06 | CNN 卷积神经网络 ¶
约 682 个字 预计阅读时间 3 分钟
神经网络:逼近任何一种概率模型,似然值最大
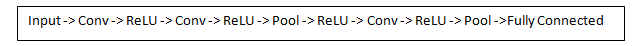
NUMPY
axis = 0 竖轴
axis = 1 横轴
卷积 ¶
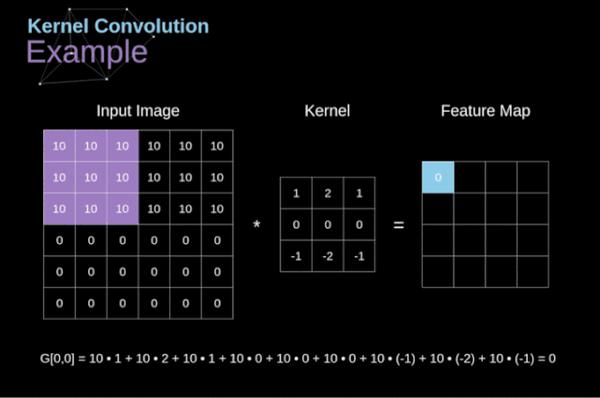
卷积核 ¶
feature 在 CNN 中也被成为卷积核(filter
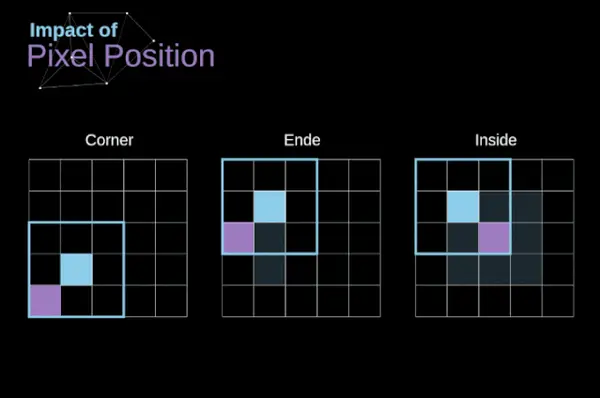
步长 ¶
stride
在设计 CNN 架构时,如果希望感知区域的重叠更少,或者希望 feature map 的空间维度更小,我们可以决定增加步幅。输出矩阵的尺寸——考虑到填充宽度和步幅——可以使用以下公式计算。
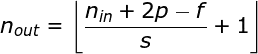
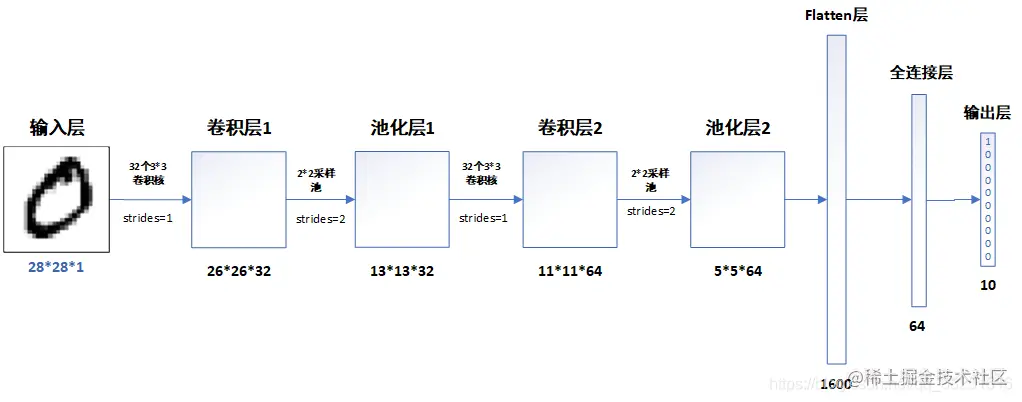
特征图 ¶
激活函数 ¶
最大熵原理
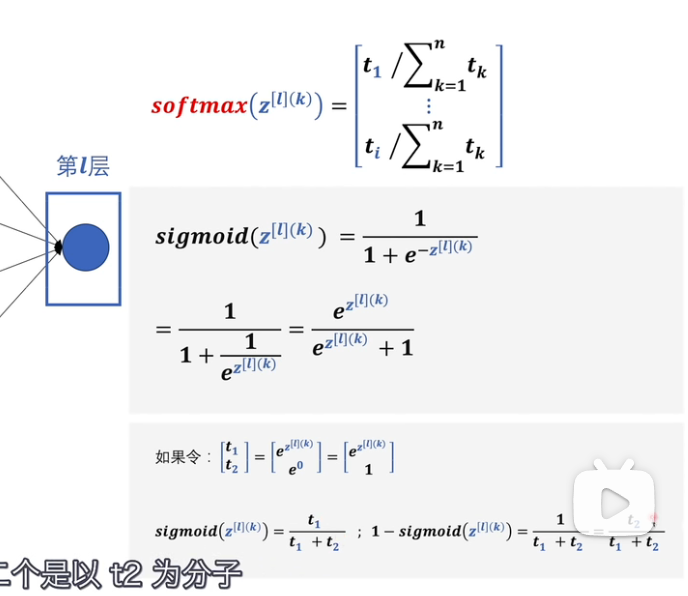
sigmoid¶
转换到 0-1
ReLU¶
Rectified Linear Unit
在神经网络中用到最多的非线性激活函数是 Relu 函数,它的公式定义如下:
f(x)=max(0,x)
leaky ReLU: f(x) = axquad x < 0 ; x for x>>0
Tanh¶
linear function¶
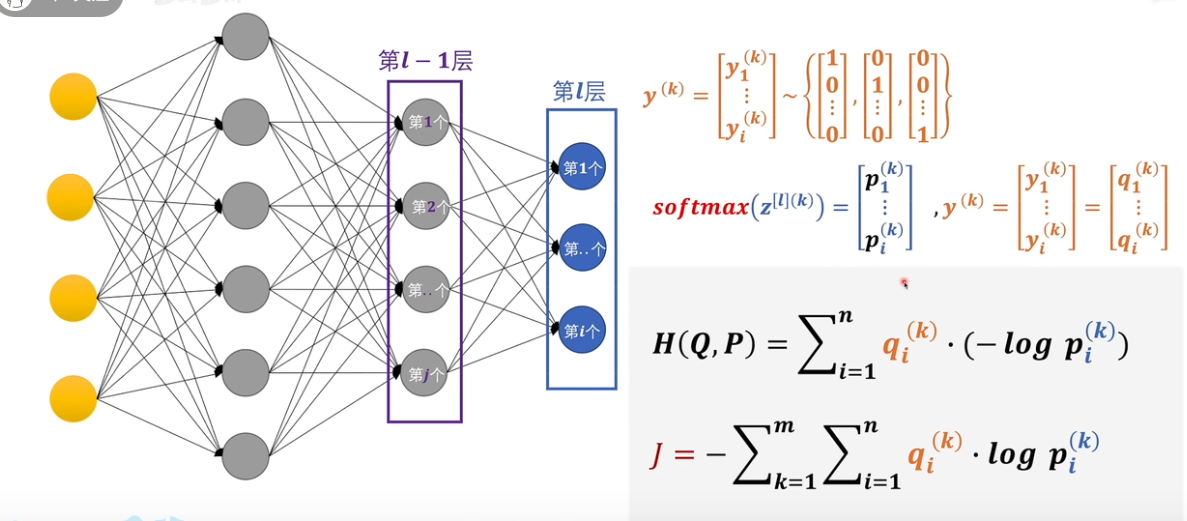
损失函数 loss function/objective function/cost function ¶
交叉熵 ¶
池化层 ¶
Max Pooling 最大池化、
Average Pooling 平均池化
全连接层 ¶
它最大的目的是对特征图进行维度上的改变,来得到每个分类类别对应的概率值。
局部连接
*“参数共享” ,*参数指的就是 filter
