:训练集和测试集是独立同分布的 identical and independently distributed
定义 ¶
"Training Error and Test Error" - Training error is the error alculated on the training data. - Test error is the error calculated on the test data.
use test error to evaluate the quality of model
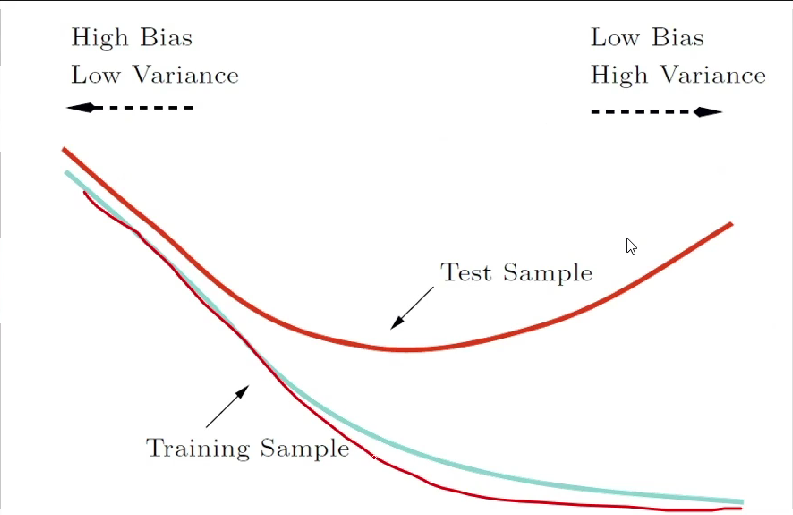
不同的算法就是在用不同的方式去达到平衡点
overfitting 过拟合
更复杂的模型:更小的 training error
- 优化目标,加入正则化项,使得模型更简单
- early stopping
Ridge Regression:
$$ min_{omega} sum_{i=1}^n (y_i - omega^T x_i)^2 + lambda |omega|^2 $$ 简介:岭回归
欠拟合:对训练样本的一般性质没有学好
- 决策树:拓展分支
- 神经网络:增加训练轮数

评估方法 ¶
理解方法:题库出小测题目
hold-out:¶
- 直接将数据集划分为两个互斥集合——训练集和测试集。在划分训练集和测试集时,要尽可能保持数据分布的一致性。
- 使用分层采样(stratified sampling)方法,以保持类别比例一致。
- 一般进行若干次随机划分,重复实验并取平均值。
- 训练集和测试集的样本比例通常为 2:1 或 4:1,效果还不错。

交叉验证法¶
- 分层采样划分数据集:将数据集分层采样划分为 K 个大小相似的互斥子集。
- 训练和测试:每次使用 K-1 个子集的并集作为训练集,剩下的一个子集作为测试集。
- 重复实验:重复上述过程 K 次,每次都使用不同的子集作为测试集。
- 计算平均值:最终返回 K 个测试结果的平均值
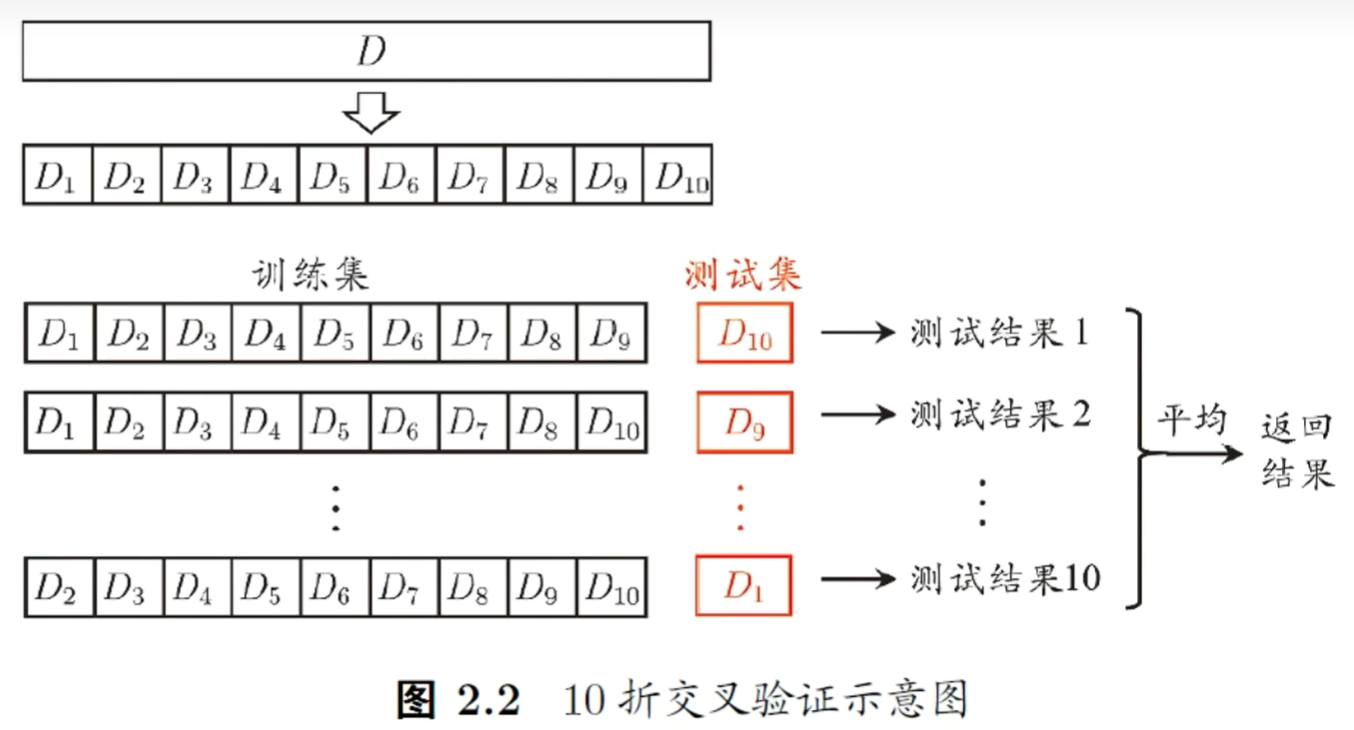
记得设置 seed,来保证可重复性
LOO leave-one-out:留一法,最接近于理想情况,开销太大,NFL
猜测进教室性别问题
男生多猜男生,女生多猜女生
自助法 bootstrap ¶
包外估计,有 36.8% 不出现

- 改变了数据的分布
性能度量 ¶
作为设计自己度量的一种启发
回归 ¶
- MSE:
- MAE:
memory consumption
platform required for running
CPU vs GPU
server,workstation
混淆矩阵 ¶
