人工智能与机器学习 作业 ¶
约 1770 个字 95 行代码 预计阅读时间 8 分钟
人工智能的两个阶段目标——制造智能机器、实现机器智能
简介 ¶
人工智能与机器学习是控院臭名昭著的课程。某任课老师在课堂面对同学们对于课堂的疑问,表示
无敌。
在 Mo 实验平台上有 4 个个人作业,和一个小组作业。个人作业分别是:双向情感障碍、口罩检测、作家风格识别
小组作业有些班级是需要在 Mo 平台完成后,再在班级上进行小组 ppt 展示
2021 级应该是选黑白棋的人最多,22 级选黑白棋的人稍微少一点,但是也挺多的。
做完这几个实验的感觉就是完全没有必要浪费时间在上面
Mo 平台的体验完全不如隔壁 Kaggle,又因为是 HUAWEI 开发的,有些题目还要用 HUAWEI 的 mindspore 架构。
Mo 的评分方式是在线运行后评测的,所以每次评测都需要重新跑一遍,非常浪费时间。
现有资源整理 ¶
自动化也是好起来了,现在传资料的人越来越多了嘿嘿,感谢各位前辈的分享
- the_Piao: MO平台编程作业分享 - CC98论坛
- 逐梦xcdh: for-mydream/ZJU_CSE_ML_Lab
- zhaowei123: ZJU_CSE_人工智能与机器学习
- Y-vic/ZJU_AI_ML_Lab: ZJU人工智能与机器学习四个lab
- AI_Course/MobileNet2 ZoRax-A5/AI_Course
- Luhaozhhhe/Introduction_to_Artificial_Intelligence: NKU-COSC0015-人工智能导论
Mo 平台指北 ¶
如何删除文件 ¶
Mo 平台应该使用的是一个 Jupyter Notebook,因为用户名是 jovyan
但是平台应该在前端限制了一些操作,比如说删除main.ipynb和results文件夹就是被限制的。
所以就需要使用命令行来删除文件。
点击新建 console, 进入到命令行界面
rm -rf main.ipynb
rm -rf results/
如何下载到本地 ¶
如果有同学想要在本地训练,那么每次一个一个上传文件肯定是特别麻烦的
这里使用 zip 或者 tar 的方法打包一下
zip -r main.zip ./*
unzip main.zip
scp main.zip <username>@<ip>:<path>
scp <username>@<ip>:<path> <path>
这里需要有一些使用 ssh 的经验
如何使用 GPU 进行训练 ¶
我用它这个 GPU 训练比较少,一般都是在自己的 GPU 下进行训练,参考
点击上方的按钮可以进入到这个界面
 选择使用GPU进行训练,选择相关的文件就可以开始训练了
选择使用GPU进行训练,选择相关的文件就可以开始训练了
如何测试 ¶
点击测试,会让你选择用到的文件,一般无脑全选就行,有些时候需要取消选择没有用到的架构(比如torch_py)
如果需要提交的话,需要主目录下有程序报告.pdf文件,只有一次提交机会
由于不知道后台的评分机制,所以不清楚直接touch 程序报告.pdf是否会影响最后的分数
卡住了怎么办 ¶
我在使用的过程中遇到了完全卡在页面上,点不了任何文件的问题 (edge 浏览器 )
换成了 chorme 浏览器,问题解决
手写数字识别和垃圾分类 ¶
题目
LeNet5 + MNIST 被誉为深度学习领域的 “Hello world”。本实验主要介绍使用 MindSpore 在 MNIST 手写数字数据集上开发和训练一个 LeNet5 模型,并验证模型精度。
通过以上学习,使用 MindSpore 深度学习框架实现 26 种垃圾进行分类。
MindSpore 是最佳匹配 Ascend(昇腾)芯片的开源 AI 计算框架,同时也支持 CPU、GPU 平台。访问 MindSpore 官网了解更多:https://www.mindspore.cn/
深度学习计算中,从头开始训练一个实用的模型通常非常耗时,需要大量计算能力。常用的数据如 OpenImage、ImageNet、VOC、COCO 等公开大型数据集,规模达到几十万甚至超过上百万张。网络和开源社区上通常会提供这些数据集上预训练好的模型。大部分细分领域任务在训练网络模型时,如果不使用预训练模型而从头开始训练网络,不仅耗时,且模型容易陷入局部极小值和过拟合。因此大部分任务都会选择预训练模型,在其上做微调(也称为 Fine-Tune
本实验以 MobileNetV2+ 垃圾分类数据集为例,主要介绍如在使用 MindSpore 在 CPU/GPU 平台上进行 Fine-Tune。
这个题目使用的是 MobileNetV2,然后使用 MindSpore 框架
不太喜欢这个框架,所以使用了自己的结构
因为另一门课程有作业也是分类任务,所以这里使用了 pytorch 的架构
进行了一些训练,最后使用的是 timm 库中seresnext50_32x4d.racm_in1k这个模型进行微调的。
使用了 4:1 的训练集和测试集,训练出了两个模型,做投票集成
达到了 92% 的准确率

经过同学提醒,predict 中输入的图像颜色通道是反的,所以需要将 BGR 变成 RGB
image = Image.fromarray(np.array(image)[:, :, ::-1])
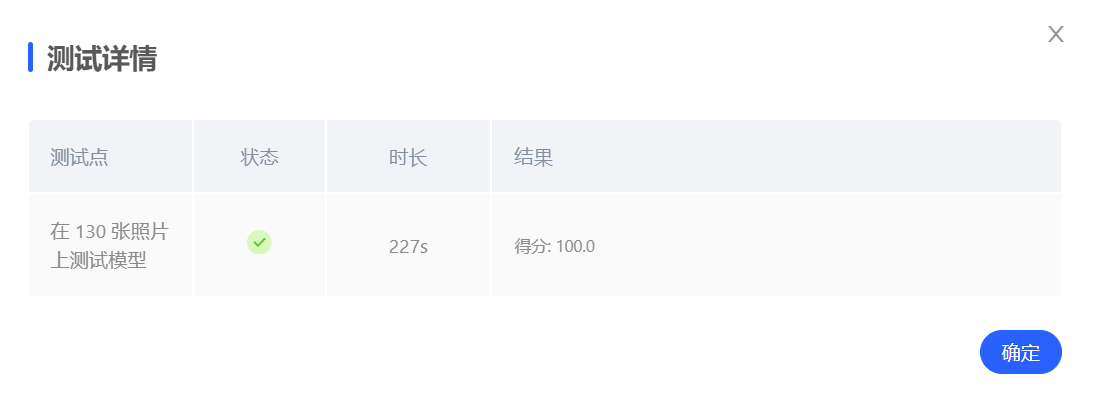
切换以后,模型在测试上达到了 100% 的准确率