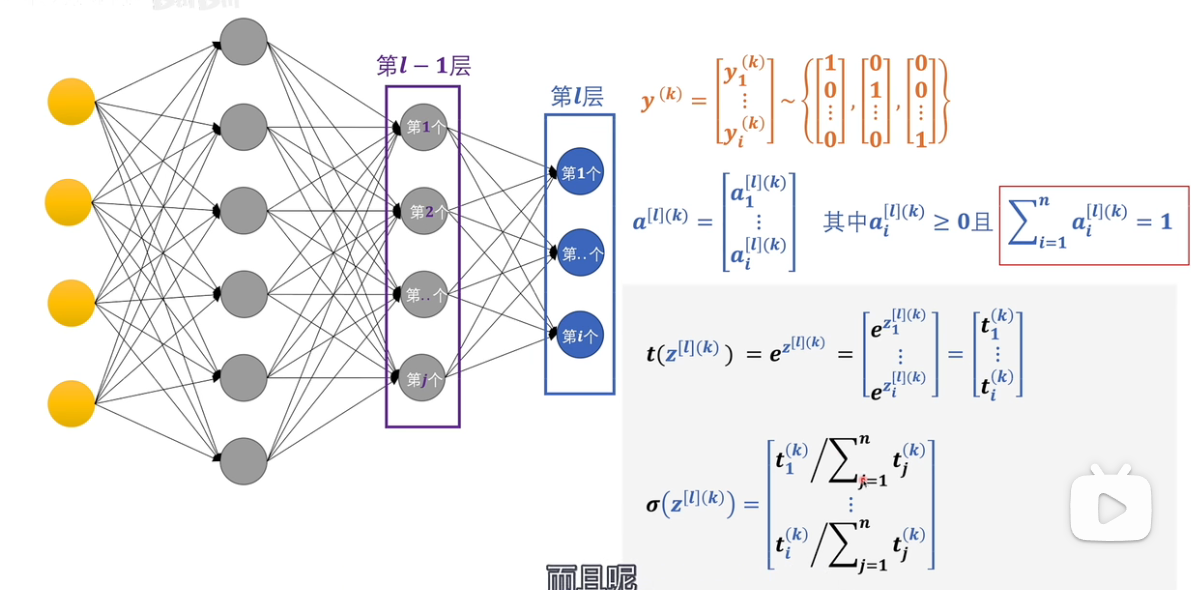
softmax¶
logits: the values z inputted to the softmax layer 缺点:数值溢出
训练 ¶
\(\theta\) represents all the perameters needed to be trained
training is seen as one of the most challanging jobs
- mini-batch: 计算所有 Loss_i(theta) 很耗时,所以使用 mini-batch gradient descent
- stochastic gradient descent
- gradient descent with momentum
- nesterov accelerated momentum
- adam:adapative moment estimation
- vanishing gradient problem: gradient is too large or too small¶
BackProp 反向传播算法 ¶
* 梯度下降法 *
定义优化器
超参数设置 ¶
hyper parameter tuning
- learning rate(initial,decay schedule)
- number of layers , nujmber of neurons per layer
- optimizer type
- regularization parameters(l2 penalty , dropout rate)
- batch size
- activation functions
- loss function
- grid search
- random search
- bayesian hyper-parameter optimizetion
- ensemble learning
deep nn perform better than shallow nn
generalization¶
- regularization : weight decay 正则化,让模型更简单
- dropout : introduce randomness during training
combine weak model into strong models
- early stopping :stop when the validation accuracy has not improved after n epochs(n is called patience)
- normize
Residual CNNs¶
Introduce “identity” skip connections o Layer inputs are propagated and added to the layer output o Mitigate the problem of vanishing gradients during training o Allow training very deep NN (with over 1,000 layers) § Several ResNet variants exist: 18, 34, 50, 101, 152, and 200 layers § Are used as base models of other state-of-the-art NNs o Other similar models: ResNeXT, DenseNet
学习资源 ¶
什么是卷积神经网络 CNN
卷积神经网络 CNN 完全指南终极版(一) - 知乎 (zhihu.com)
卷积神经网络 CNN 完全指南终极版(二) - 知乎 (zhihu.com)
解析深入浅出,卷积神经网络数学原理如此简单! - 知乎 (zhihu.com)
softmax 是为了解决归一问题凑出来的吗?和最大熵是什么关系?最大熵对机器学习为什么非常重要?_ 哔哩哔哩 _bilibili