先介绍一下混淆矩阵(T/F: 预测是否正确,P/N:预测是正类还是负类) - TP:预测为正类,实际为正类,预测正确。 - FP:预测为正类,实际为负类,预测错误。 - FN:预测为负类,实际为正类,预测错误。 - TN:预测为负类,实际为负类,预测正确。
准确率 | Accuracy
正类和负类中预测正确的数量占总数量的占比。
\(Accuracy=\frac{T P+T N}{T P+F P+F N+T N}\)
准确率不可导,无法作为 cost function 去做训练,只能用作评估。
正类和负类预测正确的重要性不一样,比如对于癌症检测来说,可能负类 ( 没有患癌症 ) 预测正确的数量非常大,就导致 Accuracy 的分子非常大,得到的 Accuracy 就非常大,但是可能正类 ( 患癌症 ) 预测正确的数量非常小,就导致虽然模型的准确率很高,但根本检测不出癌症。
如果正类样本非常多,即使不做任何学习,也可以得到很高的准确率
解决问题的方案:采用精确率或者召回率
查准率和查全率
- 查准率 Precision:即你认为是 True 的样本中,到底有多少个样本是真为 True。
- 查全率 Recall:即在预测样本中属于 True 的样本,你真的判断为 True 的有几个。
- 真阳性率(True Positive Rate,TPR)通常也被称为敏感性(Sensitivity)或召回率(Recall
) 。它是指分类器正确识别正例的能力。真阳性率可以理解为所有阳性群体中被检测出来的比率 (1- 漏诊率 ),因此 TPR 越接近 1 越好。它的计算公式如下:\(precision=\frac{T P}{TP+FP}\)
- 假阳性率 (False Positive Rate, FPR) 假阳性率(False Positive Rate,FPR)是指在所有实际为负例的样本中,模型错误地预测为正例的样本比例。假阳性率可以理解为所有阴性群体中被检测出来阳性的比率(误诊率),因此FPR越接近0越好。它的计算公式如下 FP = frac{FP}{FP+TN}
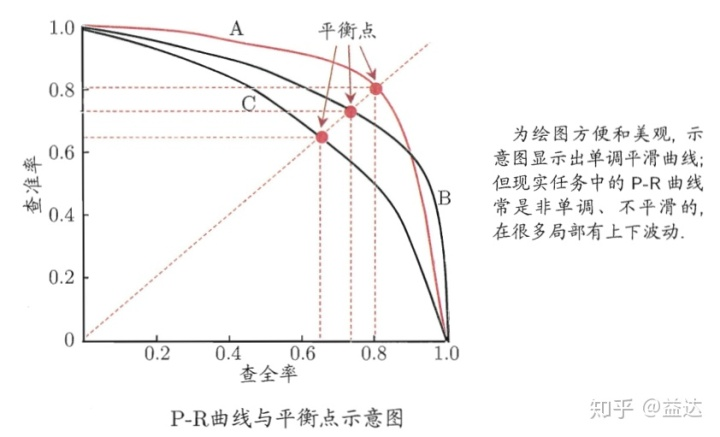
P-R 曲线绘制原理及代码实现 _ 求 p-r 曲线的代码 -CSDN 博客
F1 度量:
\(F 1=\frac{2 \times \text { precision } \times \text { recall }}{\text { precision }+\text { recall }} = 、\frac{2\times TP}{总数 + TP -TN}\)
F1 是 P 和 R 的调和平均
对查准率、查全率有不同的偏好 \(F_\beta = \frac{(1+\beta^2)\times P\times R}{(\beta^2 \times P) + R}\) \(\beta = 1\):标准F1
\(\beta > 1\): 偏重查全率(逃犯信息检索)