import torch
from PIL import Image
import torchvision.transforms as transforms
import torch.nn as nn
import os
import numpy as np
os.system(f'pip install timm') # 注意这里需要安装timm
os.system(f'pip install ttach')
import timm
import ttach as tta
inverted = {
0: 'Plastic Bottle', 1: 'Hats', 2: 'Newspaper', 3: 'Cans', 4: 'Glassware', 5: 'Glass Bottle',
6: 'Cardboard', 7: 'Basketball', 8: 'Paper', 9: 'Metalware', 10: 'Disposable Chopsticks',
11: 'Lighter', 12: 'Broom', 13: 'Old Mirror', 14: 'Toothbrush', 15: 'Dirty Cloth', 16: 'Seashell',
17: 'Ceramic Bowl', 18: 'Paint bucket', 19: 'Battery', 20: 'Fluorescent lamp', 21: 'Tablet capsules',
22: 'Orange Peel', 23: 'Vegetable Leaf', 24: 'Eggshell', 25: 'Banana Peel'
}
# 全局,加载模型,避免每一次都加载浪费时间
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_1 = timm.create_model('seresnext50_32x4d.racm_in1k', pretrained=False)
model_1.fc = nn.Linear(model_1.num_features, 26)
model_1.load_state_dict(torch.load('model_sere.pth', map_location=device)['state_dict'])
model_1 = model_1.to(device)
model_2 = timm.create_model('seresnext50_32x4d.racm_in1k', pretrained=False)
model_2.fc = nn.Linear(model_2.num_features, 26)
model_2.load_state_dict(torch.load('model2.pth', map_location=device)['state_dict'])
model_2 = model_2.to(device)
def predict(image):
# 如果输入是numpy数组,转换为PIL Image
if isinstance(image, np.ndarray):
image = Image.fromarray(image)
# 确保图像是RGB模式
if image.mode != 'RGB':
image = image.convert('RGB')
image = Image.fromarray(np.array(image)[:, :, ::-1])
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 这个是imagenet的均值和方差
])
imgs = transform(image).unsqueeze(0).to(device)
model_1.eval()
model_2.eval()
tta_model_1 = tta.ClassificationTTAWrapper(model_1, tta.aliases.flip_transform(), merge_mode='mean')
tta_model_2 = tta.ClassificationTTAWrapper(model_2, tta.aliases.flip_transform(), merge_mode='mean')
with torch.no_grad():
logits_1 = tta_model_1(imgs.to(device)) #预测
logits_2 = tta_model_2(imgs.to(device))
logits = logits_1 + logits_2
return inverted[logits.argmax(dim=-1).cpu().numpy().item()]
# 之后整理一下再放
感想 ¶
训练比较耗时间,测试也很耗时间 大概搞了3天左右(包括树叶分类的作业)
口罩检测 ¶
口罩这个还是一个分类的任务,和垃圾分类其实是一个题目。
感觉还是设计隐含层网络架构比较关键。小数据集,数据增强也是比较关键的。
可惜作业截止了以后就不可以反复提交了,不然想试试一些其他的方法。
额外找的一些资料
之前想到的一个方法是,在网上找一些大的数据集进行训练,应用在小的数据集上面应该没有问题。但是试了一次发现效果不是很好,没有仔细研究这个问题,有兴趣的同学可以顺着这个思路研究一下。
X-zhangyang/Real-World-Masked-Face-Dataset: Real-World Masked Face Dataset,口罩人脸数据集
根据这篇的介绍,我们可以了解到口罩数据集分为两大类:一类是真实采集的人脸戴口罩图片,另一类是给无口罩的人脸图片加上了口罩的图片,造出的一些口罩的数据。
[2003.09093] Masked Face Recognition Dataset and Application
NKU-share/ 人工智能导论 at b60b98043f55257e1e74fc1aa1b7fc5ccbead370 · Starlight0798/NKU-share
作家风格识别 ¶
bert-base-chinese 模型离线使用案例 -CSDN 博客
解决 BERT 模型 bert-base-chinese 报错(无法自动联网下载)_ 国内下载 bert-base-chinese-CSDN 博客
google-bert/bert-base-chinese at main
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer
# 通过torch.hub(pytorch中专注于迁移学的工具)获得已经训练好的bert-base-chinese模型
# model = torch.hub.load('huggingface/pytorch-transformers', 'model', 'bert-base-chinese')
model = BertModel.from_pretrained('D:\\MyPython\\data\\bert-base-chinese')
# 获得对应的字符映射器, 它将把中文的每个字映射成一个数字
# tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', 'bert-base-chinese')
tokenizer = BertTokenizer.from_pretrained('D:\\MyPython\\data\\bert-base-chinese')
nll_loss_forward_reduce_cuda_kernel_2d: Assertion t >= 0 && t < n__classes failed.
../aten/src/ATen/native/cuda/Loss.cu:271: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [26,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:271: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [27,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:271: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [28,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:271: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [29,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:271: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [30,0,0] Assertion `t >= 0 && t < n_classes` failed.
../aten/src/ATen/native/cuda/Loss.cu:271: nll_loss_forward_reduce_cuda_kernel_2d: block: [0,0,0], thread: [31,0,0] Assertion `t >= 0 && t < n_classes` failed.
Test Iter: 140/ 143. Data: 0.313s. Batch: 0.342s. Loss: 3.9630. top1: 6.09. top5: 22.77. : 98%|█████████▊| 140/143 [00:56<00:01, 2.48it/s]
Traceback (most recent call last):
File "./train.py", line 533, in <module>
main()
File "./train.py", line 314, in main
train(args, labeled_trainloader, unlabeled_trainloader, test_loader,
File "./train.py", line 450, in train
test_loss, test_acc = test(args, test_loader, test_model, epoch)
File "./train.py", line 508, in test
losses.update(loss.item(), inputs.shape[0])
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.