\(\beta < 1\): 偏重查准率,商品推荐系统
ROC & AUC¶
绘制方法:给定 \(m^+\) 个正样本和 \(m^-\) 个负样本,对于每个样本,计算其预测概率,然后按照概率从大到小排序,然后逐个样本计算 TP rate 和 FP rate,然后绘制 ROC 曲线。
预测准确,增加 y 值;预测错误,增加 x 值;
AUC
AUC(ROC 曲线下面积)是 ROC 曲线下的面积,用于衡量分类器性能。AUC 值越接近 1,表示分类器性能越好;反之,AUC 值越接近 0,表示分类器性能越差。在实际应用中,我们常常通过计算 AUC 值来评估分类器的性能。
理论上,完美的分类器的 AUC 值为 1,而随机分类器的 AUC 值为 0.5。这是因为完美的分类器将所有的正例和负例完全正确地分类,而随机分类器将正例和负例的分类结果随机分布在 ROC 曲线上。
综上,ROC 曲线和 AUC 值是用于评估二分类模型性能的两个重要指标。通过 ROC 曲线,我们可以直观地了解分类器在不同阈值下的性能;而通过 AUC 值,我们可以对分类器的整体性能进行量化评估。
性能评价 ¶
- 测试性能不等于泛化性能
- 测试性能随着测试集的变化而变化
假设检验: 有多少把握在统计意义上说这个模型是好的
bias and variance decomposition¶
- bias: 最好的模型和 ground truth 之间的差距 ; 模型的上限 ; training error
- variance: 最优的模型和最差的模型之间的差距;模型的下限 ; the difference between training error and test error
prediction error = bias + variance + noise
- high bias, low variance: underfitting
- low bias, high variance: overfitting
- low bias, low variance: good model
改进策略
underfitting: - add more features - use more complex model - descrease regularization
overfitting: - decrease model complexity - decrease number of features - add more regularization - add more data
train val test
60% 20% 20% - training set: train the model - validation set: tune the hyperparameters - test set: evaluate the model